Complex Partial-Systolic Q-less QR Decomposition with Forgetting Factor
Q-less QR decomposition for complex-valued matrices with infinite number of rows

Libraries:
Fixed-Point Designer HDL Support /
Matrices and Linear Algebra /
Matrix Factorizations
Description
The Complex Partial-Systolic Q-less QR Decomposition with Forgetting Factor block uses QR decomposition to compute the economy size upper-triangular R factor of the QR decomposition A = QR, without computing Q. A is an infinitely tall complex-valued matrix representing streaming data.
When the regularization parameter is nonzero, the Complex Partial-Systolic Q-less
QR Decomposition with Forgetting Factor block initializes the first upper-triangular
factor R to λIn before factoring
in the rows of A, where λ is the regularization
parameter and In =
eye(n).
Examples

Implement Hardware-Efficient Complex Partial-Systolic Q-less QR with Forgetting Factor
How to use the Complex Partial-Systolic Q-less QR Decomposition with Forgetting Factor block.

Determine Fixed-Point Types for Q-less QR Decomposition
Use fixed.qlessqrFixedpointTypes to determine fixed-point types for
computation of Q-less QR decomposition.
Ports
Input
Output
Parameters
Algorithms
The Partial-Systolic QR Decomposition with Forgetting Factor blocks accept and process the matrix A row by row. After accepting the first m rows, the block starts to output the R matrix as a single vector. From this point, for each row input, the block calculates a R matrix. The partial-systolic implementation uses a pipelined structure, so the block can accept new matrix inputs before outputting the result of the current matrix.
For example, assume that the input matrix A is 3-by-3. Additionally
assume that validIn asserts before ready, meaning that
the upstream data source is faster than the Q-less QR decomposition.
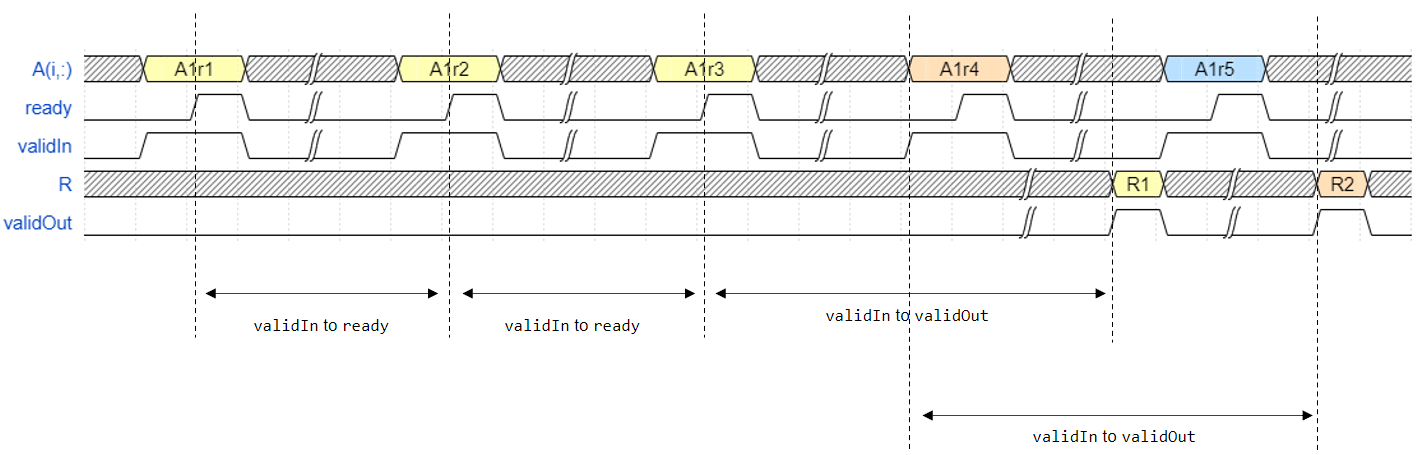
In the figure,
A1r1is the first row of the first A matrix,R1is the first R matrix, and so on.validIntoready— From a successful row input to the block being ready to accept the next row.validIntovalidOut— From a successful row input to the block starting to output the corresponding solution.
The following table provides details of the timing for the Partial-Systolic Q-less QR Decomposition with Forgetting Factor blocks.
| Block | validIn to ready (cycles) | validIn to validOut
(cycles) |
|---|---|---|
| Real Partial-Systolic Q-less QR Decomposition with Forgetting Factor | wl + 7 | (wl + 6)*n + 3 |
| Complex Partial-Systolic Q-less QR Decomposition with Forgetting Factor | wl + 9 | (wl + 7.5)*2*n + 3 |
In the table, m represents the number of rows in matrix A, and n is the number of columns in matrix A. wl represents the word length of A.
If the data type of A is fixed point, then wl is the word length.
If the data type of A is double, then wl is 53.
If the data type of A is single, then wl is 24.
References
[1] "AMBA AXI and ACE Protocol Specification Version E." https://developer.arm.com/documentation/ihi0022/e/