An Optimal State Estimator | Understanding Kalman Filters, Part 3
From the series: Understanding Kalman Filters
Melda Ulusoy, MathWorks
Watch this video for an explanation of how Kalman filters work. Kalman filters combine two sources of information, the predicted states and noisy measurements, to produce optimal, unbiased estimates of system states. The filter is optimal in the sense that it minimizes the variance in the estimated states.
The example introduces a linear single-state system where the measured output is the same as the state (the car’s position). The video explains process and measurement noise that affect the system. You’ll learn that the Kalman filter calculates an unbiased state estimate with minimum variance in the presence of uncertain measurements. The video shows the working principles behind Kalman filters by illustrating probability density functions. You can create the probability density functions discussed in the video by downloading the MATLAB® code from MATLAB Central File Exchange.
Download this virtual lab to study linear and extended Kalman filter design with interactive exercises.
Recorded: 27 Mar 2017
In this video, we'll discuss the working principles of the Kalman filter algorithm. Let's start with an example. While you are desperately staring at your bills, an ad in a magazine catches your eye. You can earn $1 million by joining a competition where you design a self-driving car which uses a GPS sensor to measure its position.
Your car is supposed to drive 1 kilometer on 100 different terrains. Each time, it must stop as close as possible to the finish line. At the end of the competition, the average final position is computed for each team, and the owner of the car with the smallest error variance and average final position closest to 1 kilometer gets the big prize.
Here's an example. Let these points represent the final position, and the red ones the average final position for different teams. Based on these results, Team 1 would lose due to the biased average final position, although it has small variance. Team 2 would lose as well. Its average final position is on the finish line, but it has high variance. The winner will be Team 3, since it has the smallest variance, and its average final position is on the finish line.
If you want to be a millionaire, you don't want to rely purely on GPS reading, since they can be noisy. In order to meet the required criteria to win the competition, you can estimate the car's position using a Kalman filter. Let's look at the system to understand how the Kalman filter works.
The input to the car is a throttle. The output that we're interested in is the car's position. For such a system, we would have multiple states. But here, to give you intuition, we'll assume an overly simplistic system, where the input to the car is the velocity. This system will have a single state, the car's position. And we're measuring the states so matrix C is equal to 1.
It's important to know y as accurately as possible, since we want the car to finish as close as possible to the finish line. But the GPS readings will be noisy. We'll show this measurement noise with v, which is a random variable. Similarly, there is process noise, which is also random and can represent the effects of the wind or changes in the car's velocity.
Although these random variables don't follow a pattern, using probability theory, we can tell something about their average properties. v, for example, is assumed to be drawn from a Gaussian distribution with zero mean and covariance R. This means if we measured the position of the car, let's say 100 times at the same location, the noise in these readings will take on values, with most of them located near to zero mean and fewer located farther away from it. And this results in the Gaussian distribution, which is described by the covariance R.
Since we have a single output system, the covariance R is scalar and is equal to the variance of the measurement noise. Similarly, the process noise is also random and assumes a Gaussian distribution with covariance Q. Now, we know that the measurement is noisy, and therefore what we measure doesn't quite reflect the true position of the car. If we know the car model, we can run the input through it to estimate the position. But this estimate also won't be perfect, because now we're estimating x, which is uncertain due to the process noise. This is where the Kalman filter comes into play. It combines these two pieces of information to come up with the best estimate of the car's position in the presence of process and measurement noise.
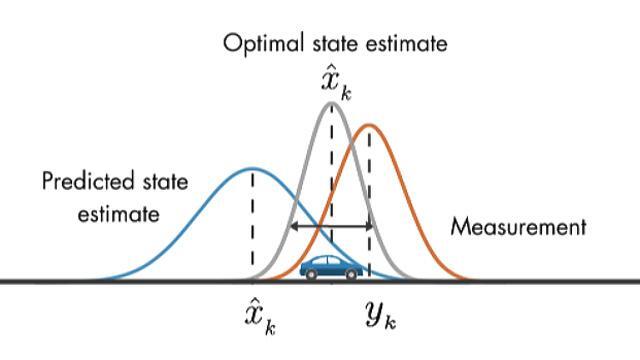
We'll discuss the working principle of the Kalman filter visually with the help of probability density functions. At the initial time step, k minus 1, the actual car position can be anywhere around the estimate x hat k minus 1. And this uncertainty is described by this probability density function.
What this plot also tells us is that the car is going to be most likely around the mean of this distribution. At the next time step, the uncertainty in the estimate has increased, which is shown with the larger variance. This is because between time step k minus 1 and k, the car might have run over a pothole, or maybe the wheels may have slipped a little bit. Therefore, it may have traveled a different distance than what we have predicted by the model.
As we discussed before, another source of information on car's position comes from the measurement. Here the variance represents the uncertainty in the noise measurement. Again, the true position can be anywhere around the mean.
Now that we have the prediction and measurement, the question is, what is the best estimate of the car's position? It turns out that the optimal way to estimate the car's position is by combining these two pieces of information. And this is done by multiplying these two probability functions together. The resulting product is also a Gaussian function.
This estimate has a smaller variance than either of the previous estimates, and the mean of this probability density function gives us the optimal estimate of the car's position. This is the basic idea behind Kalman filters. But to win the competition, you need to be able to implement the algorithm. We're going to discuss this in the next video.
Download Code and Files
Related Products
Learn More











Select a Web Site
Choose a web site to get translated content where available and see local events and offers. Based on your location, we recommend that you select: United States.
You can also select a web site from the following list
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)