isanomaly
Syntax
Description
tf = isanomaly(LOFObj,Tbl)Tbl using the LocalOutlierFactor
object LOFObj and returns the logical array tf,
whose elements are true when an anomaly is detected in the corresponding
row of Tbl. You must use this syntax if you create
LOFObj by passing a table to the lof
function.
tf = isanomaly(___,Name=Value)scoreThreshold=0.5isanomaly to identify observations with scores above
0.5 as anomalies.
[
also returns an anomaly score, which is a local
outlier factor value, for each observation in tf,scores] = isanomaly(___)Tbl or
X. A score value less than or close to 1 indicates a normal
observation, and a value greater than 1 can indicate an anomaly.
Examples
Create a LocalOutlierFactor object for uncontaminated training observations by using the lof function. Then detect novelties (anomalies in new data) by passing the object and the new data to the object function isanomaly.
Load the 1994 census data stored in census1994.mat. The data set consists of demographic data from the US Census Bureau to predict whether an individual makes over $50,000 per year.
load census1994census1994 contains the training data set adultdata and the test data set adulttest. The predictor data must be either all continuous or all categorical to train a LocalOutlierFactor object. Remove nonnumeric variables from adultdata and adulttest.
adultdata = adultdata(:,vartype("numeric")); adulttest = adulttest(:,vartype("numeric"));
Train a local outlier factor model for adultdata. Assume that adultdata does not contain outliers.
[Mdl,tf,s] = lof(adultdata);
Mdl is a LocalOutlierFactor object. lof also returns the anomaly indicators tf and anomaly scores s for the training data adultdata. If you do not specify the ContaminationFraction name-value argument as a value greater than 0, then lof treats all training observations as normal observations, meaning all the values in tf are logical 0 (false). The function sets the score threshold to the maximum score value. Display the threshold value.
Mdl.ScoreThreshold
ans = 28.6719
Find anomalies in adulttest by using the trained local outlier factor model.
[tf_test,s_test] = isanomaly(Mdl,adulttest);
The isanomaly function returns the anomaly indicators tf_test and scores s_test for adulttest. By default, isanomaly identifies observations with scores above the threshold (Mdl.ScoreThreshold) as anomalies.
Create histograms for the anomaly scores s and s_test. Create a vertical line at the threshold of the anomaly scores.
h1 = histogram(s,NumBins=50,Normalization="probability"); hold on h2 = histogram(s_test,h1.BinEdges,Normalization="probability"); xline(Mdl.ScoreThreshold,"r-",join(["Threshold" Mdl.ScoreThreshold])) h1.Parent.YScale = 'log'; h2.Parent.YScale = 'log'; legend("Training Data","Test Data",Location="north") hold off
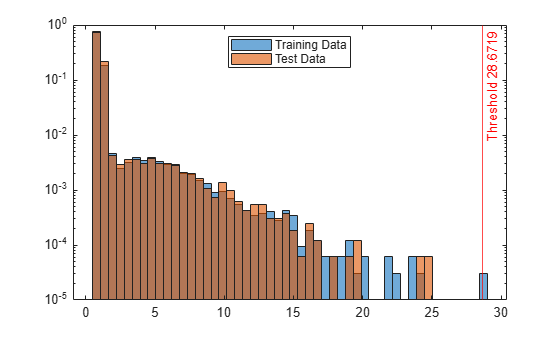
Display the observation index of the anomalies in the test data.
find(tf_test)
ans = 0×1 empty double column vector
The anomaly score distribution of the test data is similar to that of the training data, so isanomaly does not detect any anomalies in the test data with the default threshold value. You can specify a different threshold value by using the ScoreThreshold name-value argument. For an example, see Specify Anomaly Score Threshold.
Specify the threshold value for anomaly scores by using the ScoreThreshold name-value argument of isanomaly.
Load the 1994 census data stored in census1994.mat. The data set consists of demographic data from the US Census Bureau to predict whether an individual makes over $50,000 per year.
load census1994census1994 contains the training data set adultdata and the test data set adulttest.
Remove nonnumeric variables from adultdata and adulttest.
adultdata = adultdata(:,vartype("numeric")); adulttest = adulttest(:,vartype("numeric"));
Train a local outlier factor model for adultdata.
[Mdl,tf,scores] = lof(adultdata);
Plot a histogram of the score values. Create a vertical line at the default score threshold.
h = histogram(scores,NumBins=50,Normalization="probability"); h.Parent.YScale = 'log'; xline(Mdl.ScoreThreshold,"r-",join(["Threshold" Mdl.ScoreThreshold]))

Find the anomalies in the test data using the trained local outlier factor model. Use a different threshold from the default threshold value obtained when training the local outlier factor model.
First, determine the score threshold by using the isoutlier function.
[~,~,U] = isoutlier(scores)
U = 1.1567
Specify the value of the ScoreThreshold name-value argument as U.
[tf_test,scores_test] = isanomaly(Mdl,adulttest,ScoreThreshold=U); h = histogram(scores_test,NumBins=50,Normalization="probability"); h.Parent.YScale = 'log'; xline(U,"r-",join(["Threshold" U]))

Generate a sample data set that contains outliers. Compute anomaly scores for the points around the sample data by using the isanomaly function, and create a contour plot of the anomaly scores. Then, check the performance of the trained local outlier model by plotting the precision-recall curve.
Use a Gaussian copula to generate random data points from a bivariate distribution.
rng("default") rho = [1,0.05;0.05,1]; n = 1000; u = copularnd("Gaussian",rho,n);
Add noise to 5% of randomly selected observations to make the observations outliers.
noise = randperm(n,0.05*n); true_tf = false(n,1); true_tf(noise) = true; u(true_tf,1) = u(true_tf,1)*5;
Train a local outlier factor model by using the lof function. Set the fraction of anomalies in the training observations to 0.05. For better performance, you can also modify the local outlier factor algorithm options by specifying name-value arguments, such as SearchMethod, NumNeighbors, and Distance. In this case, specify the number of nearest neighbors to use as 40.
[LOFObj,tf,scores] = lof(u,ContaminationFraction=0.05,NumNeighbors=40);
Compute anomaly scores for 2-D grid coordinates around the training observations by using the trained local outlier factor model and the isanomaly function.
l1 = linspace(min(u(:,1),[],1),max(u(:,1),[],1)); l2 = linspace(min(u(:,2),[],1),max(u(:,2),[],1)); [X1,X2] = meshgrid(l1,l2); [~,scores_grid] = isanomaly(LOFObj,[X1(:),X2(:)]); scores_grid = reshape(scores_grid,size(X1,1),size(X2,2));
Create a scatter plot of the training observations and a contour plot of the anomaly scores. Flag true outliers and the outliers detected by lof.
idx = setdiff(1:1000,noise); scatter(u(idx,1),u(idx,2),[],[0.5 0.5 0.5],".") hold on scatter(u(noise,1),u(noise,2),"ro","filled") scatter(u(tf,1),u(tf,2),60,"kx",LineWidth=1) contour(X1,X2,scores_grid,"ShowText","on") legend(["Normal Points" "Outliers" "Detected Outliers"],Location="best") colorbar hold off

Check the performance of the trained local outlier factor model by plotting the precision-recall curve and computing the area under the curve (AUC) value. Create a rocmetrics object. rocmetrics computes the false positive rates and the true positive rates (or recall) by default. Specify the AdditionalMetrics name-value argument to additionally compute the precision values (or positive predictive values).
rocObj = rocmetrics(true_tf,scores,true,AdditionalMetrics="PositivePredictiveValue");Plot the curve by using the plot function of rocmetrics. Specify the y-axis metric as precision (or positive predictive value) and the x-axis metric as recall (or true positive rate). Display a filled circle at the model operating point corresponding to LOFObj.ScoreThreshold. Compute the area under the precision-recall curve using the trapezoidal method of the trapz function, and display the value in the legend.
r = plot(rocObj,YAxisMetric="PositivePredictiveValue",XAxisMetric="TruePositiveRate"); hold on idx = find(rocObj.Metrics.Threshold>=LOFObj.ScoreThreshold,1,'last'); scatter(rocObj.Metrics.TruePositiveRate(idx), ... rocObj.Metrics.PositivePredictiveValue(idx), ... [],r.Color,"filled") xyData = rmmissing([r.XData r.YData]); auc = trapz(xyData(:,1),xyData(:,2)); legend(join([r.DisplayName " (AUC = " string(auc) ")"],""),"true Model Operating Point") xlabel("Recall") ylabel("Precision") title("Precision-Recall Curve") hold off

Input Arguments
Name-Value Arguments
Output Arguments
More About
Algorithms
To compute the local outlier factor values (
scores) for each observation inTblorX,isanomalyfinds the k-nearest neighbors among the training observations stored in theXproperty of aLocalOutlierFactorobject.isanomalyconsidersNaN,''(empty character vector),""(empty string),<missing>, and<undefined>values inTblandNaNvalues inXto be missing values.isanomalydoes not use observations with missing values.isanomalyassigns the anomaly score ofNaNand anomaly indicator offalse(logical 0) to observations with missing values.
References
[1] Breunig, Markus M., et al. “LOF: Identifying Density-Based Local Outliers.” Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, 2000, pp. 93–104.