Train Reinforcement Learning Agents
Once you have created an environment and reinforcement learning agent, you can train the
agent in the environment using the train function. To
configure your training, use an rlTrainingOptions
object. For example, create a training option object opt.
opt = rlTrainingOptions( ... MaxEpisodes=1000, ... MaxStepsPerEpisode=1000, ... StopTrainingCriteria="AverageReward", ... StopTrainingValue=480);
Then train agent agent in environment env, using
the training options object opt.
trainResults = train(agent,env,opt);
If env is a multiagent environment specify the agent argument as an
array. The order of the agents in the array must match the agent order used to create
env. For multiagent training, use rlMultiAgentTrainingOptions instead of rlTrainingOptions.
Using rlMultiAgentTrainingOptions gives you access to training options that are specific
to multiagent training. For more information about multiagent training, see Multiagent Training.
Note
Calling clear all negatively affects performance. Use clear instead.
For more information on creating agents, see Reinforcement Learning Agents. For more information on creating environments, see Reinforcement Learning Environments and Create Custom Simulink Environments.
Note
The train function updates the input argument
agent as training progresses. This is possible because agents are
handle objects. To preserve the original agent parameters for later use, save the agent to a
MAT
file:
save("initialAgent.mat","agent")
Training terminates automatically when the conditions you specify in the
StopTrainingCriteria and StopTrainingValue options
of your rlTrainingOptions object are satisfied. You can also terminate
training before any termination condition is reached by clicking Stop
Training in Reinforcement Learning Training Monitor.
When training terminates the training statistics and results are stored in the
trainResults object (unless you interrupt training by pressing
Ctrl-C at the MATLAB® command line.
Because train updates the
agent at the end of each episode, and because trainResults stores the last
training results along with data to correctly recreate the training scenario and update
Reinforcement Learning Training Monitor, you can later resume training from the
exact point at which it stopped. To do so, at the command line,
type:
trainResults = train(agent,env,trainResults);
train call.The TrainingOptions property of
trainResults contains the rlTrainingOptions object that
specifies the training option set. Therefore, to restart the training with updated training
options, first change the training options in trainResults using dot
notation. If the maximum number of episodes was already reached in the previous training
session, you must increase the maximum number of episodes.
For example, disable displaying the training progress on Reinforcement Learning
Training Monitor, enable the Verbose option to display training
progress at the command line, change the maximum number of episodes to 2000, and then restart
the training, returning a new trainResults object as output.
trainResults.TrainingOptions.MaxEpisodes = 2000;
trainResults.TrainingOptions.Plots = "none";
trainResults.TrainingOptions.Verbose = 1;
trainResultsNew = train(agent,env,trainResults);Note
When training terminates, agent reflects the state of each agent
at the end of the final training episode. The rewards obtained by the final agents are not
necessarily the highest achieved during the training process, due to continuous
exploration. To save agents during training, create an rlTrainingOptions
object specifying the SaveAgentCriteria and SaveAgentValue
properties and pass it to train as a trainOpts
argument. For information on how to evaluate agent, see Evaluate Agents During Training.
Training Algorithm
In general, training performs the following steps.
Initialize the agent.
For each episode:
Reset the environment.
Get the initial observation S0 from the environment.
Compute the initial action A0 = μ(S0), where μ(S) is an action selected according to the current policy π(A|S).
Set the current action to the initial action (A←A0), and set the current observation to the initial observation (S←S0).
While the episode is not finished or terminated, perform the following steps.
Apply action A to the environment and obtain the next observation S''and the reward R.
Learn from the experience set (S,A,R,S').
Compute the next action A' = μ(S').
Update the current action with the next action (A←A') and update the current observation with the next observation (S←S').
Terminate the episode if the termination conditions defined in the environment are met.
If the training termination condition is met, terminate training. Otherwise, begin the next episode.
The specifics of how the software performs these steps depend on the configuration of the agent and environment. For instance, resetting the environment at the start of each episode can include randomizing initial state values, if you configure your environment to do so. For more information on agents and their training algorithms, see Reinforcement Learning Agents. To use parallel processing and GPUs to speed up training, see Train Agents Using Parallel Computing and GPUs.
Reinforcement Learning Training Monitor
By default, calling the train function opens the Reinforcement
Learning Training Monitor, which lets you visualize the training progress.
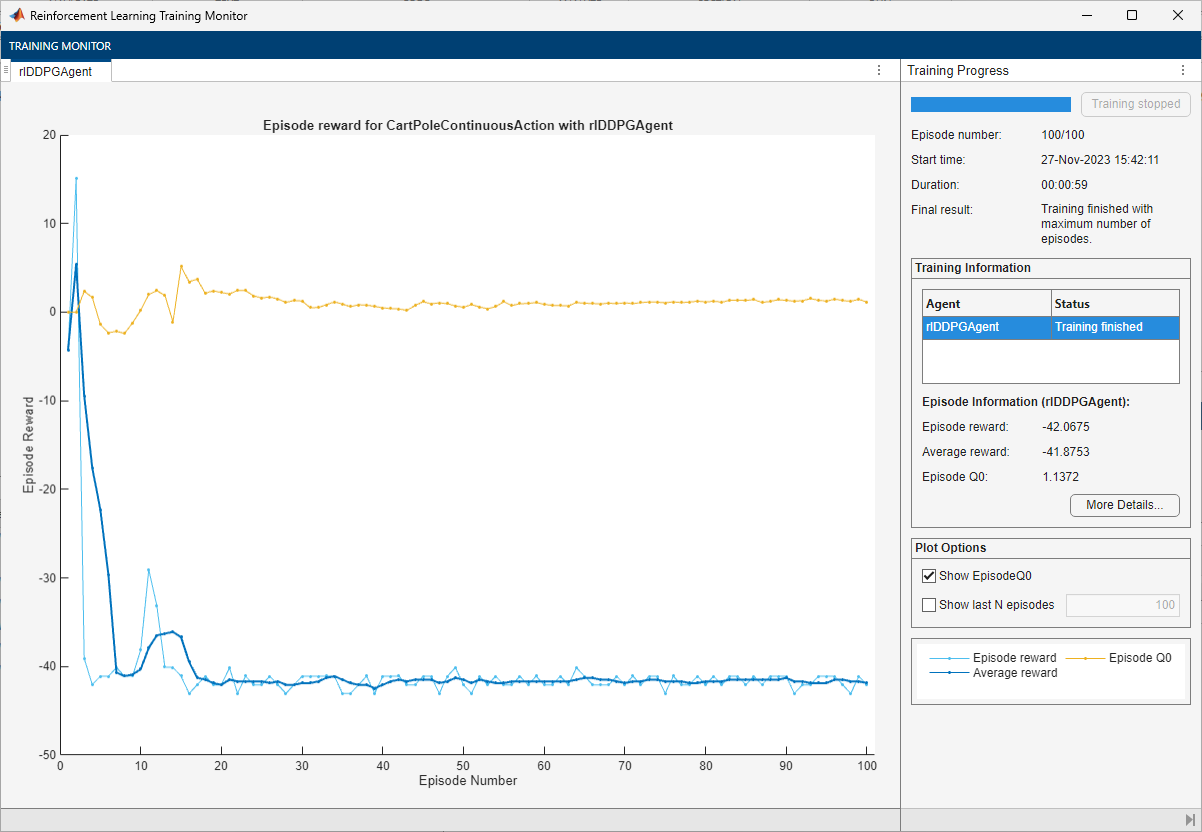
The Reinforcement Learning Training Monitor plot shows the reward for each episode (EpisodeReward) and a running average reward value (AverageReward).
For agents with a critic, Episode Q0 is the estimate of the
discounted long-term reward at the start of each episode, given the initial observation of
the environment. As training progresses, if the critic is well designed and learns
successfully, Episode Q0 approaches in average the true discounted
long-term reward, which might be offset from the EpisodeReward value
because of discounting. For a well designed critic using an undiscounted reward
(DiscountFactor is equal to 1), then on average
Episode Q0 approaches the true episode reward, as shown in the
preceding figure.
The Reinforcement Learning Training Monitor also displays several episode and training
statistics. You can also use the train function to return episode and
training information. To prevent displaying the training information with the Reinforcement
Learning Training Monitor, set the Plots option of
rlTrainingOptions to "none".
Save Candidate Agents During Training
During training, you can save candidate agents that meet conditions you specify in the
SaveAgentCriteria and SaveAgentValue options of
your rlTrainingOptions object. For instance, you can save any agent whose
episode reward exceeds a certain value, even if the overall condition for terminating
training is not yet satisfied. For example, save agents when the episode reward is greater
than 100.
opt = rlTrainingOptions(SaveAgentCriteria="EpisodeReward",SaveAgentValue=100);train stores saved agents in a MAT file in the folder you specify
using the SaveAgentDirectory option of
rlTrainingOptions. Saved agents can be useful, for instance, to test
candidate agents generated during a long-running training process. For details about saving
criteria and saving location, see rlTrainingOptions.
After training is complete, you can save the final trained agent from the MATLAB workspace using the save function. For example, save the
agent myAgent to the file finalAgent.mat in the
current working directory.
save(opt.SaveAgentDirectory + "/finalAgent.mat",'agent')
By default, when DDPG and DQN agents are saved, the experience buffer data is not saved.
If you plan to further train your saved agent, you can start training with the previous
experience buffer as a starting point. In this case, set the
SaveExperienceBufferWithAgent option to true. For
some agents, such as those with large experience buffers and image-based observations, the
memory required for saving the experience buffer is large. In these cases, you must ensure
that enough memory is available for the saved agents.
Validate Trained Agent
To validate your trained agent, you can simulate the agent within the training
environment using the sim function. To
configure the simulation, use rlSimulationOptions.
When validating your agent, consider checking how your agent handles the following:
Changes to simulation initial conditions — To change the model initial conditions, modify the reset function for the environment. For example, reset functions, see Create Custom Environment Using Step and Reset Functions, Create Custom Environment from Class Template, and Create Custom Simulink Environments.
Mismatches between the training and simulation environment dynamics — To check such mismatches, create test environments in the same way that you created the training environment, modifying the environment behavior.
As with parallel training, if you have Parallel Computing Toolbox™ software, you can run multiple parallel simulations on multicore computers. If
you have MATLAB
Parallel Server™ software, you can run multiple parallel simulations on computer clusters or
cloud resources. For more information on configuring your simulation to use parallel
computing, see UseParallel and
ParallelizationOptions in rlSimulationOptions.
Address Memory Issues During Training
Some Simulink® environments save a considerable amount of data when running. Specifically, by
default, the software saves anything that appears as the output of a sim (Simulink) command. This can cause out-of-memory issues when training or simulating
an agent in this kind of environment. You can use three training (or simulation) options to
prevent memory-related problems:
SimulationStorageType— This option specifies the type of storage used for data generated during training or simulation by a Simulink environment. The default value is"memory", indicating that data is stored in memory. To store environment data to disk instead, set this option to"file". When this option is set to"none"environment data is not stored.SaveSimulationDirectory— This option specifies the directory to save environment data whenSimulationStorageTypeis set to"file". The default value is"savedSims".SaveFileVersion— This option specifies the MAT file version for environment data. The default is"-v7". The other possible options are"-v7.3"and"-v6".
For more information, see rlTrainingOptions,
rlMultiAgentTrainingOptions, rlEvolutionStrategyTrainingOptions, and rlSimulationOptions.
Visualize Environment State During Training
If your MATLAB-based environment implements the plot method, you can
visualize the environment behavior during training and simulation. If you call
plot(env) before training or simulation, where env
is your environment object, then the visualization updates during training to allow you to
visualize the progress of each episode or simulation.
Environment visualization is not supported when training or simulating your agent using parallel computing.
Note
Environment visualization or training progress visualization increases training time. Therefore, for faster training, do not enable any visualization.
For custom MATLAB-based environments, you must implement your own plot
method. For more information on creating a custom environments with a
plot function, see Create Custom Environment from Class Template.
Evaluate Agents During Training
You can automatically evaluate your agent at regular intervals during training. Doing so allows you to observe the actual training progress and automatically stop the training or save the agent when some pre-specified conditions are met.
To configure evaluation options for your agents, first create an evaluator object using
rlEvaluator. You can
specify properties such as the type of evaluation statistic, the frequency at which
evaluation episodes occur, or whether exploration is allowed during an evaluation episode.
To train the agents and evaluate them during training, pass this object to train.
You can also create a custom evaluator object, which uses a custom evaluation function
that you supply. To do so, use rlCustomEvaluator.
For more information, see also the EvaluationStatistic of train.
Train Agent Offline from a Data Set
You can train off-policy agents (DQN, SAC, DDPG, and TD3) offline, using an existing dataset, instead of an environment.
To train your agent from an existing dataset, first, use rlTrainingFromDataOptions to create a training from data option object. Then
pass this option object (along with the environment and agent) to trainFromData to
train your agent.
To deal with possible differences between the probability distribution of the dataset
and the one generated by the environment, use the batch data regularization options provided
for off-policy agents. For more information, see the new
BatchDataRegularizerOptions property of the off-policy agents options
objects, as well as the new rlBehaviorCloningRegularizerOptions and rlConservativeQLearningOptions options objects.
Use Evolutionary Strategies
You can train DDPG, TD3 and SAC agents using an evolutionary algorithm.
Evolutionary reinforcement learning adaptation strategies update the weights of your agents using a selection process inspired by biological evolution. Compared to gradient-based approaches, evolutionary algorithms are less reliant on backpropagation, are easily parallelizable, and have a reduced sensitivity to local minima. They also generally display good (nonlocal) exploration and robustness, especially in complex scenarios where data is incomplete or noisy and rewards are sparse or conflicting.
To train your agent using an evolutionary algorithm, first, use rlEvolutionStrategyTrainingOptions to create an evolution strategy training
option object. Then pass this option object (along with the environment and agent) to
trainWithEvolutionStrategy to train your agent.
For an example, see Train Biped Robot to Walk Using Evolution Strategy-Reinforcement Learning Agents.
Multiagent Training
You can train multiple agents that work together in the same environment. For more information on loading predefined multiagent environments, see Use Predefined Multiagent Environments.
You can also create a custom multiagent environment. Specifically, using MATLAB functions, you can create two different kinds of custom multiagent environments:
Multiagent environments with universal sample time, in which all agents execute in the same step. You can create these environments by supplying your own reset and step functions, as well as observations and action specifications, to
rlMultiAgentFunctionEnv.Turn-based function environments, in which agents execute in turns. Specifically, the environment assigns execution to only one group of agents at a time, and the group executes when it is its turn to do so. You can create these environments by supplying your own reset and step functions, as well as observations and action specifications, to
rlTurnBasedFunctionEnv. For an example, see Train Agent to Play Turn-Based Game.
For both kinds of multiagent environments, the observation and action specifications are cell arrays of specification objects in which each element corresponds to one agent.
You can also create a custom multiagent Simulink environment (this option allows you to model environments with multi-rate execution, in which each agent might have its own execution rates).
To create a custom multiagent Simulink, first, create a Simulink model that has one action input and one set of outputs (observation, reward
and is-done) for every agent. Then manually add an agent block for each agent. Once you
connect the blocks, create an environment object using rlSimulinkEnv.
Unless each agent block already references an agent object in the MATLAB workspace, you must supply to rlSimulinkEnv two
cell arrays containing the observation action specification objects, respectively, as input
arguments. For an example, see Train Multiple Agents to Perform Collaborative Task.
Once you have created your multiagent environment, specify options for multiagent
training by creating and configuring an rlMultiAgentTrainingOptions object. Doing so allows you to specify, for example,
whether different groups of agents are trained in a decentralized or centralized manner. In
a group of agents subject to decentralized training, each agent collects its own set of
experiences and learns from its own set of experiences. In a group of agents subject to
centralized training, each agent shares its experiences with the other agents in the group
and each agent in the group learns from the collective shared experiences. In general,
centralized learning boosts exploration and facilitates learning in applications where the
agents perform a collaborative (or the same) task.
Once you have your multiagent environment and multiagent training options object, you
can train and simulate your agents with is using train and sim, respectively.
You can visualize the training progress of all the agents using the Reinforcement Learning
Training Manager.
For more examples on training multiple agents, see also Train Multiple Agents for Area Coverage, and Train Multiple Agents for Path Following Control.
Why Is My Training Not Converging?
In general, reinforcement learning algorithms cannot be guaranteed to converge even to a vicinity of a local optimum, unless many assumptions on the environment, the algorithm, and the function approximator are verified. Typically such assumption involve availability of the environment state, finite state and action spaces, known dynamics, tabular or linear function approximation, appropriate (and decaying) exploration and learning rate.
In practice, there might be many reasons why training does not converge to a satisfying solution.
Insufficient exploration: If the agent does not explore different actions and states adequately, it might not discover the optimal policy. Insufficient exploration can lead to suboptimal results or getting stuck in local optima.
High-dimensional state or action spaces: When the state or action space is large, it becomes challenging for the agent to explore and learn effectively. The curse of dimensionality can make it difficult to find an optimal policy within a reasonable time frame.
Function approximation limitations: It is important to consider whether your function approximator can properly approximate your value functions or policy, while at the same time being able to properly generalize from experience, otherwise, convergence issues can arise. Note that unavoidable approximation errors arise when observation signals are not adequately selected. For more information on selecting good observation signals, see the observation section of Define Observation and Reward Signals in Custom Environments.
Improperly scaled observation or action signals: Signals with widely different ranges can skew the learning process, making it hard for your approximator to successfully learn the important features. To prevent scaling problems, normalize the observations to a consistent scale. Common normalization techniques include scaling the observations to the range [0, 1] or standardizing them with zero mean and unit variance.
Poorly designed reward signal: The reward signal plays a crucial role in reinforcement learning. If the rewards are not properly designed or do not reflect the desired behavior, the agent might struggle to learn the optimal policy. Inconsistent or sparse rewards can make the learning process unstable or slow. For more information on selecting good reward signals, see the rewards section of Define Observation and Reward Signals in Custom Environments.
Inadequate training time or resources: Reinforcement learning algorithms often require extensive training time and computational resources to converge. If the training time or resources are limited, the algorithm might not have sufficient iterations to converge to the optimal policy. For more information on using parallel computing to train agents, see Train Agents Using Parallel Computing and GPUs.
Inappropriate algorithm or hyperparameters: Choosing an inappropriate algorithm or setting incorrect hyperparameters can significantly impact convergence. Different algorithms and hyperparameters might be more suitable for specific problem domains, and selecting the wrong ones can hinder convergence. For more information on selecting agents, see the last section of Reinforcement Learning Agents.
Non-stationary environments: If the environment in which the agent operates changes over time, the learning algorithm might struggle to adapt. Non-stationary environments can introduce additional challenges, requiring the algorithm to continuously update its policy to account for the changes.
To address these convergence issues, you can try to adjust the exploration-exploitation tradeoff, use better reward shaping, fine-tune hyperparameters, use an experience replay, or rely on more advanced algorithms.
Note
Choosing the right observation and action sets is crucial for effective training and performance in reinforcement learning. The observations should provide sufficient information about the current environment state for the agent to make informed decisions, and the actions should be able to adequately steer the environment behavior. For more information on selecting good observation and reward signals, see Define Observation and Reward Signals in Custom Environments.
Results Reproducibility
The results you obtain when training or simulating an agent in a reinforcement learning environment can be difficult to reproduce exactly. This happens because reinforcement learning algorithms are affected (to a greater extent than machine learning algorithms) by several arbitrary factors, which can typically be categorized as follows.
Randomness — Reinforcement learning algorithms typically depend on the values of random variables, which might be inconsistent across multiple runs unless the random seed is controlled explicitly before training. For example, the weights of the actor and critic networks and the state of the environments are typically initialized randomly. Reset functions called at the beginning of training and simulation often initialize the environment state randomly. Probabilistic environments, stochastic or exploration actions, random mini-batch sampling, are also sources of randomness. To learn about random number generation in MATLAB see Controlling Random Number Generation.
Hardware configuration — Numerical values might differ slightly between different platform or hardware settings. Differences in CPU/GPU architecture might also introduce discrepancies. Small numerical differences might add up to significant differences in training behavior. Furthermore, the closed-loop nature of the interaction between agent and environment in reinforcement learning means that when such closed loop is unstable small numerical differences might be amplified during training or simulation.
Software configuration — Changes made to Reinforcement Learning Toolbox™ software (as well as in component dependencies such as Deep Learning Toolbox™) might result in numerical differences from one release to the next. For example, improving an algorithm might require generating new random numbers or a calculating gradients in a more robust (but different) way, which might ultimately affect results. Thus, reproducibility across MATLAB releases cannot be guaranteed.
Additionally, asynchronous parallel training is generally not reproducible, because data is processed in a non-deterministic order, depending on the specific processors workload during training.
To enhance the extent to which your results can be reproduced on the same hardware and software configuration, you can adopt the following guidelines.
Set the random seed and generator type at the beginning of your script using the
rngcommand. Best practice is to directly specify the random number generation algorithm as inrng(s,"twister"), wheres, the seed, is a nonnegative integer. Avoid using the default generator (as inrng(s), orrng(s,"default")because the default seed and generator depend on the particular configuration set in the MATLAB Settings Window window.For synchronous parallel training, ensure that
trainOpts.ParallelizationOptions.WorkerRandomSeedsis not set to-2, because in this case the random stream of parallel workers is not initialized. Leave this property to the default-1(unique seed per worker) or specify a vector of unique nonnegative integers for best results.If you need to execute different sections of a script independently, set both the random number generator algorithm and the seed again at the beginning of each section. This practice preserves the random number sequence in the section every time you run it.
For examples on how to structure a training script for reproducibility, see Train Default DQN Agent to Balance Discrete Cart-Pole and, for parallel training, Quadruped Robot Locomotion Using DDPG Agent.
See Also
Apps
Functions
Objects
rlTrainingOptions|rlSimulationOptions|rlEvaluator|rlCustomEvaluator|rlTrainingFromDataOptions|rlEvolutionStrategyTrainingOptions|rlMultiAgentFunctionEnv|rlTurnBasedFunctionEnv
Topics
- Train Reinforcement Learning Agent in MDP Environment
- Train PG Agent with Custom Actor Network to Balance Discrete Cart-Pole
- Design and Train Agent Using Reinforcement Learning Designer
- Train Multiple Agents to Perform Collaborative Task
- Train Agent to Play Turn-Based Game
- Reinforcement Learning Workflow
- Reinforcement Learning Agents
- Train Agents Using Parallel Computing and GPUs