embeddingConcatenationLayer
Description
An embedding concatenation layer combines its input and an embedding vector by concatenation.
Creation
Description
layer = embeddingConcatenationLayer
layer = embeddingConcatenationLayer(Name=Value)Name properties using one or more name-value arguments.
Properties
Examples
Create an embedding concatenation layer.
layer = embeddingConcatenationLayer
layer =
EmbeddingConcatenationLayer with properties:
Name: ''
InputSize: 'auto'
WeightsInitializer: 'narrow-normal'
WeightLearnRateFactor: 1
WeightL2Factor: 1
Learnable Parameters
Weights: []
State Parameters
No properties.
Show all properties
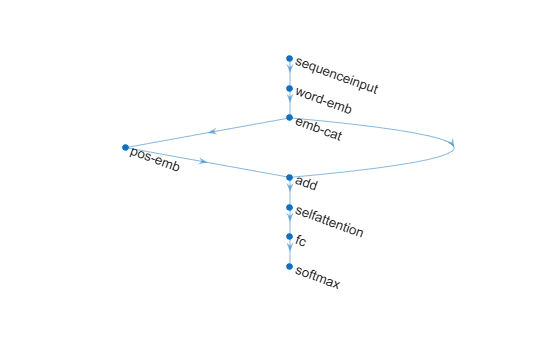
Include an embedding concatenation layer in a neural network.
net = dlnetwork;
numChannels = 1;
embeddingOutputSize = 64;
numWords = 128;
maxSequenceLength = 100;
maxPosition = maxSequenceLength+1;
numHeads = 4;
numKeyChannels = 4*embeddingOutputSize;
layers = [
sequenceInputLayer(numChannels)
wordEmbeddingLayer(embeddingOutputSize,numWords,Name="word-emb")
embeddingConcatenationLayer(Name="emb-cat")
positionEmbeddingLayer(embeddingOutputSize,maxPosition,Name="pos-emb");
additionLayer(2,Name="add")
selfAttentionLayer(numHeads,numKeyChannels,AttentionMask="causal")
fullyConnectedLayer(numWords)
softmaxLayer];
net = addLayers(net,layers);
net = connectLayers(net,"emb-cat","add/in2");View the neural network architecture.
plot(net) axis off box off
Algorithms
References
[1] Glorot, Xavier, and Yoshua Bengio. "Understanding the Difficulty of Training Deep Feedforward Neural Networks." In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, 249–356. Sardinia, Italy: AISTATS, 2010. https://proceedings.mlr.press/v9/glorot10a/glorot10a.pdf
[2] He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification." In 2015 IEEE International Conference on Computer Vision (ICCV), 1026–34. Santiago, Chile: IEEE, 2015. https://doi.org/10.1109/ICCV.2015.123
Extended Capabilities
Version History
Introduced in R2023b
See Also
selfAttentionLayer | attentionLayer | positionEmbeddingLayer | indexing1dLayer | embeddingLayer | trainnet | trainingOptions | dlnetwork