compare
Compare linear mixed-effects models
Syntax
Description
results = compare(lme,altlme)lme and altlme. Both models must use
the same response vector in the fit and lme must be nested in
altlme for a valid theoretical likelihood ratio test.
Always input the smaller model first, and the larger model second.
compare tests the following null and alternate
hypotheses:
H0: Observed response vector is
generated by lme.
H1: Observed response vector is
generated by model altlme.
It is recommended that you fit lme and
altlme using the maximum likelihood (ML) method prior to
model comparison. If you use the restricted maximum likelihood (REML) method,
then both models must have the same fixed-effects design matrix.
To test for fixed effects, use compare with the simulated likelihood ratio
test when lme and altlme are
fit using ML or use the fixedEffects,
anova, or coefTest methods.
results = compare(___,Name,Value)lme and altlme with
additional options specified by one or more Name,Value pair
arguments.
For example, you can check if the first input model is nested in the second input model.
[
returns the results of a simulated likelihood ratio test that compares linear
mixed-effects models results,siminfo]
= compare(lme,altlme,'NSim',nsim)lme and
altlme.
You can fit lme and altlme using ML or
REML. Also, lme does not have to be nested in
altlme. If you use the restricted maximum likelihood
(REML) method to fit the models, then both models must have the same
fixed-effects design matrix.
[
also returns the results of a simulated likelihood ratio test that compares
linear mixed-effects models results,siminfo]
= compare(___,Name,Value)lme and altlme
with additional options specified by one or more Name,Value
pair arguments.
For example, you can change the options for performing the simulated likelihood ratio test, or change the confidence level of the confidence interval for the p-value.
Examples
Load the sample data and convert it to table format.
load flu
flu = dataset2table(flu)flu=52×11 table
Date NE MidAtl ENCentral WNCentral SAtl ESCentral WSCentral Mtn Pac WtdILI
______________ _____ ______ _________ _________ _____ _________ _________ _____ _____ ______
{'10/9/2005' } 0.97 1.025 1.232 1.286 1.082 1.457 1.1 0.981 0.971 1.182
{'10/16/2005'} 1.136 1.06 1.228 1.286 1.146 1.644 1.123 0.976 0.917 1.22
{'10/23/2005'} 1.135 1.172 1.278 1.536 1.274 1.556 1.236 1.102 0.895 1.31
{'10/30/2005'} 1.52 1.489 1.576 1.794 1.59 2.252 1.612 1.321 1.082 1.343
{'11/6/2005' } 1.365 1.394 1.53 1.825 1.62 2.059 1.471 1.453 1.118 1.586
{'11/13/2005'} 1.39 1.477 1.506 1.9 1.683 1.813 1.464 1.388 1.204 1.47
{'11/20/2005'} 1.212 1.231 1.295 1.495 1.347 1.794 1.303 1.371 1.137 1.611
{'11/27/2005'} 1.477 1.546 1.557 1.855 1.678 2.159 1.739 1.628 1.443 1.827
{'12/4/2005' } 1.285 1.43 1.482 1.635 1.577 1.903 1.53 1.701 1.516 1.776
{'12/11/2005'} 1.354 1.45 1.46 1.794 1.583 1.894 1.831 2.364 2.094 1.941
{'12/18/2005'} 1.502 1.622 1.638 1.988 1.947 2.22 2.577 3.89 2.66 2.34
{'12/25/2005'} 1.86 1.915 1.955 2.38 2.343 3.027 3.219 4.862 2.595 3.086
{'1/1/2006' } 2.114 2.174 2.065 2.557 2.275 2.498 2.644 3.352 2.181 3.26
{'1/8/2006' } 1.815 1.932 1.822 2.046 1.969 1.805 2.189 2.132 1.717 2.613
{'1/15/2006' } 1.541 1.695 1.581 2.008 1.718 1.662 2.156 1.694 1.351 2.247
{'1/22/2006' } 1.632 1.758 1.711 2.217 1.866 2.194 2.268 1.826 1.384 2.352
⋮
The flu table has a Date variable, and 10 variables containing estimated influenza rates (in 9 different regions, estimated from Google® searches, plus a nationwide estimate from the CDC).
To fit a linear-mixed effects model, your data must be in a properly formatted table. To fit a linear mixed-effects model with the influenza rates as the responses and region as the predictor variable, combine the nine columns corresponding to the regions into an array. The new table, flu2, must have the response variable, FluRate, the nominal variable, Region, that shows which region each estimate is from, and the grouping variable Date.
flu2 = stack(flu,2:10,NewDataVariableName="FluRate",... IndexVariableName="Region"); flu2.Date = nominal(flu2.Date);
Fit a linear mixed-effects model, with a varying intercept and varying slope for each region, grouped by Date.
altlme = fitlme(flu2,"FluRate ~ 1 + Region + (1 + Region|Date)");Fit a linear mixed-effects model with fixed effects for the region and a random intercept that varies by Date.
lme = fitlme(flu2,"FluRate ~ 1 + Region + (1|Date)");Compare the two models. Also check if lme2 is nested in lme.
compare(lme,altlme,CheckNesting=true)
ans =
Theoretical Likelihood Ratio Test
Model DF AIC BIC LogLik LRStat deltaDF pValue
lme 11 318.71 364.35 -148.36
altlme 55 -305.51 -77.346 207.76 712.22 44 0
The small -value of 0 indicates that model altlme is significantly better than the simpler model lme.
Load and display the sample data.
load fertilizer.mat;
tbltbl=60×4 table
Soil Tomato Fertilizer Yield
_________ ____________ __________ _____
{'Sandy'} {'Plum' } 1 104
{'Sandy'} {'Plum' } 2 136
{'Sandy'} {'Plum' } 3 158
{'Sandy'} {'Plum' } 4 174
{'Sandy'} {'Cherry' } 1 57
{'Sandy'} {'Cherry' } 2 86
{'Sandy'} {'Cherry' } 3 89
{'Sandy'} {'Cherry' } 4 98
{'Sandy'} {'Heirloom'} 1 65
{'Sandy'} {'Heirloom'} 2 62
{'Sandy'} {'Heirloom'} 3 113
{'Sandy'} {'Heirloom'} 4 84
{'Sandy'} {'Grape' } 1 54
{'Sandy'} {'Grape' } 2 86
{'Sandy'} {'Grape' } 3 89
{'Sandy'} {'Grape' } 4 115
⋮
The table tbl includes data from a split-plot experiment, where soil is divided into three blocks based on the soil type: sandy, silty, and loamy. Each block is divided into five plots, where five different types of tomato plants (cherry, heirloom, grape, vine, and plum) are randomly assigned to these plots. The tomato plants in the plots are then divided into subplots, where each subplot is treated by one of four fertilizers. This is simulated data.
Convert Tomato, Soil, and Fertilizer to categorical variables.
tbl.Tomato = nominal(tbl.Tomato); tbl.Soil = nominal(tbl.Soil); tbl.Fertilizer = nominal(tbl.Fertilizer);
Fit a linear mixed-effects model, where Fertilizer and Tomato are the fixed-effects variables, and the mean yield varies by the block (soil type) and the plots within blocks (tomato types within soil types) independently.
lmeBig = fitlme(tbl,"Yield ~ Fertilizer * Tomato + (1|Soil) + (1|Soil:Tomato)");Refit the model after removing the interaction term Tomato:Fertilizer and the random-effects term (1 | Soil).
lmeSmall = fitlme(tbl,"Yield ~ Fertilizer + Tomato + (1|Soil:Tomato)");Compare the two models using the simulated likelihood ratio test with 1000 replications. You must use this test to test for both fixed- and random-effect terms. Note that both models are fit using the default fitting method, ML. That’s why, there is no restriction on the fixed-effects design matrices. If you use restricted maximum likelihood (REML) method, both models must have identical fixed-effects design matrices.
[table,siminfo] = compare(lmeSmall,lmeBig,nsim=1000)
table =
Simulated Likelihood Ratio Test: Nsim = 1000, Alpha = 0.05
Model DF AIC BIC LogLik LRStat pValue Lower Upper
lmeSmall 10 511.06 532 -245.53
lmeBig 23 522.57 570.74 -238.29 14.491 0.57343 0.54211 0.60431
siminfo = struct with fields:
nsim: 1000
alpha: 0.0500
pvalueSim: 0.5734
pvalueSimCI: [0.5421 0.6043]
deltaDF: 13
TH0: [1000×1 double]
The high -value suggests that the larger model, lme is not significantly better than the smaller model, lme2. The smaller values of Akaike and Bayesian Information Criteria for lme2 also support this.
Load the sample data.
load carbig
Fit a linear mixed-effects model for miles per gallon (MPG), with fixed effects for acceleration, horsepower, and the cylinders, and potentially correlated random effects for intercept and acceleration grouped by model year.
First, prepare the design matrices.
X = [ones(406,1) Acceleration Horsepower]; Z = [ones(406,1) Acceleration]; Model_Year = nominal(Model_Year); G = Model_Year;
Now, fit the model using fitlmematrix with the defined design matrices and grouping variables.
lme = fitlmematrix(X,MPG,Z,G,'FixedEffectPredictors',.... {'Intercept','Acceleration','Horsepower'},'RandomEffectPredictors',... {{'Intercept','Acceleration'}},'RandomEffectGroups',{'Model_Year'});
Refit the model with uncorrelated random effects for intercept and acceleration. First prepare the random effects design and the random effects grouping variables.
Z = {ones(406,1),Acceleration};
G = {Model_Year,Model_Year};
lme2 = fitlmematrix(X,MPG,Z,G,'FixedEffectPredictors',....
{'Intercept','Acceleration','Horsepower'},'RandomEffectPredictors',...
{{'Intercept'},{'Acceleration'}},'RandomEffectGroups',...
{'Model_Year','Model_Year'});
Compare lme and lme2 using the simulated likelihood ratio test.
compare(lme2,lme,'CheckNesting',true,'NSim',1000)
ans =
SIMULATED LIKELIHOOD RATIO TEST: NSIM = 1000, ALPHA = 0.05
Model DF AIC BIC LogLik LRStat pValue Lower
lme2 6 2194.5 2218.3 -1091.3
lme 7 2193.5 2221.3 -1089.7 3.0323 0.094905 0.077462
Upper
0.11477
The high 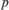 -value indicates that
-value indicates that lme2 is not a significantly better fit than lme.
Load and display the sample data.
load fertilizer.mat
tbltbl=60×4 table
Soil Tomato Fertilizer Yield
_________ ____________ __________ _____
{'Sandy'} {'Plum' } 1 104
{'Sandy'} {'Plum' } 2 136
{'Sandy'} {'Plum' } 3 158
{'Sandy'} {'Plum' } 4 174
{'Sandy'} {'Cherry' } 1 57
{'Sandy'} {'Cherry' } 2 86
{'Sandy'} {'Cherry' } 3 89
{'Sandy'} {'Cherry' } 4 98
{'Sandy'} {'Heirloom'} 1 65
{'Sandy'} {'Heirloom'} 2 62
{'Sandy'} {'Heirloom'} 3 113
{'Sandy'} {'Heirloom'} 4 84
{'Sandy'} {'Grape' } 1 54
{'Sandy'} {'Grape' } 2 86
{'Sandy'} {'Grape' } 3 89
{'Sandy'} {'Grape' } 4 115
⋮
The tbl table includes data from a split-plot experiment, where soil is divided into three blocks based on the soil type: sandy, silty, and loamy. Each block is divided into five plots, where five different types of tomato plants (cherry, heirloom, grape, vine, and plum) are randomly assigned to these plots. The tomato plants in the plots are then divided into subplots, where each subplot is treated by one of four fertilizers. This is simulated data.
Convert Tomato, Soil, and Fertilizer to categorical variables.
tbl.Tomato = categorical(tbl.Tomato); tbl.Soil = categorical(tbl.Soil); tbl.Fertilizer = categorical(tbl.Fertilizer);
Fit a linear mixed-effects model, where Fertilizer and Tomato are the fixed-effects variables, and the mean yield varies by the block (soil type), and the plots within blocks (tomato types within soil types) independently.
lme = fitlme(tbl,"Yield ~ Fertilizer * Tomato + (1|Soil) + (1|Soil:Tomato)");Refit the model after removing the interaction term Tomato:Fertilizer and the random-effects term (1|Soil).
lme2 = fitlme(tbl,"Yield ~ Fertilizer + Tomato + (1|Soil:Tomato)");Create the options structure for LinearMixedModel.
opt = statset("LinearMixedModel")opt = struct with fields:
Display: 'off'
MaxFunEvals: []
MaxIter: 10000
TolBnd: []
TolFun: 1.0000e-06
TolTypeFun: []
TolX: 1.0000e-12
TolTypeX: []
GradObj: []
Jacobian: []
DerivStep: []
FunValCheck: []
Robust: []
RobustWgtFun: []
WgtFun: []
Tune: []
UseParallel: []
UseSubstreams: []
Streams: {}
OutputFcn: []
Change the options for parallel testing.
opt.UseParallel = true;
Start a parallel environment.
mypool = parpool();
Starting parallel pool (parpool) using the 'Processes' profile ... 13-Nov-2024 10:18:44: Job Queued. Waiting for parallel pool job with ID 4 to start ... Connected to parallel pool with 4 workers.
Compare lme2 and lme using the simulated likelihood ratio test with 1000 replications and parallel computing.
compare(lme2,lme,nsim=1000,Options=opt)
ans =
Simulated Likelihood Ratio Test: Nsim = 1000, Alpha = 0.05
Model DF AIC BIC LogLik LRStat pValue Lower Upper
lme2 10 511.06 532 -245.53
lme 23 522.57 570.74 -238.29 14.491 0.52747 0.496 0.55878
The high -value suggests that the larger model, lme is not significantly better than the smaller model, lme2. The smaller values of AIC and BIC for lme2 also support this.
Input Arguments
Name-Value Arguments
Output Arguments
More About
References
[1] Hox, J. Multilevel Analysis, Techniques and Applications. Lawrence Erlbaum Associates, Inc., 2002.
[2] Stram D. O. and J. W. Lee. “Variance components testing in the longitudinal mixed-effects model”. Biometrics, Vol. 50, 4, 1994, pp. 1171–1177.
Extended Capabilities
Version History
Introduced in R2013b
See Also
LinearMixedModel | fitlme | fitlmematrix | anova | fixedEffects | randomEffects | covarianceParameters