batchnorm
Normalize data across all observations for each channel independently
Syntax
Description
The batch normalization operation normalizes the input data
across all observations for each channel independently. To speed up training of the
convolutional neural network and reduce the sensitivity to network initialization, use batch
normalization between convolution and nonlinear operations such as relu.
After normalization, the operation shifts the input by a learnable offset β and scales it by a learnable scale factor γ.
The batchnorm function applies the batch normalization operation to
dlarray data.
Using dlarray objects makes working with high
dimensional data easier by allowing you to label the dimensions. For example, you can label
which dimensions correspond to spatial, time, channel, and batch dimensions using the
"S", "T", "C", and
"B" labels, respectively. For unspecified and other dimensions, use the
"U" label. For dlarray object functions that operate
over particular dimensions, you can specify the dimension labels by formatting the
dlarray object directly, or by using the DataFormat
option.
Note
To apply batch normalization within a dlnetwork object, use batchNormalizationLayer.
Y = batchnorm(X,offset,scaleFactor)X using the
population mean and variance of the input data and the specified offset and scale
factor.
The function normalizes over the 'S' (spatial),
'T' (time), 'B' (batch), and 'U'
(unspecified) dimensions of X for each channel in the
'C' (channel) dimension, independently.
For unformatted input data, use the 'DataFormat'
option.
[
applies the batch normalization operation and also returns the population mean and variance
of the input data Y,popMu,popSigmaSq] = batchnorm(X,offset,scaleFactor)X.
[
applies the batch normalization operation and also returns the updated moving mean and
variance statistics. Y,updatedMu,updatedSigmaSq] = batchnorm(X,offset,scaleFactor,runningMu,runningSigmaSq)runningMu and runningSigmaSq
are the mean and variance values after the previous training iteration, respectively.
Use this syntax to maintain running values for the mean and variance statistics during training. When you have finished training, use the final updated values of the mean and variance for the batch normalization operation during prediction and classification.
Y = batchnorm(X,offset,scaleFactor,trainedMu,trainedSigmaSq)trainedMu and
variance trainedSigmaSq.
Use this syntax during classification and prediction, where
trainedMu and trainedSigmaSq are the final
values of the mean and variance after you have finished training, respectively.
[___] = batchnorm(___,'DataFormat',FMT)
applies the batch normalization operation to unformatted input data with format specified by
FMT using any of the input or output combinations in previous syntaxes.
The output Y is an unformatted dlarray object with
dimensions in the same order as X. For example,
'DataFormat','SSCB' specifies data for 2-D image input with the format
'SSCB' (spatial, spatial, channel, batch).
[___] = batchnorm(___,
specifies additional options using one or more name-value pair arguments. For example,
Name,Value)'MeanDecay',0.3 sets the decay rate of the moving average
computation.
Examples
Create a formatted dlarray object containing a batch of 128 28-by-28 images with 3 channels. Specify the format 'SSCB' (spatial, spatial, channel, batch).
miniBatchSize = 128;
inputSize = [28 28];
numChannels = 3;
X = rand(inputSize(1),inputSize(2),numChannels,miniBatchSize);
dlX = dlarray(X,'SSCB');View the size and format of the input data.
size(dlX)
ans = 1×4
28 28 3 128
dims(dlX)
ans = 'SSCB'
Initialize the scale and offset for batch normalization. For the scale, specify a vector of ones. For the offset, specify a vector of zeros.
scaleFactor = ones(numChannels,1); offset = zeros(numChannels,1);
Apply the batch normalization operation using the batchnorm function and return the mini-batch statistics.
[dlY,mu,sigmaSq] = batchnorm(dlX,offset,scaleFactor);
View the size and format of the output dlY.
size(dlY)
ans = 1×4
28 28 3 128
dims(dlY)
ans = 'SSCB'
View the mini-batch mean mu.
mu
mu = 3×1
0.4998
0.4993
0.5011
View the mini-batch variance sigmaSq.
sigmaSq
sigmaSq = 3×1
0.0831
0.0832
0.0835
Use the batchnorm function to normalize several batches of data and update the statistics of the whole data set after each normalization.
Create three batches of data. The data consists of 10-by-10 random arrays with five channels. Each batch contains 20 observations. The second and third batches are scaled by a multiplicative factor of 1.5 and 2.5, respectively, so the mean of the data set increases with each batch.
height = 10; width = 10; numChannels = 5; observations = 20; X1 = rand(height,width,numChannels,observations); dlX1 = dlarray(X1,"SSCB"); X2 = 1.5*rand(height,width,numChannels,observations); dlX2 = dlarray(X2,"SSCB"); X3 = 2.5*rand(height,width,numChannels,observations); dlX3 = dlarray(X3,"SSCB");
Create the learnable parameters.
offset = zeros(numChannels,1); scale = ones(numChannels,1);
Normalize the first batch of data dlX1 using batchnorm. Obtain the values of the mean and variance of this batch as outputs.
[dlY1,mu,sigmaSq] = batchnorm(dlX1,offset,scale);
Normalize the second batch of data dlX2. Use mu and sigmaSq as inputs to obtain the values of the combined mean and variance of the data in batches dlX1 and dlX2.
[dlY2,datasetMu,datasetSigmaSq] = batchnorm(dlX2,offset,scale,mu,sigmaSq);
Normalize the final batch of data dlX3. Update the data set statistics datasetMu and datasetSigmaSq to obtain the values of the combined mean and variance of all data in batches dlX1, dlX2, and dlX3.
[dlY3,datasetMuFull,datasetSigmaSqFull] = batchnorm(dlX3,offset,scale,datasetMu,datasetSigmaSq);
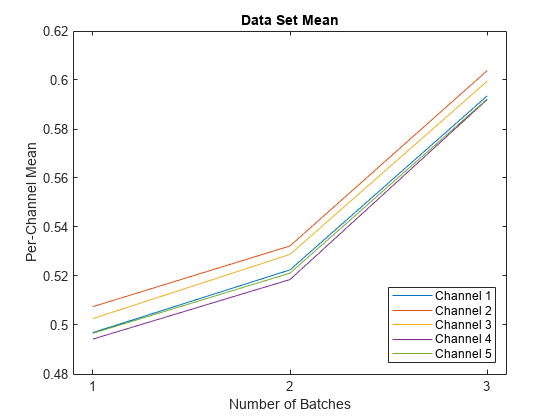
Observe the change in the mean of each channel as each batch is normalized.
plot([mu datasetMu datasetMuFull]') legend("Channel " + string(1:5),"Location","southeast") xticks([1 2 3]) xlabel("Number of Batches") xlim([0.9 3.1]) ylabel("Per-Channel Mean") title("Data Set Mean")