matlab.tall.reduce
Reduce arrays by applying reduction algorithm to blocks of data
Syntax
Description
tA = matlab.tall.reduce(fcn,reducefcn,tX,tY,...)tX,tY,... that are inputs to
fcn. The same rows of each array are operated on by
fcn; for example, fcn(tX(n:m,:),tY(n:m,:)). Inputs
with a height of one are passed to every call of fcn. With this syntax,
fcn must return one output, and reducefcn must
accept one input and return one output.
[
, where tA,tB,...] = matlab.tall.reduce(fcn,reducefcn,tX,tY,...)fcn and reducefcn are functions that return
multiple outputs, returns arrays tA,tB,..., each corresponding to one of
the output arguments of fcn and reducefcn. This syntax
has these requirements:
fcnmust return the same number of outputs as were requested frommatlab.tall.reduce.reducefcnmust have the same number of inputs and outputs as the number of outputs requested frommatlab.tall.reduce.Each output of
fcnandreducefcnmust be the same type as the first inputtX.Corresponding outputs of
fcnandreducefcnmust have the same height.
Examples
Input Arguments
Output Arguments
More About
When you create a tall array from a datastore, the underlying datastore
facilitates the movement of data during a calculation. The data moves in discrete pieces
called blocks or chunks, where each block is a set
of consecutive rows that can fit in memory. For example, one block of a 2-D array (such as a
table) is X(n:m,:), for some subscripts n and
m. The size of each block is based on the value of the
ReadSize property of the datastore, but the block might not be exactly
that size. For the purposes of matlab.tall.reduce, a tall array is
considered to be the vertical concatenation of many such blocks:
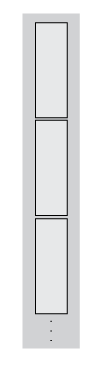
For example, if you use the sum function as the transform function,
the intermediate result is the sum per block. Therefore, instead of
returning a single scalar value for the sum of the elements, the result is a vector with
length equal to the number of
blocks.
ds = tabularTextDatastore('airlinesmall.csv','TreatAsMissing','NA'); ds.SelectedVariableNames = {'ArrDelay' 'DepDelay'}; tt = tall(ds); tX = tt.ArrDelay; f = @(x) sum(x,'omitnan'); s = matlab.tall.reduce(f, @(x) x, tX); s = gather(s)
s =
140467
101065
164355
135920
111182
186274
21321Version History
Introduced in R2018b