lof
Syntax
Description
Use the lof function to create a local
outlier factor model for outlier detection and novelty detection.
Outlier detection (detecting anomalies in training data) — Use the output argument
tfoflofto identify anomalies in training data.Novelty detection (detecting anomalies in new data with uncontaminated training data) — Create a
LocalOutlierFactorobject by passing uncontaminated training data (data with no outliers) tolof. Detect anomalies in new data by passing the object and the new data to the object functionisanomaly.
LOFObj = lof(Tbl)LocalOutlierFactor
object for predictor data in the table Tbl.
LOFObj = lof(___,Name=Value)ContaminationFraction=0.1
Examples
Detect outliers (anomalies in training data) by using the lof function.
Load the sample data set NYCHousing2015.
load NYCHousing2015The data set includes 10 variables with information on the sales of properties in New York City in 2015. Display a summary of the data set.
summary(NYCHousing2015)
NYCHousing2015: 91446×10 table
Variables:
BOROUGH: double
NEIGHBORHOOD: cell array of character vectors
BUILDINGCLASSCATEGORY: cell array of character vectors
RESIDENTIALUNITS: double
COMMERCIALUNITS: double
LANDSQUAREFEET: double
GROSSSQUAREFEET: double
YEARBUILT: double
SALEPRICE: double
SALEDATE: datetime
Statistics for applicable variables:
NumMissing Min Median Max Mean Std
BOROUGH 0 1 3 5 2.8431 1.3343
NEIGHBORHOOD 0
BUILDINGCLASSCATEGORY 0
RESIDENTIALUNITS 0 0 1 8759 2.1789 32.2738
COMMERCIALUNITS 0 0 0 612 0.2201 3.2991
LANDSQUAREFEET 0 0 1700 29305534 2.8752e+03 1.0118e+05
GROSSSQUAREFEET 0 0 1056 8942176 4.6598e+03 4.3098e+04
YEARBUILT 0 0 1939 2016 1.7951e+03 526.9998
SALEPRICE 0 0 333333 4.1111e+09 1.2364e+06 2.0130e+07
SALEDATE 0 01-Jan-2015 09-Jul-2015 31-Dec-2015 07-Jul-2015 2470:47:17
Remove nonnumeric variables from NYCHousing2015. The data type of the BOROUGH variable is double, but it is a categorical variable indicating the borough in which the property is located. Remove the BOROUGH variable as well.
NYCHousing2015 = NYCHousing2015(:,vartype("numeric"));
NYCHousing2015.BOROUGH = [];Train a local outlier factor model for NYCHousing2015. Specify the fraction of anomalies in the training observations as 0.01.
[Mdl,tf,scores] = lof(NYCHousing2015,ContaminationFraction=0.01);
Mdl is a LocalOutlierFactor object. lof also returns the anomaly indicators (tf) and anomaly scores (scores) for the training data NYCHousing2015.
Plot a histogram of the score values. Create a vertical line at the score threshold corresponding to the specified fraction.
h = histogram(scores,NumBins=50); h.Parent.YScale = 'log'; xline(Mdl.ScoreThreshold,"r-",["Threshold" Mdl.ScoreThreshold])
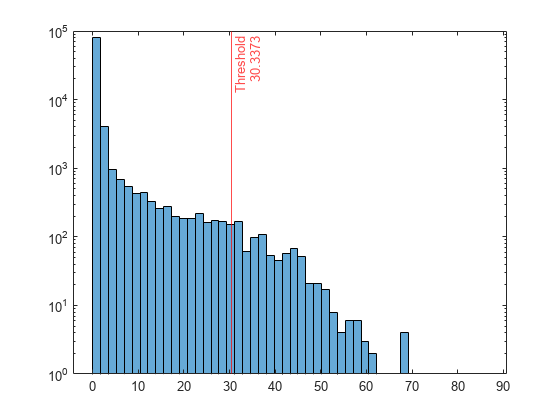
If you want to identify anomalies with a different contamination fraction (for example, 0.05), you can train a new local outlier factor model.
[newMdl,newtf,scores] = lof(NYCHousing2015,ContaminationFraction=0.05);
Note that changing the contamination fraction changes the anomaly indicators only, and does not affect the anomaly scores. Therefore, if you do not want to compute the anomaly scores again by using lof, you can obtain a new anomaly indicator with the existing score values.
Change the fraction of anomalies in the training data to 0.05.
newContaminationFraction = 0.05;
Find a new score threshold by using the quantile function.
newScoreThreshold = quantile(scores,1-newContaminationFraction)
newScoreThreshold = 6.7493
Obtain a new anomaly indicator.
newtf = scores > newScoreThreshold;
Create a LocalOutlierFactor object for uncontaminated training observations by using the lof function. Then detect novelties (anomalies in new data) by passing the object and the new data to the object function isanomaly.
Load the 1994 census data stored in census1994.mat. The data set consists of demographic data from the US Census Bureau to predict whether an individual makes over $50,000 per year.
load census1994census1994 contains the training data set adultdata and the test data set adulttest. The predictor data must be either all continuous or all categorical to train a LocalOutlierFactor object. Remove nonnumeric variables from adultdata and adulttest.
adultdata = adultdata(:,vartype("numeric")); adulttest = adulttest(:,vartype("numeric"));
Train a local outlier factor model for adultdata. Assume that adultdata does not contain outliers.
[Mdl,tf,s] = lof(adultdata);
Mdl is a LocalOutlierFactor object. lof also returns the anomaly indicators tf and anomaly scores s for the training data adultdata. If you do not specify the ContaminationFraction name-value argument as a value greater than 0, then lof treats all training observations as normal observations, meaning all the values in tf are logical 0 (false). The function sets the score threshold to the maximum score value. Display the threshold value.
Mdl.ScoreThreshold
ans = 28.6719
Find anomalies in adulttest by using the trained local outlier factor model.
[tf_test,s_test] = isanomaly(Mdl,adulttest);
The isanomaly function returns the anomaly indicators tf_test and scores s_test for adulttest. By default, isanomaly identifies observations with scores above the threshold (Mdl.ScoreThreshold) as anomalies.
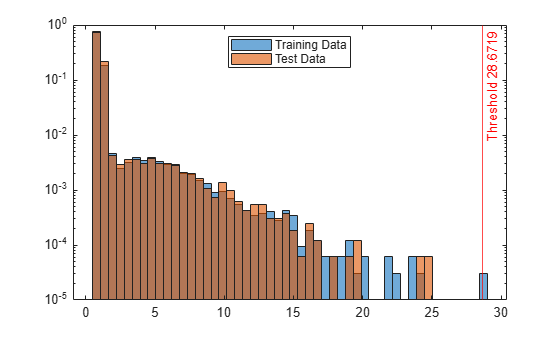
Create histograms for the anomaly scores s and s_test. Create a vertical line at the threshold of the anomaly scores.
h1 = histogram(s,NumBins=50,Normalization="probability"); hold on h2 = histogram(s_test,h1.BinEdges,Normalization="probability"); xline(Mdl.ScoreThreshold,"r-",join(["Threshold" Mdl.ScoreThreshold])) h1.Parent.YScale = 'log'; h2.Parent.YScale = 'log'; legend("Training Data","Test Data",Location="north") hold off
Display the observation index of the anomalies in the test data.
find(tf_test)
ans = 0×1 empty double column vector
The anomaly score distribution of the test data is similar to that of the training data, so isanomaly does not detect any anomalies in the test data with the default threshold value. You can specify a different threshold value by using the ScoreThreshold name-value argument. For an example, see Specify Anomaly Score Threshold.
Input Arguments
Name-Value Arguments
Output Arguments
More About
Algorithms
References
[1] Breunig, Markus M., et al. “LOF: Identifying Density-Based Local Outliers.” Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, 2000, pp. 93–104.
[2] Albanie, Samuel. Euclidean Distance Matrix Trick. June, 2019. Available at https://samuelalbanie.com/files/Euclidean_distance_trick.pdf.