ecmnmle
Mean and covariance of incomplete multivariate normal data
Syntax
Description
ecmnmle( with no output arguments,
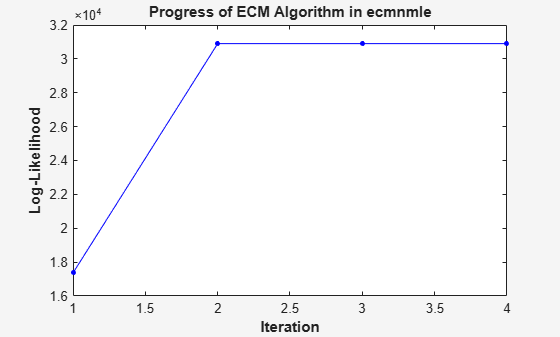
this mode displays the convergence of the ECM algorithm in a plot by estimating
objective function values for each iteration of the ECM algorithm until termination. Data)
[
estimates the mean and covariance of a data set (Mean,Covariance] = ecmnmle(Data)Data). If the
data set has missing values, this routine implements the ECM algorithm of Meng and
Rubin [2] with enhancements by Sexton and Swensen [3]. ECM stands for a conditional
maximization form of the EM algorithm of Dempster, Laird, and Rubin [4].
[
adds an optional arguments for Mean,Covariance] = ecmnmle(___,InitMethod,MaxIterations,Tolerance,Mean0,Covar0)InitMethod,
MaxIterations,
Tolerance,Mean0, and
Covar0.
Examples
This example shows how to compute the mean and covariance of incomplete multivariate normal data for five years of daily total return data for 12 computer technology stocks, with six hardware and six software companies
load ecmtechdemo.matThe time period for this data extends from April 19, 2000 to April 18, 2005. The sixth stock in Assets is Google (GOOG), which started trading on August 19, 2004. So, all returns before August 20, 2004 are missing and represented as NaNs. Also, Amazon (AMZN) had a few days with missing values scattered throughout the past five years.
ecmnmle(Data)
ans = 12×1
0.0008
0.0008
-0.0005
0.0002
0.0011
0.0038
-0.0003
-0.0000
-0.0003
-0.0000
-0.0003
0.0004
This plot shows that, even with almost 87% of the Google data being NaN values, the algorithm converges after only four iterations.
[Mean,Covariance] = ecmnmle(Data)
Mean = 12×1
0.0008
0.0008
-0.0005
0.0002
0.0011
0.0038
-0.0003
-0.0000
-0.0003
-0.0000
-0.0003
0.0004
Covariance = 12×12
0.0012 0.0005 0.0006 0.0005 0.0005 0.0003 0.0005 0.0003 0.0006 0.0003 0.0005 0.0006
0.0005 0.0024 0.0007 0.0006 0.0010 0.0004 0.0005 0.0003 0.0006 0.0004 0.0006 0.0012
0.0006 0.0007 0.0013 0.0007 0.0007 0.0003 0.0006 0.0004 0.0008 0.0005 0.0008 0.0008
0.0005 0.0006 0.0007 0.0009 0.0006 0.0002 0.0005 0.0003 0.0007 0.0004 0.0005 0.0007
0.0005 0.0010 0.0007 0.0006 0.0016 0.0006 0.0005 0.0003 0.0006 0.0004 0.0007 0.0011
0.0003 0.0004 0.0003 0.0002 0.0006 0.0022 0.0001 0.0002 0.0002 0.0001 0.0003 0.0016
0.0005 0.0005 0.0006 0.0005 0.0005 0.0001 0.0009 0.0003 0.0005 0.0004 0.0005 0.0006
0.0003 0.0003 0.0004 0.0003 0.0003 0.0002 0.0003 0.0005 0.0004 0.0003 0.0004 0.0004
0.0006 0.0006 0.0008 0.0007 0.0006 0.0002 0.0005 0.0004 0.0011 0.0005 0.0007 0.0007
0.0003 0.0004 0.0005 0.0004 0.0004 0.0001 0.0004 0.0003 0.0005 0.0006 0.0004 0.0005
0.0005 0.0006 0.0008 0.0005 0.0007 0.0003 0.0005 0.0004 0.0007 0.0004 0.0013 0.0007
0.0006 0.0012 0.0008 0.0007 0.0011 0.0016 0.0006 0.0004 0.0007 0.0005 0.0007 0.0020
Input Arguments
Output Arguments
Algorithms
References
[1] Little, Roderick J. A. and Donald B. Rubin. Statistical Analysis with Missing Data. 2nd Edition. John Wiley & Sons, Inc., 2002.
[2] Meng, Xiao-Li and Donald B. Rubin. “Maximum Likelihood Estimation via the ECM Algorithm.” Biometrika. Vol. 80, No. 2, 1993, pp. 267–278.
[3] Sexton, Joe and Anders Rygh Swensen. “ECM Algorithms that Converge at the Rate of EM.” Biometrika. Vol. 87, No. 3, 2000, pp. 651–662.
[4] Dempster, A. P., N. M. Laird, and Donald B. Rubin. “Maximum Likelihood from Incomplete Data via the EM Algorithm.” Journal of the Royal Statistical Society. Series B, Vol. 39, No. 1, 1977, pp. 1–37.
Version History
Introduced before R2006a