ridge
Ridge regression
Description
B = ridge(y,X,k)X and the response
y. Each column of B corresponds to a
particular ridge parameter k. By default, the function computes
B after centering and scaling the predictors to have mean 0
and standard deviation 1. Because the model does not include a constant term, do not
add a column of 1s to X.
B = ridge(y,X,k,scaled)B. When
scaled is 1 (default),
ridge does not restore the coefficients to the original
data scale. When scaled is 0,
ridge restores the coefficients to the scale of the
original data. For more information, see Coefficient Scaling.
Examples
Perform ridge regression for a range of ridge parameters and observe how the coefficient estimates change.
Load the acetylene data set.
load acetyleneacetylene contains observations for the predictor variables x1, x2, and x3, and the response variable y.
Plot the predictor variables against each other. Observe any correlation between the variables.
plotmatrix([x1 x2 x3])

For example, note the linear correlation between x1 and x3.
Compute coefficient estimates for a multilinear model with interaction terms, for a range of ridge parameters. Use x2fx to create interaction terms and ridge to perform ridge regression.
X = [x1 x2 x3]; D = x2fx(X,'interaction'); D(:,1) = []; % No constant term k = 0:1e-5:5e-3; B = ridge(y,D,k);
Plot the ridge trace.
figure plot(k,B,'LineWidth',2) ylim([-100 100]) grid on xlabel('Ridge Parameter') ylabel('Standardized Coefficient') title('Ridge Trace') legend('x1','x2','x3','x1x2','x1x3','x2x3')
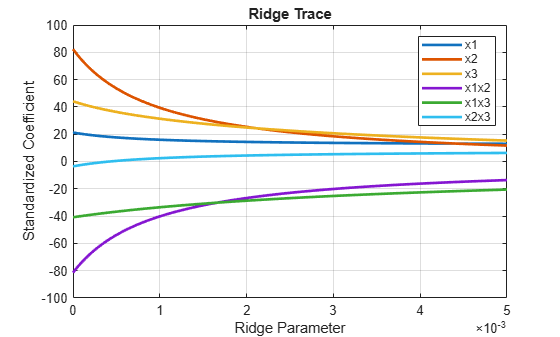
The estimates stabilize to the right of the plot. Note that the coefficient of the x2x3 interaction term changes sign at a value of the ridge parameter .
Predict miles per gallon (MPG) values using ridge regression.
Load the carbig data set.
load carbig
X = [Acceleration Weight Displacement Horsepower];
y = MPG;Split the data into training and test sets.
n = length(y); rng('default') % For reproducibility c = cvpartition(n,'HoldOut',0.3); idxTrain = training(c,1); idxTest = ~idxTrain;
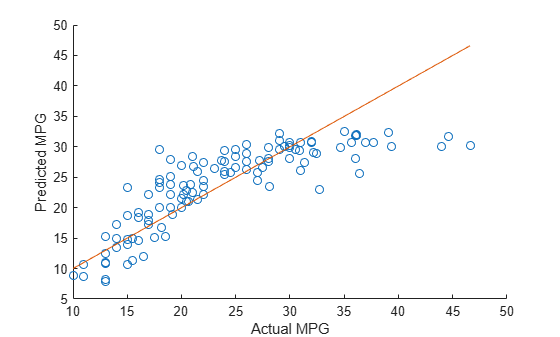
Find the coefficients of a ridge regression model (with k = 5).
k = 5; b = ridge(y(idxTrain),X(idxTrain,:),k,0);
Predict MPG values for the test data using the model.
yhat = b(1) + X(idxTest,:)*b(2:end);
Compare the predicted values to the actual miles per gallon (MPG) values using a reference line.
scatter(y(idxTest),yhat) hold on plot(y(idxTest),y(idxTest)) xlabel('Actual MPG') ylabel('Predicted MPG') hold off
Input Arguments
Output Arguments
More About
Tips
ridgetreatsNaNvalues inXoryas missing values.ridgeomits observations with missing values from the ridge regression fit.In general, set
scaledequal to1to produce plots where the coefficients are displayed on the same scale. See Ridge Regression for an example using a ridge trace plot, where the regression coefficients are displayed as a function of the ridge parameter. When making predictions, setscaledequal to0. For an example, see Predict Values Using Ridge Regression.
Alternative Functionality
Ridge, lasso, and elastic net regularization are all methods for estimating the coefficients of a linear model while penalizing large coefficients. The type of penalty depends on the method (see More About for more details). To perform lasso or elastic net regularization, use
lassoinstead.If you have high-dimensional full or sparse predictor data, you can use
fitrlinearinstead ofridge. When usingfitrlinear, specify the'Regularization','ridge'name-value pair argument. Set the value of the'Lambda'name-value pair argument to a vector of the ridge parameters of your choice.fitrlinearreturns a trained linear modelMdl. You can access the coefficient estimates stored in theBetaproperty of the model by usingMdl.Beta.
References
[1] Hoerl, A. E., and R. W. Kennard. “Ridge Regression: Biased Estimation for Nonorthogonal Problems.” Technometrics. Vol. 12, No. 1, 1970, pp. 55–67.
[2] Hoerl, A. E., and R. W. Kennard. “Ridge Regression: Applications to Nonorthogonal Problems.” Technometrics. Vol. 12, No. 1, 1970, pp. 69–82.
[3] Marquardt, D. W. “Generalized Inverses, Ridge Regression, Biased Linear Estimation, and Nonlinear Estimation.” Technometrics. Vol. 12, No. 3, 1970, pp. 591–612.
[4] Marquardt, D. W., and R. D. Snee. “Ridge Regression in Practice.” The American Statistician. Vol. 29, No. 1, 1975, pp. 3–20.
Version History
Introduced before R2006a
See Also
regress | stepwise | fitrlinear | lasso