margin
Classification margins for naive Bayes classifier
Description
m = margin(Mdl,tbl,ResponseVarName)m) for the trained naive
Bayes classifier Mdl using the predictor data in table
tbl and the class labels in
tbl.ResponseVarName.
m = margin(Mdl,X,Y)Mdl using the predictor
data in matrix X and the class labels in
Y.
m is returned as a numeric vector with the same length as
Y. The software estimates each entry of
m using the trained naive Bayes classifier
Mdl, the corresponding row of X, and
the true class label Y.
Examples
Estimate Test Sample Classification Margins of Naive Bayes Classifier
Estimate the test sample classification margins of a naive Bayes classifier. An observation margin is the observed true class score minus the maximum false class score among all scores in the respective class.
Load the fisheriris data set. Create X as a numeric matrix that contains four petal measurements for 150 irises. Create Y as a cell array of character vectors that contains the corresponding iris species.
load fisheriris X = meas; Y = species; rng('default') % for reproducibility
Randomly partition observations into a training set and a test set with stratification, using the class information in Y. Specify a 30% holdout sample for testing.
cv = cvpartition(Y,'HoldOut',0.30);Extract the training and test indices.
trainInds = training(cv); testInds = test(cv);
Specify the training and test data sets.
XTrain = X(trainInds,:); YTrain = Y(trainInds); XTest = X(testInds,:); YTest = Y(testInds);
Train a naive Bayes classifier using the predictors XTrain and class labels YTrain. A recommended practice is to specify the class names. fitcnb assumes that each predictor is conditionally and normally distributed.
Mdl = fitcnb(XTrain,YTrain,'ClassNames',{'setosa','versicolor','virginica'})
Mdl =
ClassificationNaiveBayes
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
NumObservations: 105
DistributionNames: {'normal' 'normal' 'normal' 'normal'}
DistributionParameters: {3x4 cell}
Mdl is a trained ClassificationNaiveBayes classifier.
Estimate the test sample classification margins.
m = margin(Mdl,XTest,YTest); median(m)
ans = 1.0000
Display the histogram of the test sample classification margins.
histogram(m,length(unique(m)),'Normalization','probability') xlabel('Test Sample Margins') ylabel('Probability') title('Probability Distribution of the Test Sample Margins')
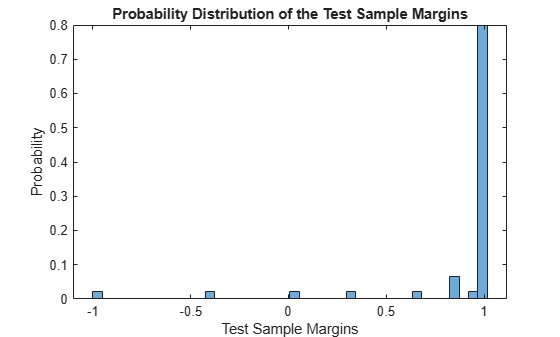
Classifiers that yield relatively large margins are preferred.
Select Naive Bayes Classifier Features by Examining Test Sample Margins
Perform feature selection by comparing test sample margins from multiple models. Based solely on this comparison, the classifier with the highest margins is the best model.
Load the fisheriris data set. Specify the predictors X and class labels Y.
load fisheriris X = meas; Y = species; rng('default') % for reproducibility
Randomly partition observations into a training set and a test set with stratification, using the class information in Y. Specify a 30% holdout sample for testing. Partition defines the data set partition.
cv = cvpartition(Y,'Holdout',0.30);Extract the training and test indices.
trainInds = training(cv); testInds = test(cv);
Specify the training and test data sets.
XTrain = X(trainInds,:); YTrain = Y(trainInds); XTest = X(testInds,:); YTest = Y(testInds);
Define these two data sets:
fullXcontains all predictors.partXcontains the last two predictors.
fullX = XTrain; partX = XTrain(:,3:4);
Train a naive Bayes classifier for each predictor set.
fullMdl = fitcnb(fullX,YTrain); partMdl = fitcnb(partX,YTrain);
fullMdl and partMdl are trained ClassificationNaiveBayes classifiers.
Estimate the test sample margins for each classifier.
fullM = margin(fullMdl,XTest,YTest); median(fullM)
ans = 1.0000
partM = margin(partMdl,XTest(:,3:4),YTest); median(partM)
ans = 1.0000
Display the distribution of the margins for each model using boxplots.
boxplot([fullM partM],'Labels',{'All Predictors','Two Predictors'}) ylim([0.98 1.01]) % Modify the y-axis limits to see the boxes title('Boxplots of Test Sample Margins')
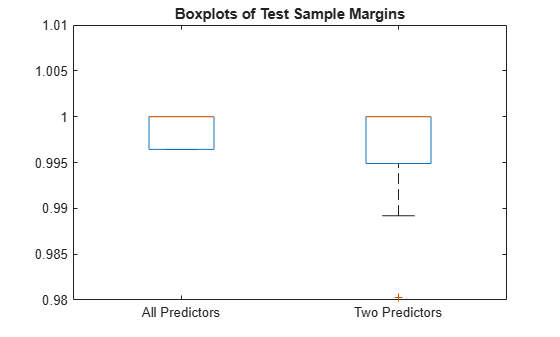
The margins for fullMdl (all predictors model) and partMdl (two predictors model) have a similar distribution with the same median. partMdl is less complex but has outliers.
Input Arguments
More About
Extended Capabilities
Version History
Introduced in R2014b
See Also
ClassificationNaiveBayes | CompactClassificationNaiveBayes | loss | predict | edge | fitcnb
You can also select a web site from the following list:
Americas
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)