lasso
Lasso or elastic net regularization for linear models
Description
B = lasso(X,y)X and the response y. Each
column of B corresponds to a particular regularization
coefficient in Lambda. By default, lasso
performs lasso regularization using a geometric sequence of
Lambda values.
B = lasso(X,y,Name=Value)Alpha=0.5 sets elastic
net as the regularization method, with the parameter Alpha equal
to 0.5.
Examples
Construct a data set with redundant predictors and identify those predictors by using lasso.
Create a matrix X of 100 five-dimensional normal variables. Create a response vector y from just two components of X, and add a small amount of noise.
rng default % For reproducibility X = randn(100,5); weights = [0;2;0;-3;0]; % Only two nonzero coefficients y = X*weights + randn(100,1)*0.1; % Small added noise
Construct the default lasso fit.
B = lasso(X,y);
Find the coefficient vector for the 25th Lambda value in B.
B(:,25)
ans = 5×1
0
1.6093
0
-2.5865
0
lasso identifies and removes the redundant predictors.
Create sample data with predictor variable X and response variable .
rng default % For reproducibility X = rand(100,1); y = 2*X + randn(100,1)/10;
Specify a regularization value, and find the coefficient of the regression model without an intercept term.
lambda = 1e-03; B = lasso(X,y,Lambda=lambda,Intercept=false)
Warning: When the 'Intercept' value is false, the 'Standardize' value is set to false.
B = 1.9825
Plot the real values (points) against the predicted values (line).
scatter(X,y) hold on x = 0:0.1:1; plot(x,x*B) hold off

Construct a data set with redundant predictors and identify those predictors by using cross-validated lasso.
Create a matrix X of 100 five-dimensional normal variables. Create a response vector y from two components of X, and add a small amount of noise.
rng default % For reproducibility X = randn(100,5); weights = [0;2;0;-3;0]; % Only two nonzero coefficients y = X*weights + randn(100,1)*0.1; % Small added noise
Construct the lasso fit by using 10-fold cross-validation with labeled predictor variables.
[B,FitInfo] = lasso(X,y,CV=10,PredictorNames=["x1","x2","x3","x4","x5"]);
Display the variables in the model that corresponds to the minimum cross-validated mean squared error (MSE).
idxLambdaMinMSE = FitInfo.IndexMinMSE; minMSEModelPredictors = FitInfo.PredictorNames(B(:,idxLambdaMinMSE)~=0)
minMSEModelPredictors = 1×2 cell
{'x2'} {'x4'}
Display the variables in the sparsest model within one standard error of the minimum MSE.
idxLambda1SE = FitInfo.Index1SE; sparseModelPredictors = FitInfo.PredictorNames(B(:,idxLambda1SE)~=0)
sparseModelPredictors = 1×2 cell
{'x2'} {'x4'}
In this example, lasso identifies the same predictors for the two models and removes the redundant predictors.
Visually examine the cross-validated error of various levels of regularization.
Load the sample data.
load acetyleneCreate a design matrix with interactions and no constant term.
X = [x1 x2 x3]; D = x2fx(X,"interaction"); D(:,1) = []; % No constant term
Construct the lasso fit using 10-fold cross-validation. Include the FitInfo output so you can plot the result.
rng default % For reproducibility [B,FitInfo] = lasso(D,y,CV=10);
Plot the cross-validated fits. The green circle and dotted line locate the Lambda with minimum cross-validation error. The blue circle and dotted line locate the point with minimum cross-validation error plus one standard error.
lassoPlot(B,FitInfo,PlotType="CV"); legend("show")

Predict students' exam scores using lasso and the elastic net method.
Load the examgrades data set.
load examgrades
X = grades(:,1:4);
y = grades(:,5);Split the data into training and test sets.
n = length(y); c = cvpartition(n,HoldOut=0.3); idxTrain = training(c,1); idxTest = ~idxTrain; XTrain = X(idxTrain,:); yTrain = y(idxTrain); XTest = X(idxTest,:); yTest = y(idxTest);
Find the coefficients of a regularized linear regression model using 10-fold cross-validation and the elastic net method with Alpha = 0.75. Use the largest Lambda value such that the mean squared error (MSE) is within one standard error of the minimum MSE.
[B,FitInfo] = lasso(XTrain,yTrain,Alpha=0.75,CV=10); idxLambda1SE = FitInfo.Index1SE; coef = B(:,idxLambda1SE); coef0 = FitInfo.Intercept(idxLambda1SE);
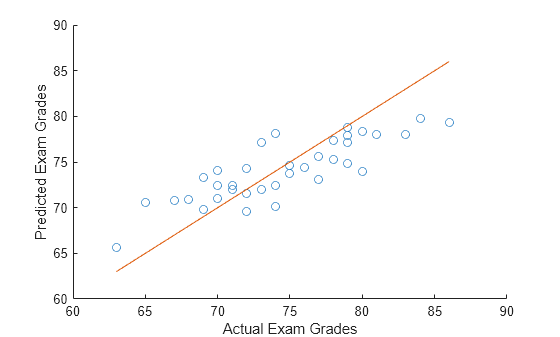
Predict exam scores for the test data. Compare the predicted values to the actual exam grades using a reference line.
yhat = XTest*coef + coef0; hold on scatter(yTest,yhat) plot(yTest,yTest) xlabel("Actual Exam Grades") ylabel("Predicted Exam Grades") hold off
Create a matrix X of N p-dimensional normal variables, where N is large and p = 1000. Create a response vector y from the model y = beta0 + X*p, where beta0 is a constant, along with additive noise.
rng default % For reproducibility N = 1e4; % Number of samples p = 1e3; % Number of features X = randn(N,p); beta = randn(p,1); % Multiplicative coefficients beta0 = randn; % Additive term y = beta0 + X*beta + randn(N,1); % Last term is noise
Construct the default lasso fit. Time the creation.
B = lasso(X,y,UseCovariance=false); % Warm up lasso for reliable timing data
tic
B = lasso(X,y,UseCovariance=false);
timefalse = toctimefalse = 1.9435
Construct the lasso fit using the covariance matrix. Time the creation.
B2 = lasso(X,y,UseCovariance=true); % Warm up lasso for reliable timing data
tic
B2 = lasso(X,y,UseCovariance=true);
timetrue = toctimetrue = 0.2104
The fitting time with the covariance matrix is much less than the time without it. View the speedup factor that results from using the covariance matrix.
speedup = timefalse/timetrue
speedup = 9.2369
Check that the returned coefficients B and B2 are similar.
norm(B-B2)/norm(B)
ans = 5.3514e-15
The results are virtually identical.
Input Arguments
Name-Value Arguments
Output Arguments
More About
Algorithms
References
[1] Tibshirani, R. “Regression Shrinkage and Selection via the Lasso.” Journal of the Royal Statistical Society. Series B, Vol. 58, No. 1, 1996, pp. 267–288.
[2] Zou, H., and T. Hastie. “Regularization and Variable Selection via the Elastic Net.” Journal of the Royal Statistical Society. Series B, Vol. 67, No. 2, 2005, pp. 301–320.
[4] Hastie, T., R. Tibshirani, and J. Friedman. The Elements of Statistical Learning. 2nd edition. New York: Springer, 2008.
[5] Boyd, S. “Distributed Optimization and Statistical Learning via the Alternating Direction Method of Multipliers.” Foundations and Trends in Machine Learning. Vol. 3, No. 1, 2010, pp. 1–122.
Extended Capabilities
Version History
Introduced in R2011b