Call Custom CUDA Device Functions from Generated Code
This example shows how to incorporate external CUDA® code for a device function in the generated code for a stereo disparity algorithm. You can insert calls to custom CUDA device functions, which are functions that have the __device__ specifier, inside generated GPU code. Device functions execute on the GPU. Only global functions, also called kernels, or other device functions can call a device function. Integrate custom code when you have external libraries, optimized code, or object files that you want the generated code to use.
To call custom kernels in generated code, see Call Custom CUDA Kernels from the Generated Code.
Examine the Device Function
The cuda_intrinsic.h file defines the __usad4 function. The function implements the sum of the absolute differences between two inputs of the int type by using the vabsdiff instruction, which is optimized for the target hardware during compilation.
type cuda_intrinsic.h__device__ unsigned int __usad4(unsigned int A, unsigned int B, unsigned int C=0)
{
unsigned int result;
#if (__CUDA_ARCH__ >= 300) // Kepler (SM 3.x) supports a 4 vector SAD SIMD
asm("vabsdiff4.u32.u32.u32.add" " %0, %1, %2, %3;": "=r"(result):"r"(A),
"r"(B), "r"(C));
#else // SM 2.0 // Fermi (SM 2.x) supports only 1 SAD SIMD,
// so there are 4 instructions
asm("vabsdiff.u32.u32.u32.add" " %0, %1.b0, %2.b0, %3;":
"=r"(result):"r"(A), "r"(B), "r"(C));
asm("vabsdiff.u32.u32.u32.add" " %0, %1.b1, %2.b1, %3;":
"=r"(result):"r"(A), "r"(B), "r"(result));
asm("vabsdiff.u32.u32.u32.add" " %0, %1.b2, %2.b2, %3;":
"=r"(result):"r"(A), "r"(B), "r"(result));
asm("vabsdiff.u32.u32.u32.add" " %0, %1.b3, %2.b3, %3;":
"=r"(result):"r"(A), "r"(B), "r"(result));
#endif
return result;
}
__device__ unsigned int packBytes(const uint8_T *inBytes)
{
unsigned int packed = inBytes[0] | (inBytes[1] << 8) |
(inBytes[2] << 16) | (inBytes[3] << 24);
return packed;
}
__device__ unsigned int __usad4_wrap(const uint8_T *A, const uint8_T *B)
{
unsigned int x = packBytes(A);
unsigned int y = packBytes(B);
return __usad4(x, y);
}
To use the usad4 function, call the __usad_4wrap wrapper function in the generated code.
Integrate Device Function into MATLAB Code
Examine the stereoDisparity_cuda_sample function. The function accepts two input images and uses a nested for-loop to calculate a disparity map. To include the cuda_intrinsic.h file in the build, the function uses the coder.cinclude function.
type stereoDisparity_cuda_sample.mfunction [out_disp] = stereoDisparity_cuda_sample(img0,img1) %#codegen
% Copyright 2025 The MathWorks, Inc.
% GPU code generation pragma
coder.gpu.kernelfun;
coder.cinclude("cuda_intrinsic.h");
%% Stereo Disparity Parameters
% |WIN_RAD| is the radius of the window to be operated. |min_disparity| is
% the minimum disparity level the search continues for. |max_disparity| is
% the maximum disparity level the search continues for.
WIN_RAD = 8;
min_disparity = -16;
max_disparity = 0;
%% Image Dimensions for Loop Control
% The number of channels packed are 4 (RGBA) so as nChannels are 4.
[imgHeight,imgWidth]=size(img0);
nChannels = 4;
imgHeight = imgHeight/nChannels;
%% Store the Raw Differences
diff_img = zeros([imgHeight+2*WIN_RAD,imgWidth+2*WIN_RAD],'int32');
% Store the minimum cost
min_cost = zeros([imgHeight,imgWidth],'int32');
min_cost(:,:) = 99999999;
% Store the final disparity
out_disp = zeros([imgHeight,imgWidth],'int16');
%% Filters for Aggregating the Differences
% |filter_h| is the horizontal filter used in separable convolution.
% |filter_v| is the vertical filter used in separable convolution which
% operates on the output of the row convolution.
filt_h = ones([1 17],'int32');
filt_v = ones([17 1],'int32');
% Main Loop that runs for all the disparity levels. This loop is
% expected to run on CPU.
for d=min_disparity:max_disparity
% Find the difference matrix for the current disparity level. Expect
% this to generate a Kernel function.
coder.gpu.kernel;
for colIdx=1:imgWidth+2*WIN_RAD
coder.gpu.kernel;
for rowIdx=1:imgHeight+2*WIN_RAD
% Row index calculation.
ind_h = rowIdx - WIN_RAD;
% Column indices calculation for left image.
ind_w1 = colIdx - WIN_RAD;
% Row indices calculation for right image.
ind_w2 = colIdx + d - WIN_RAD;
% Border clamping for row Indices.
if ind_h <= 0
ind_h = 1;
end
if ind_h > imgHeight
ind_h = imgHeight;
end
% Border clamping for column indices for left image.
if ind_w1 <= 0
ind_w1 = 1;
end
if ind_w1 > imgWidth
ind_w1 = imgWidth;
end
% Border clamping for column indices for right image.
if ind_w2 <= 0
ind_w2 = 1;
end
if ind_w2 > imgWidth
ind_w2 = imgWidth;
end
% In this step, Sum of absolute Differences is performed
% across four channels.
tDiff = int32(0);
if coder.target("MATLAB")
for chIdx = 1:nChannels
tDiff = tDiff + abs(int32(img0((ind_h-1)*(nChannels)+...
chIdx,ind_w1))-int32(img1((ind_h-1)*(nChannels)+...
chIdx,ind_w2)));
end
else
tDiff = coder.ceval("-gpudevicefcn", "__usad4_wrap", ...
coder.rref(img0((ind_h-1)*(nChannels)+1,ind_w1)), ...
coder.rref(img1((ind_h-1)*(nChannels)+1,ind_w2)));
end
% Store the SAD cost into a matrix.
diff_img(rowIdx,colIdx) = tDiff;
end
end
% Aggregating the differences using separable convolution. Expect this
% to generate two kernels using shared memory.The first kernel is the
% convolution with the horizontal kernel and second kernel operates on
% its output the column wise convolution.
cost_v = conv2(diff_img,filt_h,'valid');
cost = conv2(cost_v,filt_v,'valid');
% This part updates the min_cost matrix with by comparing the values
% with current disparity level.
for ll=1:imgWidth
for kk=1:imgHeight
% load the cost
temp_cost = int32(cost(kk,ll));
% Compare against the minimum cost available and store the
% disparity value.
if min_cost(kk,ll) > temp_cost
min_cost(kk,ll) = temp_cost;
out_disp(kk,ll) = abs(d) + 8;
end
end
end
end
end
To call the device function into generated code, use the coder.ceval function inside a for-loop that GPU Coder™ maps to a GPU kernel. In this example, the function uses the coder.gpu.kernel pragma to map a loop to a kernel in the generated code, and the loop contains the coder.ceval function to call the device function.
coder.gpu.kernel; for rowIdx=1:imgHeight+2*WIN_RAD % Row index calculation. ind_h = rowIdx - WIN_RAD; % Column indices calculation for left image. ind_w1 = colIdx - WIN_RAD; % Row indices calculation for right image. ind_w2 = colIdx + d - WIN_RAD; % Border clamping for row Indices. if ind_h <= 0 ind_h = 1; end if ind_h > imgHeight ind_h = imgHeight; end % Border clamping for column indices for left image. if ind_w1 <= 0 ind_w1 = 1; end if ind_w1 > imgWidth ind_w1 = imgWidth; end % Border clamping for column indices for right image. if ind_w2 <= 0 ind_w2 = 1; end if ind_w2 > imgWidth ind_w2 = imgWidth; end % In this step, Sum of absolute Differences is performed % across four channels. tDiff = int32(0); if coder.target("MATLAB") for chIdx = 1:nChannels tDiff = tDiff + abs(int32(img0((ind_h-1)*(nChannels)+... chIdx,ind_w1))-int32(img1((ind_h-1)*(nChannels)+... chIdx,ind_w2))); end else tDiff = coder.ceval("-gpudevicefcn", "__usad4_wrap", ... coder.rref(img0((ind_h-1)*(nChannels)+1,ind_w1)), ... coder.rref(img1((ind_h-1)*(nChannels)+1,ind_w2))); end % Store the SAD cost into a matrix. diff_img(rowIdx,colIdx) = tDiff; end
When you generate code, GPU Coder inserts the call to the device function inside the kernel for the loop.
The function uses the coder.target function to detect whether the you are running the code in MATLAB. When you execute stereoDisparity_cuda_sample in MATLAB, it uses a loop to calculate the sum of absolute differences.
for chIdx = 1:nChannels tDiff = tDiff + abs(int32(img0((ind_h-1)*(nChannels)+... chIdx,ind_w1))-int32(img1((ind_h-1)*(nChannels)+... chIdx,ind_w2))); end
For code generation, the function uses the coder.ceval function with the "-gpudevicefcn" argument to call the __usad4_wrap device function.
else tDiff = coder.ceval("-gpudevicefcn", "__usad4_wrap", ... coder.rref(img0((ind_h-1)*(nChannels)+1,ind_w1)), ... coder.rref(img1((ind_h-1)*(nChannels)+1,ind_w2))); end
Load Input Data
To generate code from the stereoDisparity_cuda_sample function, first load two images to use as input data. The images scene_left.png and scene_right.png show two similar images of three armchairs around two tables.
imgRGB0 = imread("scene_left.png"); imgRGB1 = imread("scene_right.png"); imshow(imgRGB0)

imshow(imgRGB1)

Use the pack_rgbData helper function to pack the images in a column-major format with an RGBA order.
imgRGB0 = pack_rgbData(imgRGB0); imgRGB1 = pack_rgbData(imgRGB1);
Generate CUDA Code
To generate CUDA code, create a GPU code configuration object by using the coder.gpuConfig function. Set the CustomInclude property of the configuration object to include the current working directory during the build.
cfg = coder.gpuConfig("mex");
cfg.CustomInclude = pwd;Generate CUDA code by using the codegen command.
codegen -config cfg -args {imgRGB0, imgRGB1} stereoDisparity_cuda_sample;
Code generation successful: To view the report, open('codegen\mex\stereoDisparity_cuda_sample\html\report.mldatx')
Run the Generated Code
In the stereoDisparity_cuda_sample.cu file, the code calls the __usad4_wrap function.
codePath = fullfile("codegen","mex","stereoDisparity_cuda_sample","stereoDisparity_cuda_sample.cu"); coder.example.extractLines(codePath,"In this step","Store the SAD cost")
// In this step, Sum of absolute Differences is performed
// across four channels.
ind_h = (ind_h - 1) << 2;
diff_img[rowIdx + 300 * colIdx] = __usad4_wrap(
&img0[ind_h + 1136 * (ind_w1 - 1)], &img1[ind_h + 1136 * (ind_w2 - 1)]);
Call the generated MEX function on the two input images.
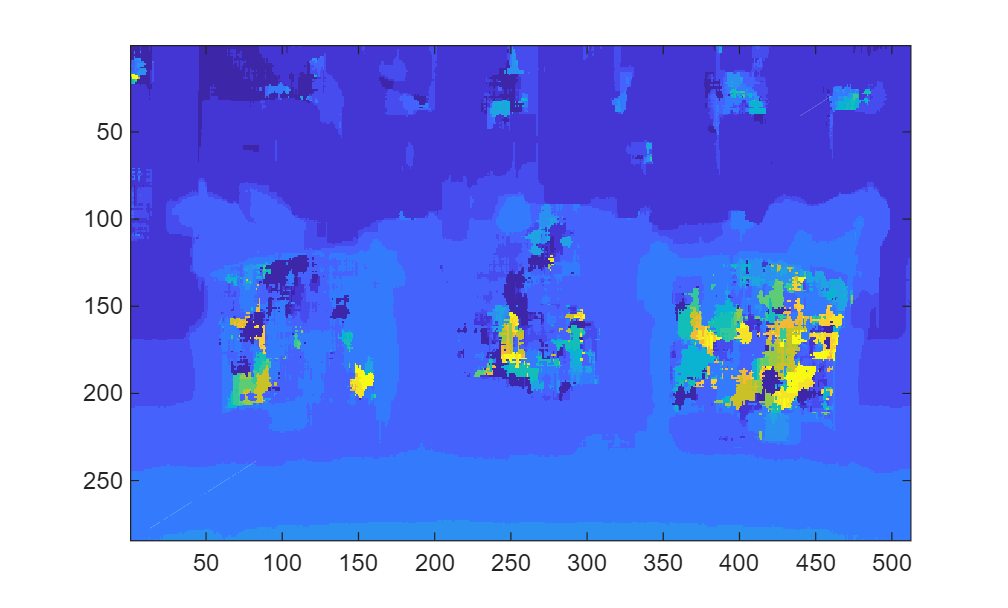
outImage = stereoDisparity_cuda_sample_mex(imgRGB0,imgRGB1); imagesc(outImage)
Helper Functions
The pack_rgbData function packs the image data in column-major format and in RGBA order.
type pack_rgbData.m%% Pack data to RGBA format
% Copyright 2017-2021 The MathWorks, Inc.
function [outRGB] = pack_rgbData(img)
% Extract the image parameters
[rows,cols,nChannels] = size(img);
% Initialize the output matrix
outRGB = zeros([rows*(nChannels+1),cols],'uint8');
%% Perform the RGBA column major packing
for rowidx=1:rows
for colidx=1:cols
%Copy the RGB
for ch=1:nChannels
outRGB((rowidx-1)*(nChannels+1)+ch,colidx) = img(rowidx,colidx,ch);
end
% Zero the Alpha channel when it is not available
outRGB((rowidx-1)*(nChannels+1)+4,colidx) = 0;
end
end
end