matchScansLine
Estimate pose between two laser scans using line features
Syntax
Description
relpose = matchScansLine(currScan,refScan,initialRelPose)initialRelPose.
[___] = matchScansLine(___,
specifies options using one or more name-value pair arguments.Name,Value)
Examples
This example shows how to use the matchScansLine function to estimate the relative pose between lidar scans given an initial estimate. The identified line features are visualized to show how the scan-matching algorithm associates features between scans.
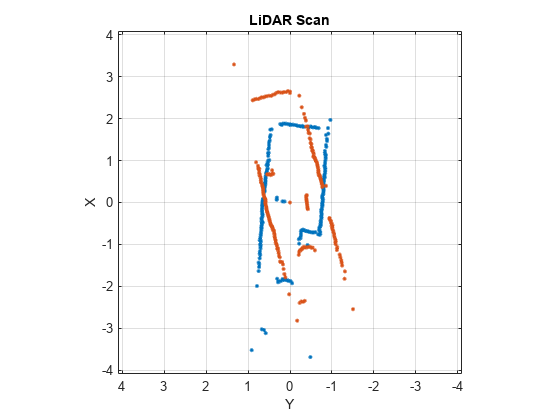
Load a pair of lidar scans. The .mat file also contains an initial guess of the relative pose difference, initGuess, which could be based on odometry or other sensor data.
load tb3_scanPair.mat plot(s1) hold on plot(s2) hold off
Set parameters for line feature extraction and association. The noise of the lidar data determines the smoothness threshold, which defines when a line break occurs for a specific line feature. Increase this value for more noisy lidar data. The compatibility scale determines when features are considered matches. Increase this value for looser restrictions on line feature parameters.
smoothnessThresh = 0.2; compatibilityScale = 0.002;
Call matchScansLine with the given initial guess and other parameters specified as name-value pairs. The function calculates line features for each scan, attempts to match them, and uses an overall estimate to get the difference in pose.
[relPose, stats, debugInfo] = matchScansLine(s2, s1, initGuess, ... 'SmoothnessThreshold', smoothnessThresh, ... 'CompatibilityScale', compatibilityScale);
After matching the scans, the debugInfo output gives you information about the detected line feature parameters, [rho alpha], and the hypothesis of which features match between scans.
debugInfo.MatchHypothesis states that the first, second, and sixth line feature in s1 match the fifth, second, and fourth features in s2.
debugInfo.MatchHypothesis
ans = 1×6
5 2 0 0 0 4
The provided helper function plots these two scans and the features extracted with labels. s2 is transformed to be in the same frame based on the initial guess for relative pose.
exampleHelperShowLineFeaturesInScan(s1, s2, debugInfo, initGuess);

Use the estimated relative pose from matchScansLine to transform s2. Then, plot both scans to show that the relative pose difference is accurate and the scans overlay to show the same environment.
s2t = transformScan(s2,relPose); clf plot(s1) hold on plot(s2t) hold off

Input Arguments
Name-Value Arguments
Output Arguments
References
[1] Neira, J., and J.d. Tardos. “Data Association in Stochastic Mapping Using the Joint Compatibility Test.” IEEE Transactions on Robotics and Automation 17, no. 6 (2001): 890–97. https://doi.org/10.1109/70.976019.
[2] Shen, Xiaotong, Emilio Frazzoli, Daniela Rus, and Marcelo H. Ang. “Fast Joint Compatibility Branch and Bound for Feature Cloud Matching.” 2016 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), 2016. https://doi.org/10.1109/iros.2016.7759281.
Version History
Introduced in R2020a