dissect
Nested dissection permutation
Description
p = dissect(A,Name,Value)dissect(A,'NumIterations',15) uses 15 refinement
iterations in the nested dissection algorithm instead of 10.
Examples
Reorder a sparse matrix with several methods and compare the fill-in incurred by the LU decomposition of the reordered matrices.
Load the west0479 matrix, which is a real-valued 479-by-479 sparse matrix with both real and complex pairs of conjugate eigenvalues. View the sparsity structure.
load west0479.mat
A = west0479;
spy(A)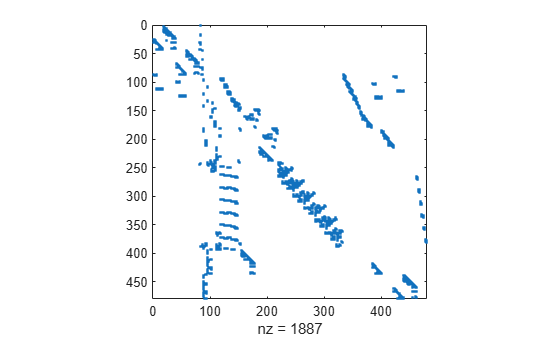
Calculate several different permutations of the matrix columns, including the nested dissection ordering.
p1 = dissect(A); p2 = amd(A); p3 = symrcm(A);
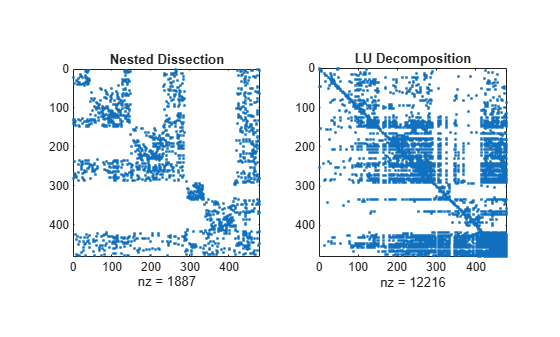
Compare the sparsity structures of the LU decomposition of A using the different ordering methods. The dissect function produces the reordering that incurs the least amount of fill-in.
subplot(1,2,1) spy(A) title('Original Matrix') subplot(1,2,2) spy(lu(A)) title('LU Decomposition')
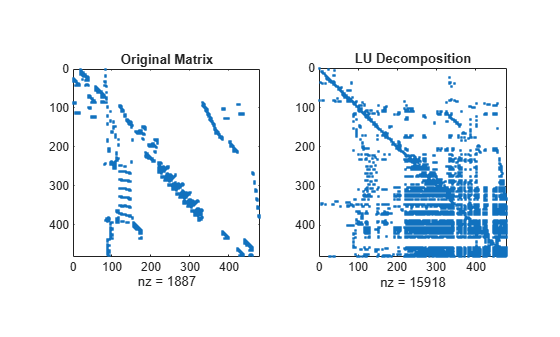
figure subplot(1,2,1) spy(A(p3,p3)) title('Reverse Cuthill-McKee') subplot(1,2,2) spy(lu(A(p3,p3))) title('LU Decomposition')
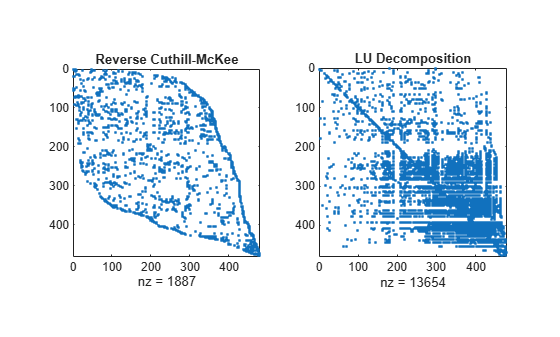
figure subplot(1,2,1) spy(A(p2,p2)) title('Approximate Minimum Degree') subplot(1,2,2) spy(lu(A(p2,p2))) title('LU Decomposition')
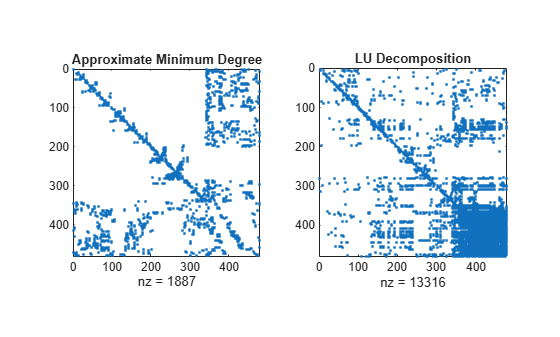
figure subplot(1,2,1) spy(A(p1,p1)) title('Nested Dissection') subplot(1,2,2) spy(lu(A(p1,p1))) title('LU Decomposition')
An arrowhead matrix is a sparse matrix that has a few dense columns. Use the 'MaxDegreeThreshold' name-value pair to filter the dense columns to the end of the reordered matrix.
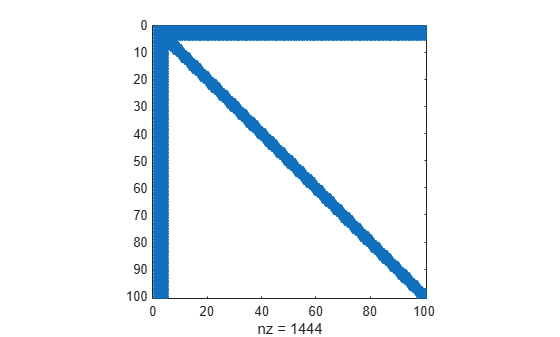
Create an arrowhead sparse matrix and view the sparsity pattern.
A = speye(100) + diag(ones(1,99),1) + diag(ones(1,98),2); A(1:5,:) = ones(5,100); A = A + A'; spy(A)
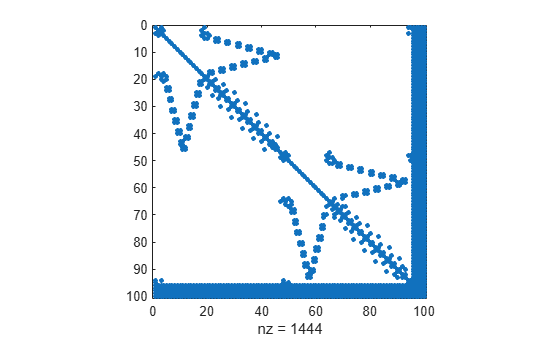
Calculate the nested dissection ordering, and filter out the columns that have more than 10 nonzero elements.
p = dissect(A,'MaxDegreeThreshold',10);View the sparsity pattern of the reordered matrix. dissect places the dense columns at the end of the reordered matrix.
spy(A(p,p))
Input Arguments
Name-Value Arguments
Output Arguments
Algorithms
The nested dissection ordering algorithm described in [1] is a multilevel graph partitioning algorithm that is used to produce fill-reducing orderings of sparse matrices. The input matrix is treated as the adjacency matrix of a graph. The algorithm coarsens the graph by collapsing vertices and edges, reorders the smaller graph, and then uses refinement steps to uncoarsen the small graph and produce a reordering of the original graph.
The name-value pairs for dissect enable you to control various
stages of the algorithm:
Coarsening
In this phase, the algorithm creates successively smaller graphs from the original graph by collapsing together adjacent pairs of vertices.
'MaxDegreeThreshold'enables you to filter out highly connected graph vertices (which are dense columns in the matrix) by ordering them last.Partitioning
After the graph is coarsened, the algorithm completely reorders the smaller graph. At each partitioning step, the algorithm attempts to partition the graph into equal parts:
'NumSeparators'specifies how many parts to partition the graph into,'VertexWeights'optionally assigns weights to the vertices, and'MaxImbalance'specifies the threshold for the difference in weight between the different partitions.Refinement
After the smallest graph is reordered, the algorithm makes projections to enlarge the graph back to the original size by expanding the vertices that were previously combined. After each projection step, a refinement step is performed that moves vertices between partitions to improve the quality of the solution.
'NumIterations'controls how many refinement steps are used during this uncoarsening phase.
References
[1] Karypis, George and Vipin Kumar. "A Fast and High Quality Multilevel Scheme for Partitioning Irregular Graphs." SIAM Journal on Scientific Computing. Vol. 20, Number 1, 1999, pp. 359–392.
Extended Capabilities
Version History
Introduced in R2017b