Profiling Load Unbalanced Codistributed Arrays
This example shows how to profile the implicit communication that occurs when using an unevenly distributed array. For getting started with parallel profiling, see Profiling Parallel Code.
This example shows how to use the parallel profiler in the case of an unevenly distributed array. The easiest way to create a codistributed array is to pass a codistributor as an argument, such as in rand(N, codistributor). This evenly distributes your matrix of size N between your MATLAB® workers. To get an unbalanced data distribution, you can get some number of columns of a codistributed array as a function of spmdIndex.
The data transfer plots in this example are produced using a local cluster with 12 workers. Everything else is shown running on a local cluster with 4 workers.
The Algorithm
The algorithm we chose for this codistributed array is relatively simple. We generate a large matrix such that each lab gets an approximately 512-by-512 submatrix, except for the first lab. The first lab receives only one column of the matrix and the other columns are assigned to the last lab. Thus, on a four-lab cluster, lab 1 keeps only a 1-by-512 column, labs 2 and 3 have their allotted partitions, and lab 4 has its allotted partition plus the additional columns (left over from lab 1). The end result is an unbalanced workload when doing zero communication element-wise operations (such as sin) and communication delays with data parallel operations (such as codistributed/mtimes). We start with a data parallel operation first (codistributed/mtimes). We then perform, in a loop, sqrt, sin, and inner product operations, all of which only operate on individual elements of the matrix.
The MATLAB file code for this example can be found in: pctdemo_aux_profdistarray
In this example, the size of the matrix differs depending on the number of MATLAB workers (spmdSize). However, it takes approximately the same amount of computation time (not including communication) to run this example on any cluster, so you can try using a larger cluster without having to wait a long time.
spmd spmdBarrier; % synchronize all the labs mpiprofile reset mpiprofile on pctdemo_aux_profdistarray(); end
Worker 1: This lab has 1024 rows and 1 columns of a codistributed array Worker 2: This lab has 1024 rows and 256 columns of a codistributed array Worker 3: This lab has 1024 rows and 256 columns of a codistributed array Worker 4: This lab has 1024 rows and 511 columns of a codistributed array Worker 1: Calling mtimes on codistributed arrays Calling embarrassingly parallel math functions (i.e. no communication is required) on a codistributed array. Done Worker 2: Calling mtimes on codistributed arrays Calling embarrassingly parallel math functions (i.e. no communication is required) on a codistributed array. Done Worker 3: Calling mtimes on codistributed arrays Calling embarrassingly parallel math functions (i.e. no communication is required) on a codistributed array. Done Worker 4: Calling mtimes on codistributed arrays Calling embarrassingly parallel math functions (i.e. no communication is required) on a codistributed array. Done
mpiprofile viewerFirst, browse the Parallel Profile Summary, making sure it is sorted by the execution time by clicking the Total Time column. Then follow the link for the function pctdemo_aux_profdistarray to see the Function Detail Report.
The Busy Line Table in the Function Detail Report
Each MATLAB function entry has its own Busy lines table, which is useful if you want to profile multiple programs or examples at the same time.
In the Function Detail Report, observe the communication information for the executed MATLAB code on a line-by-line basis.
To compare profiling information, click the Busy Lines button in the View section of the app toolstrip. In the Compare section of the toolstrip, click the Max vs. Min Total Time button and choose the numbers of the workers you want to compare in the Go to worker and Compare with menus. Observe the Busy lines table and check to see which line numbers took the most time. There are no for-loops in this code and no increasing complexity. However, there still is a large difference in computation load between the labs. Look at line 35, which contains the code
sqrt( sin( D .* D ) );.

Despite the fact that no communication is required for this element-wise operation, the performance is not optimal, because some labs do more work than others. In the second row, (D*D*D), the total time taken is the same on both labs. However, the Data Received and Data Sent columns show a large difference in the amount of data sent and received. The time taken for this mtimes operation is similar on all labs, because the codistributed array communication implicitly synchronizes communication between them.
In the last column of the Busy lines table, a bar shows the percentage for the selected field. These bars can also be used to visually compare Total Time, and Data Sent or Data Received of the main and comparison labs.
Use Plots to Observe Codistributed Array Operations
To get more specific information about a codistributed array operation, click the relevant function name in the Function Detail Report.
To get the inter-lab communication data, click Heatmap in the Plots section of the toolstrip. In the first figure, you can see that lab 1 transfers the most amount of data, and the last lab (lab 12) transfers the least amount of data.
Using the heatmaps, you can also see the amount of data communicated between each lab. This is constant for all labs except for the first and last labs. When there is no explicit communication, this indicates a distribution problem. In a typical codistributed array mtimes operation, labs that have the least amount of data (e.g., lab 1) receive all the required data from their neighboring labs (e.g., lab 2).
The Data Transferred Plot
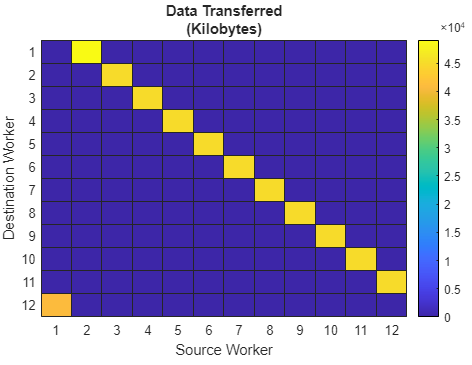
In the Data Transferred plot, there is a significant decrease in the amount of data transferred to the last lab and an increase in the amount transferred to the first lab. Observing the Communication Time plot (not shown) further illustrates that there is something different going on in the first lab. That is, the first lab is spending the longest amount of time in communication.
As you can see, the uneven distribution of a matrix causes unnecessary communication delays when using data parallel codistributed array operations and uneven work distribution with task parallel (no communication) operations. In addition, labs (like the first lab in this example) that are receiving more data start with the least amount of data prior to the codistributed array operation.