rlContinuousDeterministicTransitionFunction
Deterministic transition function approximator object for neural network-based environment
Since R2022a
Description
When creating a neural network-based environment using rlNeuralNetworkEnvironment, you can specify deterministic transition function
approximators using rlContinuousDeterministicTransitionFunction
objects.
A transition function approximator object uses a deep neural network to predict the next observations based on the current observations and actions.
To specify stochastic transition function approximators, use rlContinuousGaussianTransitionFunction objects.
Creation
Syntax
Description
tsnFcnAppx = rlContinuousDeterministicTransitionFunction(net,observationInfo,actionInfo,Name=Value)net and sets the ObservationInfo and
ActionInfo properties.
When creating a deterministic transition function approximator you must specify the
names of the deep neural network inputs and outputs using the
ObservationInputNames, ActionInputNames, and
NextObservationOutputNames name-value pair arguments.
You can also specify the PredictDiff and
UseDevice properties using optional name-value pair arguments. For
example, to use a GPU for prediction, specify UseDevice="gpu".
Input Arguments
Name-Value Arguments
Properties
Object Functions
rlNeuralNetworkEnvironment | Environment model with deep neural network transition models |
Examples
Create an environment object and extract observation and action specifications. Alternatively, you can create specifications using rlNumericSpec and rlFiniteSetSpec.
env = rlPredefinedEnv("CartPole-Continuous");
obsInfo = getObservationInfo(env);
actInfo = getActionInfo(env);To approximate the transition function, create a deep neural network. The network has two input layers, one for the current observation channel and one for the current action channel. The single output layer is for the predicted next observation.
Define each network path as an array of layer objects. Get the dimensions of the observation and action spaces from the environment specifications, and specify a name for the input and output layers, so you can later explicitly associate them with the appropriate environment channel.
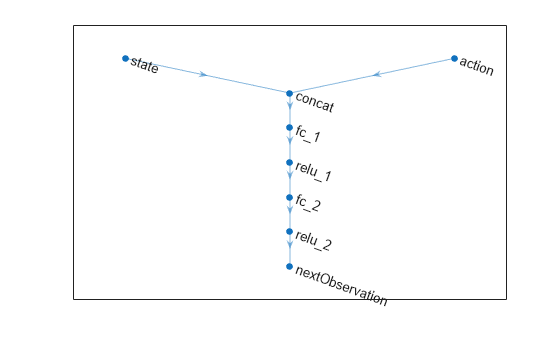
statePath = featureInputLayer(obsInfo.Dimension(1),Name="state"); actionPath = featureInputLayer(actInfo.Dimension(1),Name="action"); commonPath = [ concatenationLayer(1,2,Name="concat") fullyConnectedLayer(64) reluLayer fullyConnectedLayer(64) reluLayer fullyConnectedLayer(obsInfo.Dimension(1),Name="nextObservation") ];
Create dlnetwork object and add layers.
tsnNet = dlnetwork(); tsnNet = addLayers(tsnNet,statePath); tsnNet = addLayers(tsnNet,actionPath); tsnNet = addLayers(tsnNet,commonPath);
Connect layers.
tsnNet = connectLayers(tsnNet,"state","concat/in1"); tsnNet = connectLayers(tsnNet,"action","concat/in2");
Plot network.
plot(tsnNet)
Initialize network and display the number of weights.
tsnNet = initialize(tsnNet); summary(tsnNet)
Initialized: true
Number of learnables: 4.8k
Inputs:
1 'state' 4 features
2 'action' 1 features
Create a deterministic transition function object.
tsnFcnAppx = rlContinuousDeterministicTransitionFunction( ... tsnNet,obsInfo,actInfo, ... ObservationInputNames="state", ... ActionInputNames="action", ... NextObservationOutputNames="nextObservation");
Using this transition function object, you can predict the next observation based on the current observation and action. For example, predict the next observation for a random observation and action.
obs = rand(obsInfo.Dimension);
act = rand(actInfo.Dimension);
nextObsP = predict(tsnFcnAppx,{obs},{act})nextObsP = 1×1 cell array
{4×1 single}
nextObsP{1}ans = 4×1 single column vector
-0.1172
0.1168
0.0493
-0.0155
You can also obtain the same result using evaluate.
nextObsE = evaluate(tsnFcnAppx,{obs,act})nextObsE = 1×1 cell array
{4×1 single}
nextObsE{1}ans = 4×1 single column vector
-0.1172
0.1168
0.0493
-0.0155
Version History
Introduced in R2022a