yamnetPreprocess
Preprocess audio for YAMNet classification
Syntax
Description
Examples
Read in an audio signal to classify it.
[audioIn,fs] = audioread( "TrainWhistle-16-44p1-mono-9secs.wav");
"TrainWhistle-16-44p1-mono-9secs.wav");Plot and listen to the audio signal.
t = (0:numel(audioIn)-1)/fs; plot(t,audioIn) xlabel("Time (s)") ylabel("Ampltiude") axis tight

sound(audioIn,fs)
YAMNet requires you to preprocess the audio signal to match the input format used to train the network. The preprocesssing steps include resampling the audio signal and computing an array of mel spectrograms. To learn more about mel spectrograms, see melSpectrogram. Use yamnetPreprocess to preprocess the signal and extract the mel spectrograms to be passed to YAMNet. Visualize one of these spectrograms chosen at random.
spectrograms = yamnetPreprocess(audioIn,fs); arbitrarySpect = spectrograms(:,:,1,randi(size(spectrograms,4))); surf(arbitrarySpect,EdgeColor="none") view([90 -90]) xlabel("Mel Band") ylabel("Frame") title("Mel Spectrogram for YAMNet") axis tight

Create a YAMNet neural network using the audioPretrainedNetwork function. Call predict with the network on the preprocessed mel spectrogram images. Convert the network output to class labels using scores2label.
[net,classNames] = audioPretrainedNetwork("yamnet");
scores = predict(net,spectrograms);
classes = scores2label(scores,classNames);The classification step returns a label for each of the spectrogram images in the input. Classify the sound as the most frequently occurring label in the output.
mySound = mode(classes)
mySound = categorical
Whistle
Download and unzip the air compressor data set [1]. This data set consists of recordings from air compressors in a healthy state or one of 7 faulty states.
url = "https://www.mathworks.com/supportfiles/audio/AirCompressorDataset/AirCompressorDataset.zip"; downloadFolder = fullfile(tempdir,"aircompressordataset"); datasetLocation = tempdir; if ~exist(fullfile(tempdir,"AirCompressorDataSet"),"dir") loc = websave(downloadFolder,url); unzip(loc,fullfile(tempdir,"AirCompressorDataSet")) end
Create an audioDatastore object to manage the data and split it into train and validation sets.
ads = audioDatastore(downloadFolder,IncludeSubfolders=true,LabelSource="foldernames");
[adsTrain,adsValidation] = splitEachLabel(ads,0.8,0.2);Read an audio file from the datastore and save the sample rate for later use. Reset the datastore to return the read pointer to the beginning of the data set. Listen to the audio signal and plot the signal in the time domain.
[x,fileInfo] = read(adsTrain); fs = fileInfo.SampleRate; reset(adsTrain) sound(x,fs) figure t = (0:size(x,1)-1)/fs; plot(t,x) xlabel("Time (s)") title("State = " + string(fileInfo.Label)) axis tight

Extract Mel spectrograms from the train set using yamnetPreprocess. There are multiple spectrograms for each audio signal. Replicate the labels so that they are in one-to-one correspondence with the spectrograms.
emptyLabelVector = adsTrain.Labels; emptyLabelVector(:) = []; trainFeatures = []; trainLabels = emptyLabelVector; while hasdata(adsTrain) [audioIn,fileInfo] = read(adsTrain); features = yamnetPreprocess(audioIn,fileInfo.SampleRate); numSpectrums = size(features,4); trainFeatures = cat(4,trainFeatures,features); trainLabels = cat(2,trainLabels,repmat(fileInfo.Label,1,numSpectrums)); end
Extract features from the validation set and replicate the labels.
validationFeatures = []; validationLabels = emptyLabelVector; while hasdata(adsValidation) [audioIn,fileInfo] = read(adsValidation); features = yamnetPreprocess(audioIn,fileInfo.SampleRate); numSpectrums = size(features,4); validationFeatures = cat(4,validationFeatures,features); validationLabels = cat(2,validationLabels,repmat(fileInfo.Label,1,numSpectrums)); end
The air compressor data set has only 8 classes. Call audioPretrainedNetwork with NumClasses set to 8 to load a pretrained YAMNet network with the desired number of output classes for transfer learning.
classNames = categories(adsTrain.Labels);
numClasses = numel(classNames);
net = audioPretrainedNetwork("yamnet",NumClasses=numClasses);To define training options, use trainingOptions.
miniBatchSize = 128; validationFrequency = floor(numel(trainLabels)/miniBatchSize); options = trainingOptions('adam', ... InitialLearnRate=3e-4, ... MaxEpochs=2, ... MiniBatchSize=miniBatchSize, ... Shuffle="every-epoch", ... Plots="training-progress", ... Metrics="accuracy", ... Verbose=false, ... ValidationData={single(validationFeatures),validationLabels'}, ... ValidationFrequency=validationFrequency);
To train the network, use trainnet.
airCompressorNet = trainnet(trainFeatures,trainLabels',net,"crossentropy",options);![]()
Save the trained network to airCompressorNet.mat. You can now use this pre-trained network by loading the airCompressorNet.mat file.
save airCompressorNet.mat airCompressorNet
References
[1] Verma, Nishchal K., et al. “Intelligent Condition Based Monitoring Using Acoustic Signals for Air Compressors.” IEEE Transactions on Reliability, vol. 65, no. 1, Mar. 2016, pp. 291–309. DOI.org (Crossref), doi:10.1109/TR.2015.2459684.
Read in an audio signal
[audioIn,fs] = audioread("TrainWhistle-48-mono-2p5sec.opus");Use audioViewer to visualize and listen to the audio.
audioViewer(audioIn,fs)

Use yanmetPreprocess to generate mel spectrograms that can be fed to the YAMNet pretrained network. Specify additional outputs to get the center frequencies of the bands and the locations of the windows in time.
[spectrograms,cf,ts] = yamnetPreprocess(audioIn,fs);
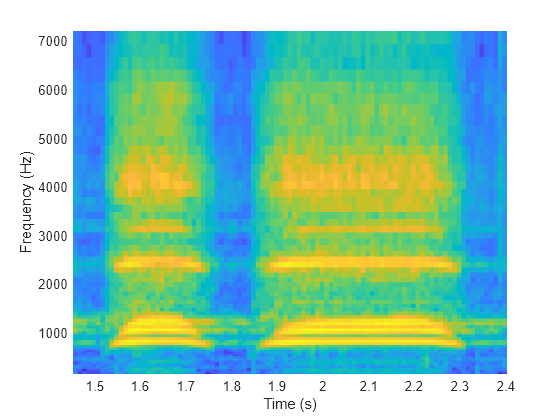
Choose a random spectrogram from the input to visualize. Use the center frequency and time location information to label the axes.
spectIdx = randi(size(spectrograms,4)); randSpect = spectrograms(:,:,1,spectIdx); surf(cf,ts(:,spectIdx),randSpect,EdgeColor="none") view([90 -90]) xlabel("Frequency (Hz)") ylabel("Time (s)") axis tight
Input Arguments
Output Arguments
References
[1] Gemmeke, Jort F., et al. “Audio Set: An Ontology and Human-Labeled Dataset for Audio Events.” 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2017, pp. 776–80. DOI.org (Crossref), doi:10.1109/ICASSP.2017.7952261.
[2] Hershey, Shawn, et al. “CNN Architectures for Large-Scale Audio Classification.” 2017 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), IEEE, 2017, pp. 131–35. DOI.org (Crossref), doi:10.1109/ICASSP.2017.7952132.