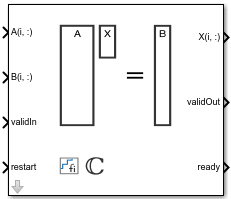
Complex Burst Matrix Solve Using QR Decomposition
Compute the value of x in the equation Ax = B for complex-valued matrices using QR decomposition
Libraries:
Fixed-Point Designer HDL Support /
Matrices and Linear Algebra /
Linear System Solvers
Description
The Complex Burst Matrix Solve Using QR Decomposition block solves the system of linear equations Ax = B using QR decomposition, where A and B are complex-valued matrices. To compute x = A-1, set B to be the identity matrix.
When Regularization parameter is nonzero, the
Complex Burst Matrix Solve Using QR Decomposition block computes the matrix
solution of complex-valued where λ is the regularization parameter,
A is an m-by-n matrix,
p is the number of columns in B,
In =
eye(n), and
0n,p =
zeros(n,p).
Examples
Implement Hardware-Efficient Complex Burst Matrix Solve Using QR Decomposition
How to use the Complex Burst Matrix Solve Using QR Decomposition block.
Implement Hardware-Efficient Complex Burst Matrix Solve Using QR Decomposition with Tikhonov Regularization
Use the Complex Burst Matrix Solve Using QR Decomposition block to solve the regularized least-squares matrix equation
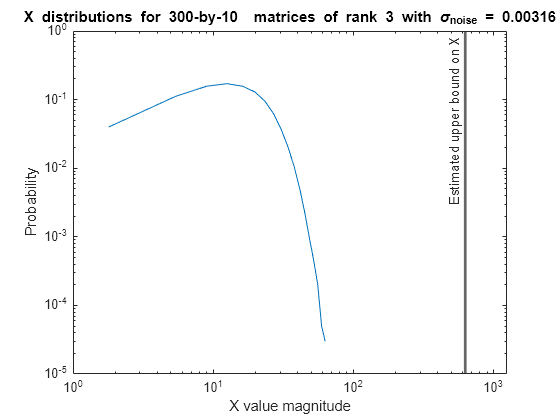
Algorithms to Determine Fixed-Point Types for Complex Least-Squares Matrix Solve AX=B
Derivation of algorithms for determining fixed-point types for complex QR matrix solve.
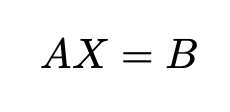
Determine Fixed-Point Types for Complex Least-Squares Matrix Solve AX=B
Use fixed.complexQRFixedpointTypes to determine fixed-point types
for computation of the complex least-squares matrix equation.
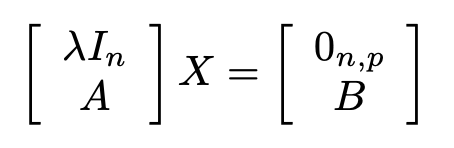
Determine Fixed-Point Types for Complex Least-Squares Matrix Solve with Tikhonov Regularization
Use the fixed.complexQRMatrixSolveFixedpointTypes function to analytically determine fixed-point types for the solution of the complex least-squares matrix equation
Ports
Input
Output
Parameters
Tips
Use fixed.getMatrixSolveModel(A,B) to generate a template model
containing a Complex Burst Matrix Solve Using QR Decomposition block for
complex-valued input matrices A and B.
Algorithms
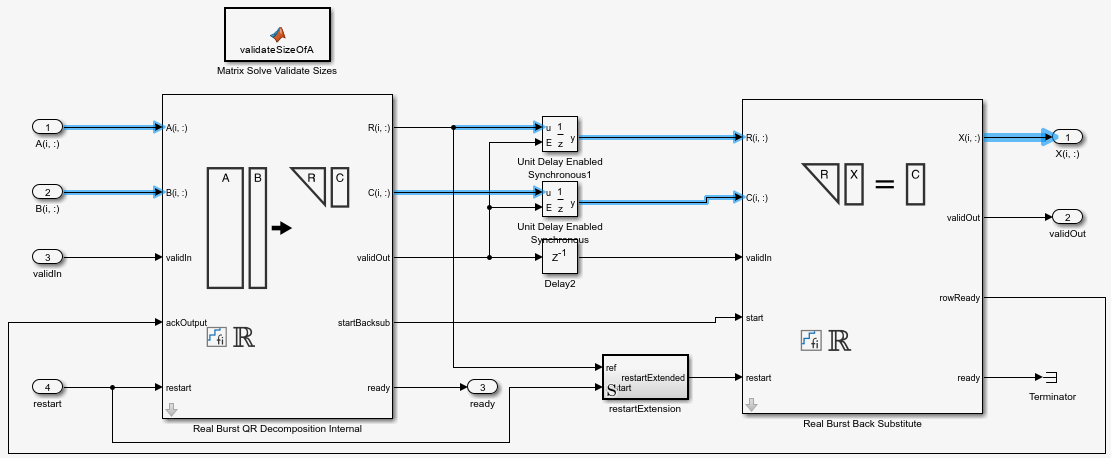
The Matrix Solve Using QR Decomposition blocks operate synchronously. These blocks first decompose the input A and B matrices into R and C matrices using a QR decomposition block. Then, a back substitute block computes RX = C. The input A and B matrices propagate through the system in parallel, in a synchronized way.
The Matrix Solve Using Q-less QR Decomposition blocks operate asynchronously. First, Q-less QR decomposition is performed on the input A matrix and the resulting R matrix is put into a buffer. Then, a forward backward substitution block uses the input B matrix and the buffered R matrix to compute R'RX = B. Because the R and B matrices are stored separately in buffers, the upstream Q-less QR decomposition block and the downstream Forward Backward Substitute block can run independently. The Forward Backward Substitute block starts processing when the first R and B matrices are available. Then it runs continuously using the latest buffered R and B matrices, regardless of the status of the Q-less QR Decomposition block. For example, if the upstream block stops providing A and B matrices, the Forward Backward Substitute block continues to generate the same output using the last pair of R and B matrices.
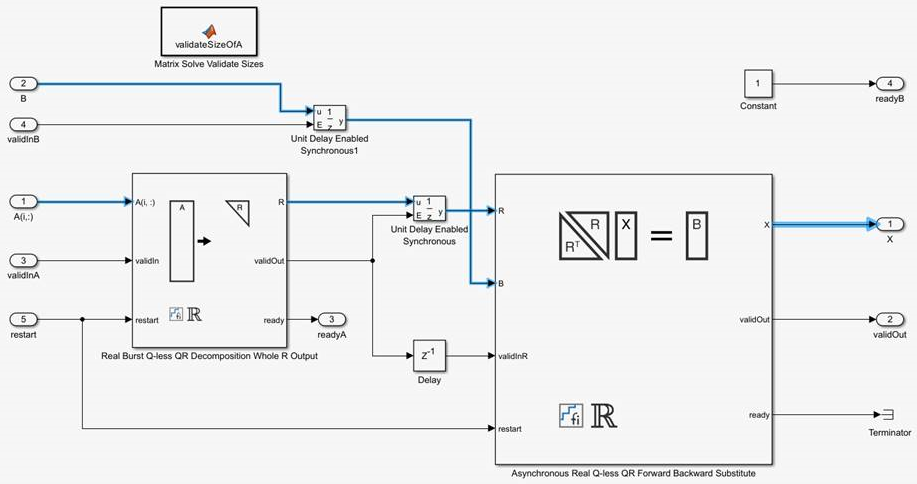
The Burst (Asynchronous) Matrix Solve Using Q-less QR Decomposition blocks are available in both synchronous and asynchronous operation variants, as denoted by the block name.
The Burst Matrix Solve Using QR Decomposition blocks accept and process A and B matrices row by row synchronously. After accepting m rows, the block outputs the X matrix row by row continuously. The matrix is output from the first row to the last row.
For example, assume that the input A and B
matrices are 3-by-3. Additionally assume that validIn asserts before
ready, meaning that the upstream data source is faster than the QR
decomposition.
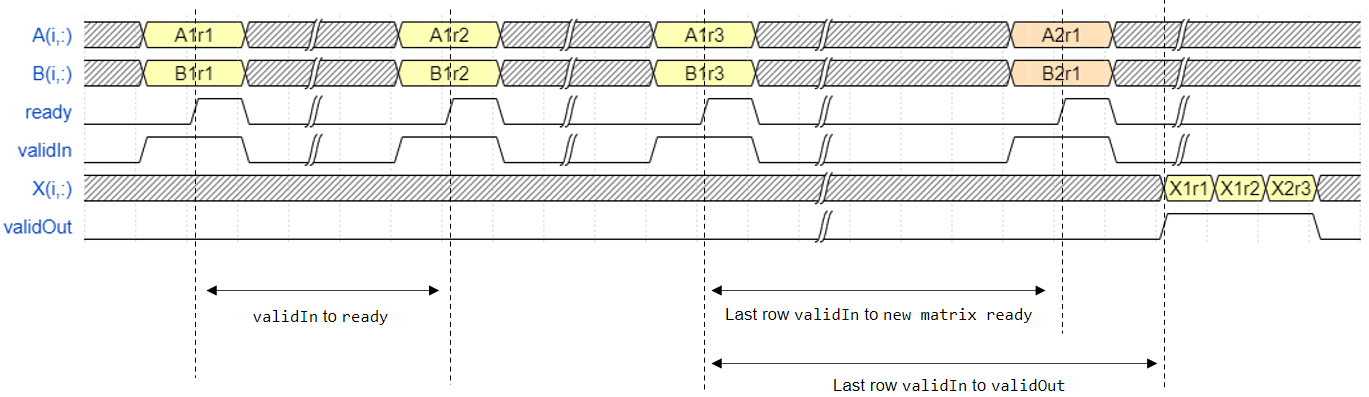
In the figure,
A1r1is the first row of the first A matrix,X1r3is the third row of the first X matrix, and so on.validIntoready— From a successful row input to the block being ready to accept the next row within one matrix.Last row
validIntovalidOut— From the last row input to the block starting to output the solution.Last row
validInto new matrix ready — From the block starting to output the solution to the block ready to accept the next matrix input.
The following table provides details of the timing for the Complex Burst Matrix Solve Using QR Decomposition block. Latency depends on the size of matrix A and the data types of the A and B matrices. In the table:
n is the number of columns in matrix A.
wl represents the word length of the input data. If the data types of A and B are fixed point or scaled double
fi, then wl is given bymax(A.WordLength + ~issigned(A), B.WordLength + ~issigned(B)).
| Input Data Type | validIn to ready (cycles) | Last Row validIn to validOut
(cycles) | Last row validIn to new matrix ready (cycles) |
|---|---|---|---|
Fixed point fi | (wl*2 + 11)*n + 2 | (wl*2 + 11)*n + 3.5*n2 + n*(nextpow2(wl) + wl + 8.5) + 3 | (wl*2 + 11)*n + 3.5*(n-1)2 + (n-1)(nextpow2(wl) + wl + 8.5) + 3 |
Scaled double fi | (wl*2 + 11)*n + 2 | 3.5*n2 + (3*wl + 18.5)*n + 3 | (wl*2 + 11)*n + 3.5*(n - 1)2 + (n - 1)*(7.5 + wl) + 3 |
double | 117*n + 2 | 3.5*n2 + 123.5*n + 3 | 3.5*n2 + 116.5*n |
single | 59*n + 2 | 3.5*n2 + 65.5*n + 3 | 3.5*n2 + 58.5*n |
References
[1] "AMBA AXI and ACE Protocol Specification Version E." https://developer.arm.com/documentation/ihi0022/e/