Krebsdiagnosen mit Deep Learning und Photonic Time Stretch
Von Bahram Jalali, Claire Lifan Chen, and Ata Mahjoubfar, University of California, Los Angeles (UCLA)
Krebspatienten, die mit Chemotherapie oder Immuntherapie behandelt werden, müssen sich regelmäßig CT- und PET-Scans – und in einigen Fällen neuen Biopsien – unterziehen, um die Wirksamkeit der Behandlung zu beurteilen. Die Durchflusszytometrie, eine Methode zur Identifizierung zirkulierender Tumorzellen (ZTZ) mithilfe eines einfachen Bluttests, ist viel weniger invasiv als Scans und Biopsien und kann die Krebsbehandlung möglicherweise tiefgreifend verändern.
Bei der Durchflusszytometrie werden Zellen untersucht, während sie nacheinander eine kleine Öffnung in einem Durchflusszytometer durchlaufen. Bei der herkömmlichen Durchflusszytometrie benötigen die Zellen eine fluoreszierende Markierung. Diese kann das Verhalten der Zellen beeinflussen und die Anwendbarkeit des Verfahrens beeinträchtigen. Bildgebende Durchflusszytometer jedoch erfordern keine Markierungen. Bei Kamerageschwindigkeiten von mehr als 2000 Zellen pro Sekunde erzeugen sie jedoch unscharfe Bilder. Damit ist es nicht praktikabel, eine ausreichende Anzahl an Zellen zu scannen, um die seltenen abnormen Zellen zu finden.
Unsere Gruppe im Photoniklabor der UCLA hat ein TS-QPI-System (Time Stretch Quantitative Phase Imaging) entwickelt, das eine präzise Klassifikation großer Stichproben ohne Biomarker ermöglicht (Abbildung 1). Dieses System verbindet die bildgebende Durchflusszytometrie, die Photonic-Time-Stretch-Technologie (siehe Seitenleiste) sowie in MATLAB® entwickelte Machine-Learning-Algorithmen. Es kann Zellen mit über 95-prozentiger Genauigkeit identifizieren.

Abbildung 1: Dr. Jalali mit dem TS-QPI-System.
Auswählen von Merkmalen
Unser TS-QPI-System erzeugt 100 Gigabyte Daten pro Sekunde. Das ist ein enormer Datenstrom, der den gleichen Umfang hat wie 20 HD-Filme pro Sekunde. Für ein einzelnes Experiment, bei dem jede Zelle in einer Blutprobe von 10 Millilitern abgebildet wird und fast 100.000 Zellen pro Sekunde verarbeitet werden, erzeugt das System 10 bis 50 Terabyte Daten.
Mit MATLAB und der Image Processing Toolbox™ haben wir eine Machine-Vision-Pipeline entwickelt, um biophysikalische Merkmale aus Bildern von Zellen zu extrahieren. Die Pipeline umfasst unter anderem CellProfiler, ein in Python® geschriebenes Open-Source-Paket für die Analyse von Bildern von Zellen. Wir haben über 200 Merkmale aus jeder Zelle extrahiert, die wir in drei Kategorien gruppiert haben: morphologische Merkmale, die die Größe und die Form der Zelle charakterisieren, Merkmale optischer Phasen, die mit der Dichte der Zelle korrelieren, und Merkmale optischer Verluste, die mit der Größe von Organellen in der Zelle korrelieren. Eine lineare Regression hat gezeigt, dass 16 dieser Merkmale den Großteil der Informationen enthalten, die für die Klassifikation erforderlich sind.
Bewertung von Machine-Learning-Algorithmen
Ein wesentlicher Vorteil von MATLAB ist die Möglichkeit, zahlreiche unterschiedliche Machine-Learning-Modelle in kurzer Zeit zu testen. Wir verglichen vier Klassifikationsalgorithmen aus der Statistics and Machine Learning Toolbox™: naive Bayes-Klassifikation, Support Vector Machine (SVM), logistische Regression (LR) und ein tiefes neuronales Netz (Deep Neural Network, DNN), das mit Kreuzentropie und Backpropagation trainiert wurde.
Bei Tests mit Stichproben mit bekannter ZTZ-Konzentration erreichten alle vier Algorithmen (Bayes, SVM, LR und DNN) eine Genauigkeit von über 85 Prozent (Abbildung 2). Wir verbesserten die Genauigkeit, die Konsistenz und die Balance zwischen Sensitivität und Falsch-Positiv-Rate unserer Machine-Learning-Klassifikation weiter, indem wir Deep Learning mit einer globalen Optimierung der Receiver Operating Characteristics (ROC) kombinierten. Nachdem wir diesen innovativen Ansatz in MATLAB implementiert hatten, erhöhte er die Klassifikationsgenauigkeit auf 95,5 Prozent.
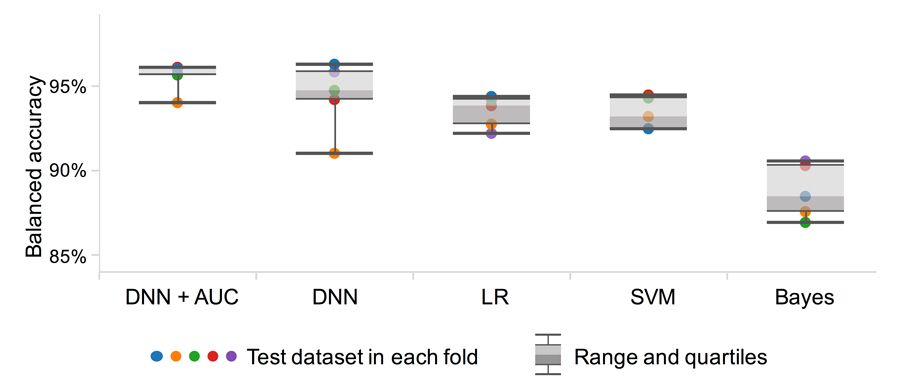
Abbildung 2: Vergleich der Genauigkeit verschiedener Machine-Learning-Techniken für die Klassifikation von Blutkörperchen.
Beschleunigung von Experimenten mit Parallel Computing
Da wir mit Big Data arbeiteten, benötigten wir häufig mehr als eine Woche, um unsere Bildverarbeitungs- und Machine-Learning-Prozesse abzuschließen. Um diese Ausführungsdauer zu verkürzen, parallelisierten wir unsere Analysen mit einem 16-Core-Prozessor und der Parallel Computing Toolbox™. Mithilfe einer einfachen parallelen For-Schleife (parfor) führten wir unsere Prozesse gleichzeitig auf den 16 Prozessoren aus. Damit verringerten wir den Zeitaufwand für die Analyse von acht Tagen auf circa einen halben Tag.
Modellieren und Verfeinern des Versuchsaufbaus
Im Photoniklabor der UCLA ist MATLAB das Haupt-Arbeitstool für die Modellentwicklung und die Datenanalyse. Wir verwendeten MATLAB, um ein Modell des gesamten Versuchsaufbaus zu entwickeln, von den optischen Geräten und den Laserimpulsen bis hin zur Klassifikation einzelner Zellen (Abbildung 3).

Abbildung 3: Diagramm des Systems für Time Stretch Quantitative Phase Imaging und Analyse.
Dieses Modell verwendeten wir als Grundlage für Verbesserungen unseres Versuchsaufbaus. Um beispielsweise das Signal-Rausch-Verhältnis zu verbessern, verwendeten wir das Modell zur Simulation spezifischer Laserverstärkungs-Koeffizienten. Die Simulationsergebnisse zeigten uns, wie und wo Veränderungen des Aufbaus die Gesamtleistung verbessern konnten.
Indem wir das System in MATLAB modelliert und simuliert haben, haben wir Monate für Experimente gespart, und wir haben eine Grundlage für unsere nächsten Schritte gewonnen. Wir integrieren zurzeit detaillierte Modelle einzelner Zellen in das Modell des Gesamtsystems. Mit diesen Modellen werden wir in der Lage sein, anhand der Arten der zu klassifizierenden Zellen fundiertere Kompromisse zwischen der räumlichen Auflösung und der Phasenauflösung einzugehen.
Das System, das wir entwickelt haben, kann nicht nur Krebszellen klassifizieren. Wir haben es auch verwendet, um Zellen von Algen anhand ihres Fettanteils und ihrer Eignung als Biokraftstoffe zu klassifizieren. Die einzige wesentliche Veränderung, die wir dafür vorgenommen haben, betraf die Oberflächenbeschichtung in dem Kanal, durch den die Zellen fließen. Nicht geändert haben wir die Machine-Learning-Pipeline, die der Analyse zugrunde liegt (Abbildung 4). Sie lernte eigenständig, dass für die Klassifikation von Algenzellen Merkmale optischer Verluste und Phasen wichtiger waren als morphologische Merkmale, während für Krebszellen das Gegenteil der Fall war.
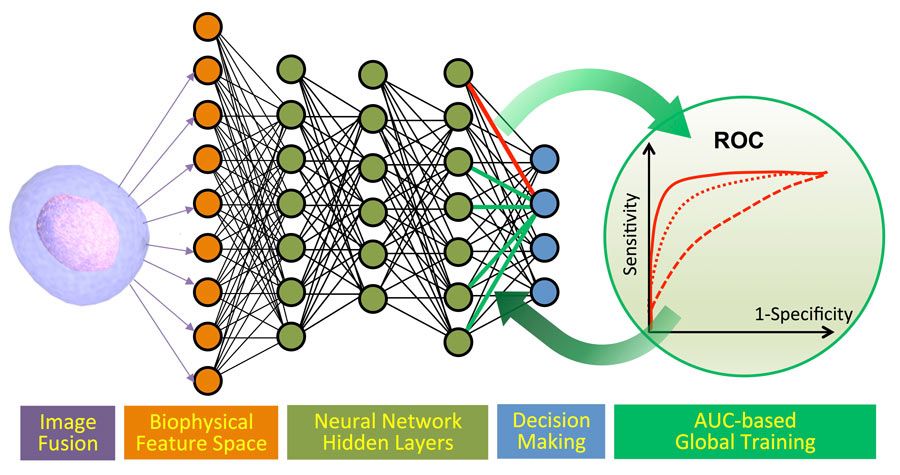
Abbildung 4: Machine-Learning-Pipeline: Klassifikation von Krebszellen und Algenzellen.
Funktionsweise von Photonic Time Stretch
Das TS-QPI-System erzeugt eine Abfolge von Laserimpulsen, deren Dauer im Femtosekunden-Bereich liegt. Linsen, Beugungsgitter, Spiegel und ein Strahlteiler zerstreuen die Laserimpulse zu einer Abfolge von Blitzen in Regenbogenfarben, die die Zellen beleuchten, die das Zytometer durchlaufen. Räumliche Informationen zu jeder Zelle sind im Spektrum eines Impulses codiert. Die optische Streuung erzeugt unterschiedliche Verzögerungen für unterschiedliche Wellenlängenanteile. Indem die Signale auf diese Weise optisch verarbeitet werden, werden sie ausreichend verlangsamt, um sie in Echtzeit mit einem elektronischen Analog-Digital-Wandler (ADC) umwandeln zu können.
Die relativ niedrige Anzahl Photonen, die während der kurzen Impulsdauer erfasst werden, und der Abfall optischer Leistung, der durch den Time Stretch verursacht wird, erschweren die Erkennung des entstehenden Signals. Diesen Sensitivitätsverlust kompensieren wir mithilfe eines Raman-Verstärkers. Da wir das Signal verlangsamen und gleichzeitig verstärken, kann das System zugleich Bilder für die quantitative optische Phasenverschiebung und den Intensitätsverlust für jede Zelle in der Stichprobe erfassen.
Veröffentlicht 2017 - 93090v00