classify
Classify observations using discriminant analysis
Syntax
Description
Note
fitcdiscr and predict are recommended over classify for training a
discriminant analysis classifier and predicting labels. fitcdiscr
supports cross-validation and hyperparameter optimization, and does not require you to
fit the classifier every time you make a new prediction or change prior
probabilities.
class = classify(sample,training,group)sample into one of the groups to
which the data in training belongs. The groups for
training are specified by group. The function
returns class, which contains the assigned groups for each row of
sample.
[
also returns the apparent error rate (class,err,posterior,logp,coeff] = classify(___)err), posterior probabilities for
training observations (posterior), logarithm of the unconditional
probability density for sample observations (logp), and coefficients of
the boundary curves (coeff), using any of the input argument
combinations in previous syntaxes.
Examples
Load the fisheriris data set. Create group as a cell array of character vectors that contains the iris species.
load fisheriris
group = species;The meas matrix contains two sepal and two petal measurements for 150 irises. Randomly partition observations into a training set (trainingData) and a sample set (sampleData) with stratification, using the group information in group. Specify a 40% holdout sample for sampleData.
rng('default') % For reproducibility cv = cvpartition(group,'HoldOut',0.40); trainInds = training(cv); sampleInds = test(cv); trainingData = meas(trainInds,:); sampleData = meas(sampleInds,:);
Classify sampleData using linear discriminant analysis, and create a confusion chart from the true labels in group and the predicted labels in class.
class = classify(sampleData,trainingData,group(trainInds)); cm = confusionchart(group(sampleInds),class);
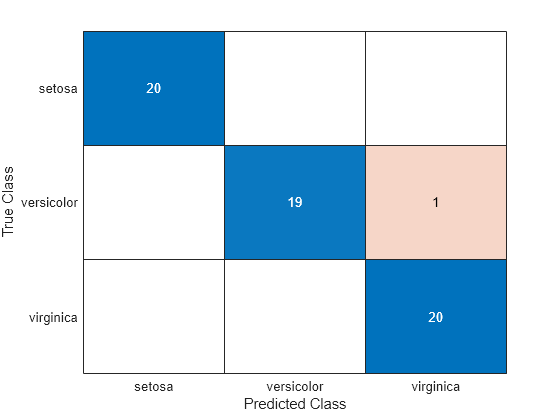
The classify function misclassifies one versicolor iris as virginica in the sample data set.
Classify the data points in a grid of measurements (sample data) by using quadratic discriminant analysis. Then, visualize the sample data, training data, and decision boundary.
Load the fisheriris data set. Create group as a cell array of character vectors that contains the iris species.
load fisheriris
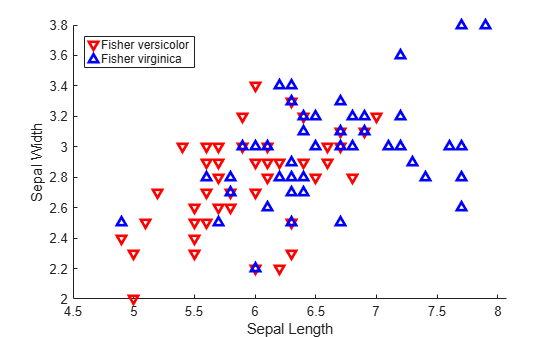
group = species(51:end);Plot the sepal length (SL) and width (SW) measurements for the iris versicolor and virginica species.
SL = meas(51:end,1); SW = meas(51:end,2); h1 = gscatter(SL,SW,group,'rb','v^',[],'off'); h1(1).LineWidth = 2; h1(2).LineWidth = 2; legend('Fisher versicolor','Fisher virginica','Location','NW') xlabel('Sepal Length') ylabel('Sepal Width')
Create sampleData as a numeric matrix that contains a grid of measurements. Create trainingData as a numeric matrix that contains the sepal length and width measurements for the iris versicolor and virginica species.
[X,Y] = meshgrid(linspace(4.5,8),linspace(2,4)); X = X(:); Y = Y(:); sampleData = [X Y]; trainingData = [SL SW];
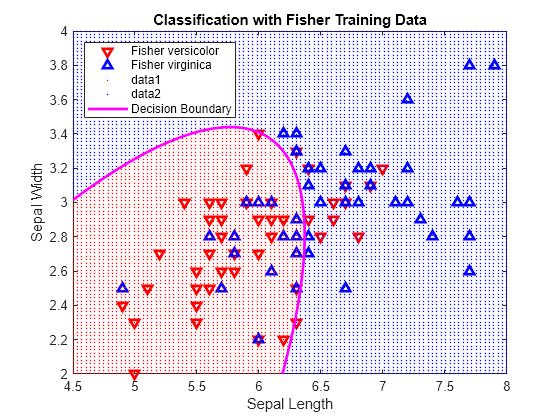
Classify sampleData using quadratic discriminant analysis.
[C,err,posterior,logp,coeff] = classify(sampleData,trainingData,group,'quadratic');Retrieve the coefficients K, L, and M for the quadratic boundary between the two classes.
K = coeff(1,2).const; L = coeff(1,2).linear; Q = coeff(1,2).quadratic;
The curve that separates the two classes is defined by this equation:
Visualize the discriminant classification.
hold on h2 = gscatter(X,Y,C,'rb','.',1,'off'); f = @(x,y) K + L(1)*x + L(2)*y + Q(1,1)*x.*x + (Q(1,2)+Q(2,1))*x.*y + Q(2,2)*y.*y; h3 = fimplicit(f,[4.5 8 2 4]); h3.Color = 'm'; h3.LineWidth = 2; h3.DisplayName = 'Decision Boundary'; hold off axis tight xlabel('Sepal Length') ylabel('Sepal Width') title('Classification with Fisher Training Data')
Partition a data set into sample and training data, and classify the sample data using linear discriminant analysis. Then, visualize the decision boundaries.
Load the fisheriris data set. Create group as a cell array of character vectors that contains the iris species. Create PL and PW as numeric vectors that contain the petal length and width measurements, respectively.
load fisheriris
group = species;
PL = meas(:,3);
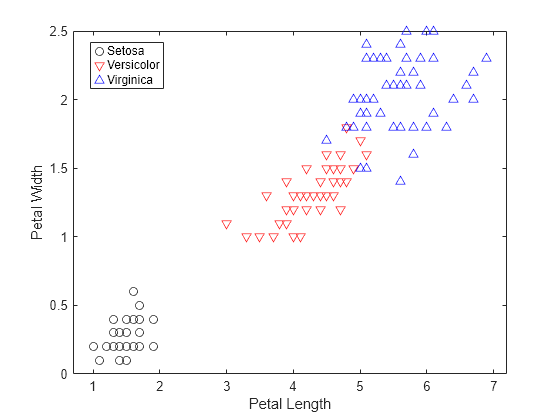
PW = meas(:,4);Plot the sepal length (PL) and width (PW) measurements for the iris setosa, versicolor, and virginica species.
h1 = gscatter(PL,PW,species,'krb','ov^',[],'off'); legend('Setosa','Versicolor','Virginica','Location','best') xlabel('Petal Length') ylabel('Petal Width')
Randomly partition observations into a training set (trainingData) and a sample set (sampleData) with stratification, using the group information in group. Specify a 10% holdout sample for sampleData.
rng('default') % For reproducibility cv = cvpartition(group,'HoldOut',0.10); trainInds = training(cv); sampleInds = test(cv); trainingData = [PL(trainInds) PW(trainInds)]; sampleData = [PL(sampleInds) PW(sampleInds)];
Classify sampleData using linear discriminant analysis.
[class,err,posterior,logp,coeff] = classify(sampleData,trainingData,group(trainInds));
Retrieve the coefficients K and L for the linear boundary between the second and third classes.
K = coeff(2,3).const; L = coeff(2,3).linear;
The line that separates the second and third classes is defined by the equation . Plot the boundary line between the second and third classes.
f = @(x1,x2) K + L(1)*x1 + L(2)*x2; hold on h2 = fimplicit(f,[.9 7.1 0 2.5]); h2.Color = 'r'; h2.DisplayName = 'Boundary between Versicolor & Virginica';
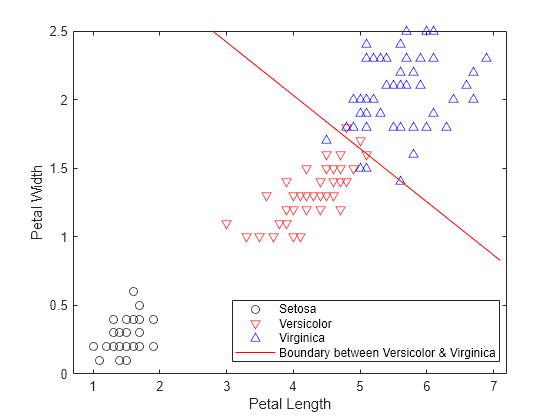
Retrieve the coefficients K and L for the linear boundary between the first and second classes.
K = coeff(1,2).const; L = coeff(1,2).linear;
Plot the line that separates the first and second classes.
f = @(x1,x2) K + L(1)*x1 + L(2)*x2; h3 = fimplicit(f,[.9 7.1 0 2.5]); hold off h3.Color = 'k'; h3.DisplayName = 'Boundary between Versicolor & Setosa'; axis tight title('Linear Classification with Fisher Training Data')

Input Arguments
Output Arguments
Alternative Functionality
The fitcdiscr function also performs discriminant
analysis. You can train a classifier by using the fitcdiscr function and
predict labels of new data by using the predict function. The fitcdiscr function supports
cross-validation and hyperparameter optimization, and does not require you to fit the
classifier every time you make a new prediction or change prior probabilities.
References
[1] Krzanowski, Wojtek. J. Principles of Multivariate Analysis: A User's Perspective. NY: Oxford University Press, 1988.
[2] Seber, George A. F. Multivariate Observations. NJ: John Wiley & Sons, Inc., 1984.
Version History
Introduced before R2006a