updateMetrics
Update performance metrics in incremental drift-aware learning model given new data
Since R2022b
Description
Mdl = updateMetrics(Mdl,X,Y)Mdl, which is the
input incremental drift-aware learning model Mdl modified to contain
the model performance metrics on the incoming predictor and response data,
X and Y respectively.
When the input model is warm (Mdl.IsWarm is
true), updateMetrics overwrites previously computed
metrics, stored in the Metrics property, with the new values. Otherwise,
updateMetrics stores NaN values in
Metrics instead.
The input and output models have the same data type.
Mdl = updateMetrics(Mdl,X,Y,Name=Value)
Examples
Create the random concept data using the HelperSineGenerator and concept drift generator HelperConceptDriftGenerator.
concept1 = HelperSineGenerator("ClassificationFunction",1,"IrrelevantFeatures",true,"TableOutput",false); concept2 = HelperSineGenerator("ClassificationFunction",3,"IrrelevantFeatures",true,"TableOutput",false); driftGenerator = HelperConceptDriftGenerator(concept1,concept2,15000,1000);
When ClassificationFunction is 1, HelperSineGenerator labels all points that satisfy x1 < sin(x2) as 1, otherwise the function labels them as 0. When ClassificationFunction is 3, this is reversed. That is, HelperSineGenerator labels all points that satisfy x1 >= sin(x2) as 1, otherwise the function labels them as 0.
HelperConceptDriftGenerator establishes the concept drift. The object uses a sigmoid function 1./(1+exp(-4*(numobservations-position)./width)) to decide the probability of choosing the first stream when generating data [1]. In this case, the position argument is 15000 and the width argument is 1000. As the number of observations exceeds the position value minus half of the width, the probability of sampling from the first stream when generating data decreases. The sigmoid function allows a smooth transition from one stream to the other. Larger width values indicate a larger transition period where both streams are approximately equally likely to be selected.
Initiate an incremental drift-aware model as follows:
Create an incremental Naive Bayes classification model for binary classification.
Initiate an incremental concept drift detector that uses the Hoeffding's Bounds Drift Detection Method with moving average (HDDMA).
Using the incremental linear model and the concept drift detector, instantiate an incremental drift-aware model. Specify the training period as 5000 observations.
BaseLearner = incrementalClassificationLinear(Solver="sgd"); dd = incrementalConceptDriftDetector("hddma"); idaMdl = incrementalDriftAwareLearner(BaseLearner,DriftDetector=dd,TrainingPeriod=5000);
Preallocate the number of variables in each chunk and number of iterations for creating a stream of data.
numObsPerChunk = 10; numIterations = 4000;
Preallocate the variables for tracking the drift status and drift time, and storing the classification error.
dstatus = zeros(numIterations,1); statusname = strings(numIterations,1); ce = array2table(zeros(numIterations,2),VariableNames=["Cumulative" "Window"]); driftTimes = [];
Simulate a data stream with incoming chunks of 10 observations each and perform incremental drift-aware learning. At each iteration:
Simulate predictor data and labels, and update the drift generator using the helper function
hgenerate.Call
updateMetricsto measure the cumulative performance and the performance within a window of observations. Overwrite the previous incremental model with a new one to track performance metrics.Call
fitto fit the model to the incoming chunk. Overwrite the previous incremental model with a new one fitted to the incoming observations.Track and record the drift status and the classification error for visualization purposes.
rng(12); % For reproducibility for j = 1:numIterations % Generate data [driftGenerator,X,Y] = hgenerate(driftGenerator,numObsPerChunk); % Update performance metrics and fit the model idaMdl = updateMetrics(idaMdl,X,Y); idaMdl = fit(idaMdl,X,Y); % Record drift status and classification error statusname(j) = string(idaMdl.DriftStatus); ce{j,:} = idaMdl.Metrics{"ClassificationError",:}; if idaMdl.DriftDetected dstatus(j) = 2; driftTimes(end+1) = j; elseif idaMdl.WarningDetected dstatus(j) = 1; else dstatus(j) = 0; end end
Plot the cumulative and per window classification error. Mark the warmup and training periods, and where the drift was introduced.
h = plot(ce.Variables); xlim([0 numIterations]) ylim([0 0.08]) ylabel("Classification Error") xlabel("Iteration") xline((idaMdl.BaseLearner.EstimationPeriod+idaMdl.MetricsWarmupPeriod)/numObsPerChunk,"g-.","Estimation + Warmup Period",LineWidth=1.5) xline((idaMdl.MetricsWarmupPeriod+idaMdl.BaseLearner.EstimationPeriod)/numObsPerChunk+driftTimes,"g-.","Estimation Period + Warmup Period",LineWidth=1.5) xline(driftTimes,"m--","Drift",LabelVerticalAlignment="middle",LineWidth=1.5) legend(h,ce.Properties.VariableNames) legend(h,Location="best")
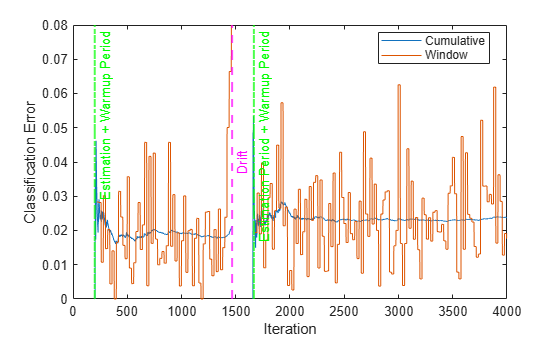
The plot suggests the following:
updateMetricscomputes the performance metrics after the estimation and metrics warm-up period only.updateMetricscomputes the cumulative metrics during each iteration.updateMetricscomputes the window metrics after processing the default metrics window size (200) observations.After drift detection
updateMetricsfunction waits foridaMdl.BaseLearner.EstimationPeriod+idaMdl.MetricsWarmupPeriodobservations to start updating model performance metrics again.
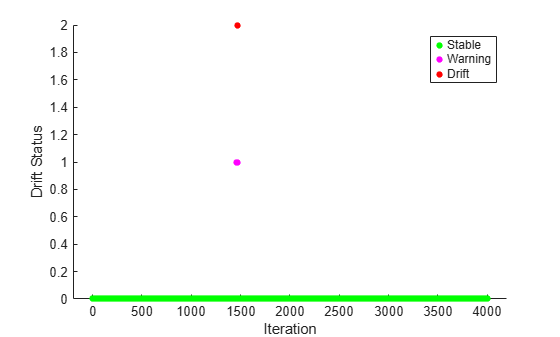
Plot the drift status versus the iteration number.
gscatter(1:numIterations,dstatus,statusname,'gmr','o',4,'on',"Iteration","Drift Status","Filled")
Input Arguments
Name-Value Arguments
Output Arguments
Algorithms
Version History
Introduced in R2022b
See Also
predict | perObservationLoss | fit | incrementalDriftAwareLearner | updateMetricsAndFit | loss