R =
Results for
Hi everyone
I've been using ThingSpeak for several years now without an issue until last Thursday.
I have four ThingSpeak channels which are used by three Arduino devices (in two locations/on two distinct networks) all running the same code.
All three devices stopped being able to write data to my ThingSpeak channels around 17:00 CET on 4 Dec and are still unable to.
Nothing changed on this side, let alone something that would explain the problem.
I would note that data can still be written to all the channels via a browser so there is no fundamental problem with the channels (such as being full).
Since the above date and time, any HTTP/1.1 'update' (write) requests via the REST API (using both simple one-write GET requests or bulk JSON POST requests) are timing out after 5 seconds and no data is being written. The 5 second timeout is my Arduino code's default, but even increasing it to 30 seconds makes no difference. Before all this, responses from ThingSpeak were sub-second.
I have recompiled the Arduino code using the latest libraries and that didn't help.
I have tested the same code again another random api (api.ipify.org) and that works just fine.
Curl works just fine too, also usng HTTP/1.1
So the issue appears to be something particular to the combination of my Arduino code *and* the ThingSpeak environment, where something changed on the ThingSpeak end at the above date and time.
If anyone in the community has any suggestions as to what might be going on, I would greatly appreciate the help.
Peter
The first round of the the Cody Contest 2025 is drawing to an end, and those who have tried to tackle Problem 61069. Clueless - Lord Ned in the Game Room with the Technical Computing Language probably didn’t think, like me initially, that a vectorized solution was feasible.
Indeed, the problem is difficult enough, so that the first solution is more easily drafted using lots of for loops and conditionals.
Yet studying in depth how to vectorize the solution and get rid of redundancies helped me uncover the deeper mechanics of the algorithm and see the problem in a new light, making it progressively appear simpler than on its first encounter.
Obstacles to overcome
Vectorization depends highly on the properties of the knowledge matrix, a 3D-matrix of size [n, 3, m] storing our current knowledge about the status for each card of each category for all players.
I remember that initially, I was intent on keeping close together these two operations: assigning a YES to a player for a given card and category, and consequently assigning NOs to all other players.
I did not want to set them apart. My fear was that, if you did not keep track and updated the knowledge matrix consistently, you might end up with a whole mess making it impossible to guess what’s in the envelope!
That seemed important because, as one gradually retrieves information from the turns and revisits them, one assigns more and more YESs and narrows down the possible candidates for the cards hidden in the envelope.
For example, @JKMSMKJ had successifully managed to combined those two instructions in one line (Solution 14889208), like this (here 0 encodes NO and 1 encodes YES):
allplayers = 1:(m+1);
K(card, category,:) = allplayers == player;
For some time, I thought that was the nicest way to express it, even though you had to handle the indivual card, category and player with lots of loops and conditionals.
Watching @JKMSMKJ’s repeated efforts to rewrite and improve his code showed me differents ways to arrange the same instructions. It appeared to me that there was indeed a way to vectorize the solution, if only we accept to separate the two distinct operations of assigning a value of YES and updating the knowledge matrix for consistency.
So let’s see how this can be done. We will use the following convention introduced by @Stefan Abendroth: NO = 0, MAYBE= 1, YES = values > 1. The reason for that choice is that it will greatly simplify computations, as it will become apparent later.
Initialisation
First, initialising a matrix of MAYBEs and adding in the information from our own cards is pretty straightforward:
K = ones(m,3,n);
K(:,:,pnum) = 0;
allcategories = 1:3;
for category = allcategories
K(yourcards{deck},deck,pnum) = 2; % = YES
end
The same thing can be done for the common cards considered as the (m+1)th player.
Next, we’d like to retrieve information for the turns and insert it into the matrix.
The 1rst column of the turn matrix gives us a vector of the players.
The 2nd to 4th columns conveniently give us a 3 column matrix of the values of the cards asked.
players = turns(:,1);
cards = turns(:,2:4);
result = turns(:,5);
Now suppose we have similar 3-column matrices of the exactsame size for the players and for the categories, such as:
categories =
1 2 3
1 2 3
1 2 3
1 2 3
1 2 3
1 2 3
1 ...
players =
5 5 5
6 6 6
1 1 1
2 2 2
6 6 6
4 ...
It would then be nice to be able to write something like:
K(cards, categories, players) = 0; % or 1 or 2 depending on the desired assignment according to result
Unfortunately that is not possible when we have multiple indexes that are not scalars.
A workaround is to use what is called linear indices, which are the indices of the matrix when considering a matrix as a very long 1-column vector, and which can be computed with the function sub2ind:
[categories, players] = meshgrid(1:3, turns(:,1));
sz = [n, 3, m];
ind = sub2ind(sz, cards, categories, players);
K(ind) = 0; % or 1 or 2 depending on the desired assignment according to result
Ensuring everybody else has a NO
Next, let’s see how to update the matrix. We now suppose the YESs have been correctly assigned into the matrix.
Wherever we’ve identified the location of a card (”a YES”), all other players must be assigned a NO. For each card, there can be only one YES across all players.
Because of that, that YES is the maximum value across all layers of the matrix K. Using the function max on K along it’s third dimension reduces the 3rd dimension to 1, yielding a 2d matrix. To locate it, we can then compare the value of that 2d matrix with all the layers of K.
maxcard = max(K,[],3); % returns a n-by-3 matrix
is_a_yes = K == maxcard;
K == maxcard compares maxcard with each layer of K, yielding a 3d matrix of logicals of the same size as K, where 1 indicates a YES and 0 indicates “not a YES”.
Ten years ago, we’d have needed to use the function bsxfun to perform that operation, but since then, Matrix Size Array Compatibility has been extended in MATLAB. Isn’t it nice?
Now, to transform any “MAYBE” (a 1) into a NO (a 0), while keeping the existing YESs, MAYBEs, and NOs unmodified, we need only need only multiply that matrix element-by-element with K !
%% Update knowledge matrix: if someone has a >1 ("YES"), everyone else must have a 0 ("NO")
maxcard = max(ans,[],3);
K = K .* (K == maxcard);
That expression can be read as “keep the value of K wherever K is equal to its max, but set 0 elsewhere”. If the maximum is a MAYBE, it will stay a MAYBE.
Getting one’s head around such an expression may take some getting used to. But such a one-liner is immensely powerful. Imagine that one day, the rules of the game change, or that this requirement is not useful any more (that happens all the time in real life), then we can very easily just comment out just that one line without impacting the rest of the program.
Confirming a player’s card hand when we determined (3n - ncards) they don’t have
After information was retrieved from the turns, we can examine each player’s hand and if we have narrowed a player’s cards to ncard possible candidates, excluding all others, then these must the cards that they hold. That means that their MAYBE cards becomes YESs.
Locating a player’s hand amounts to locating all the strictly positive values in the matrix:
playerhand = K(:,:,p);
player_complete = sum(playerhand(:)>0)) == ncards;
That operation can actually be vectorized along all players. Summing the matrix of logicals (K>0) along the first two dimensions yields a 1-by-1-by-(m+1) matrix, akin to a vector containing the number of card candidates for each player, which we can compare to ncards.
player_complete = sum(K>0, 1:2) == ncards;
We need to transform into YESs the MAYBEs of the players for which we have successfully deduced ncards, which can be written as a simple multiplication by 2:
K(:,:,player_complete) = 2 * K(:,:,player_complete)
The 0s (NOs) will remain 0s, the MAYBEs will become 2s, and the YESs will be multiplied too, but still stay YESs (>1).
But since 2 .^ 0 = 1 and 2 .^ 1 = 2, there’s an even nicer way to write that calculation:
K = K .* 2 .^ player_complete;
which reads like “we multiply K by 2 wherever a player’s hand is complete”. All thanks to Array Size Compatibility!
That expression is nicer because we need not explicitly assign the operation to the 3rd dimension of K. Suppose that one day, for whatever reason (performance optimisation or change of requirements), information about the players is not stored along the 3rd dimension any more, that code would NOT need to change, whereas K(:,:,player_complete) would need to be ajusted.
That’s how elegant MATLAB can be!
Checking whether a player’s hand is complete
What we checked previously is equivalent to checking that the number of NOs (the number of cards a player has not) was equal to 3*n - ncards.
What we didn’t do is check whether the sum of YESs if equal to ncards and then transform all MAYBEs for that player into NOs.
That will not be necessary because of the implementation of the next rule.
Because the information provided to play the game is assumed to be sufficient to guess the missing cards, it means that the YESs and NOs will gradually populate the matrix, so that any remaining MAYBE will be determined.
Identifying each category's missing card when (n-1) cards are known
Each category only has n cards, which means that once (n-1) cards are correctly located, the remaining card can only be a NO for everyone.
Because a card can only be in only one player’s hand, we can reuse the maximum of K across all players that we previously computed. It is a n-by-3 2d matrix where the values > 1 are the YESs. Using the function sum adds up all the YESs found for each category, yielding a vector of 3 values, containing the number of cards correctly located.
maxcard = max(K,[],3);
category_complete = sum(maxcard > 1) == n-1;
When a category is complete, the last remaining MAYBE should become a NO, without modifying the YESs. A clever way is to multiply the value by itself minus one:
K(:,category_complete,:) = K(:,category_complete,:) .* (K(:,category_complete,:) - 1)
which, using the same exponentiation technique as previously, can be nicely and compactly rewritten as:
K = K .* (K-1) .^ category_complete;
Because the YESs are > 1, we can even compute that more simply like this (as Stefan Abendforth put it in Solution 14900340):
K = K .* (category_complete < K);
Extracting the index of the missing cards
After looping several times to extract all possible information, the last thing that remains to be done is computing the values of the missings cards. They are the only NOs left in the knowledge matrix, and in the 2d matrix maxcard as well:
maxcard = max(K,[],3);
[sol,~] = find(maxcard == 0);
Conclusion
I previously mentioned being bothered by matrix indexing such as K(:,:,player) because it is code that seems fragile in case of change in the organisation of the matrix. Such an instruction would benefit from being "encapsulated" if the need arises.
One of my main concerns has always been writing maintainable MATLAB code, having worked in organisations where code piled up almost everyday, making it gradually more difficult and time-consuming to add and enhance functionalities if not properly managed.
On the one hand, elegant vectorization leads us to group things together and handle them uniformly and efficiently, “in batches”. On the other hand, “separation of concerns”, one of Software Development’s principles and good practices, would advise us to keep parts small and modular and that can take care of themselves on their own if possible, achieving higher abstraction.
How do we keep different requirements independent, so that they do not impact each other if any one of them needs to change? But how do we exploit vectorization extensively for performance? These two opposing forces is what makes developing modular and efficient MATLAB code a challenge that no other language faces in the same way, in my opinion.
Seeing the rules of the game as a sequence of multiplications applied to the matrix K simultaneously reduces code size and reveals a deeper aspect of the algorithm: because multiplication is commutative and associative, we can apply them in any order, and we could also see them as independant “operators” that we could apply elsewhere.
---
I hope those explanations can help you better appreciate the beauty of vectorization and make it seem less daunting.
There are many other strokes of inspiration that emerged from different solvers solving Problem 61069. Clueless - Lord Ned in the Game Room with the Technical Computing Language, and I am the first one to be amazed by them.
I wish to see more of such cooperative brilliance and sound emulation everywhere! Thanks so much to Cody Contest team for setting up such a fun and rewarding experience.
Building Transition Matrices for the Royal Game of Err
King Neduchadneddar the Procrastinator has devised yet another scheme to occupy his court's time, and this one is particularly devious. The Royal Game of Err involves moving pawns along a path of n squares by rolling an m-sided die, with forbidden squares thrown in just to keep things interesting. Your mission, should you choose to accept it, is to construct a transition matrix that captures all the probabilistic mischief of this game. But here's the secret: you don't need nested loops or brute force. With the right MATLAB techniques, you can build this matrix with the elegance befitting a Chief Royal Mage of Matrix Computations.
The heart of this problem lies in recognizing that the transition matrix is dominated by a beautiful superdiagonal pattern. When you're on square j and roll the die, you have a 1/m chance of moving to each of squares j+1, j+2, up to j+m, assuming none are forbidden and you don't overshoot. This screams for vectorized construction rather than element-by-element assignment. The key weapon in your arsenal is MATLAB's ability to construct multiple diagonals simultaneously using either repeated calls to diag with offset parameters, or the more powerful spdiags function for those comfortable with advanced matrix construction.
Consider this approach: start with a zero matrix and systematically add 1/m to each of the m superdiagonals. For a die with m sides, you're essentially saying "from square j, there's a 1/m probability of landing on j+k for k = 1 to m." This can be accomplished with a simple loop over k, using T = T + diag(ones(1,n-k)*(1/m), k) for each offset k from 1 to m. The beauty here is that you're working with entire diagonals at once, not individual elements. This vectorized approach is not only more elegant but also more efficient and less error-prone than tracking indices manually.
Figure 1: Basic transition matrix structure for n=8, m=3, no forbidden squares. Notice the three superdiagonals carrying probability 1/3 each.
Now comes the interesting part: handling forbidden squares. When square j is forbidden, two things must happen simultaneously. First, you cannot land ON square j from anywhere, which means column j should be entirely zeros. Second, you cannot move FROM square j to anywhere, which means row j should be entirely zeros. The naive approach would involve checking each forbidden square and carefully adjusting individual elements. The elegant approach recognizes that MATLAB's logical indexing was practically designed for this scenario.
Here's the trick: once you've built your basic superdiagonal structure, handle all forbidden squares in just two lines: T(nogo, :) = 0 to eliminate all moves FROM forbidden squares, and T(:, nogo) = 0 to eliminate all moves TO forbidden squares. But wait, there's more. When you zero out these entries, the probabilities that would have gone to those squares need to be redistributed. This is where the "stay put" mechanism comes in. If rolling a 3 would land you on a forbidden square, you stay where you are instead. This means adding those lost probabilities back to the main diagonal.
The sophisticated approach uses logical indexing to identify which transitions would have violated the forbidden square rule, then redirects those probabilities to the diagonal. You can check if a move from square j to square k would hit a forbidden square using ismember(k, nogo), and if so, add that 1/m probability to T(j,j) instead. This "probability conservation" ensures that each row still sums to 1, maintaining the stochastic property of your transition matrix.
Figure 2: Transition matrix with forbidden squares marked. Left: before adjustment. Right: after forbidden square handling showing probability redistribution. Compare the diagonal elements.
The final square presents its own challenge. Once you reach square n, the game is over, which in Markov chain terminology means it's an "absorbing state." This is elegantly represented by setting T(n,n) = 1 and ensuring T(n, j) = 0 for all j not equal to n. But there's another boundary condition that's equally important: what happens when you're on square j and rolling the die would take you beyond square n?
The algorithm description provides a clever solution: you stay put. If you're on square n-2 and roll a 4 on a 6-sided die, you don't move. This means that for squares near the end, the diagonal element T(j,j) needs to accumulate probability from all those "overshooting" scenarios. Mathematically, if you're on square j and rolling k where j+k exceeds n, that 1/m probability needs to be added to T(j,j). A clean way to implement this is to first build the full superdiagonal structure as if the board were infinite, then add (1:m)/m to the last m elements of the diagonal to account for staying put.
There's an even more elegant approach: build your superdiagonals only up to where they're valid, then explicitly calculate how much probability should stay on the diagonal for each square. For square j, count how many die outcomes would either overshoot n or hit forbidden squares, multiply by 1/m, and add to T(j,j). This direct calculation ensures you've accounted for every possible outcome and maintains the row-sum property.
Figure 3: Heat map showing probability distributions from different starting squares. Notice how probabilities "pile up" at the diagonal for squares near the boundary.
Now that you understand the three key components, the construction strategy becomes clear. Initialize your n-by-n zero matrix. Build the basic superdiagonal structure to represent normal movement. Identify and handle forbidden squares by zeroing rows and columns, then redistributing lost probability to the diagonal. Finally, ensure boundary conditions are met by setting the final square as absorbing and handling the "stay put" cases for near-boundary squares.
The order matters here. If you handle forbidden squares first and then build diagonals, you might overwrite your forbidden square adjustments. The cleanest approach is to build all m superdiagonals first, then make a single pass to handle both forbidden squares and boundary conditions simultaneously. This can be done efficiently with a vectorized check: for each square j, count valid moves, calculate stay-put probability, and update T(j,j) accordingly.
Figure 4: Complete transition matrix for a test case with n=7, m=4, nogo=[2 5]. Spy plot showing the sparse structure alongside a color-coded heat map. Notice the complex pattern of probabilities.
Before declaring victory over King Neduchadneddar, verify your matrix satisfies the fundamental properties of a transition matrix. First, every element should be between 0 and 1 (probabilities, after all). Second, each row should sum to exactly 1, representing the fact that from any square, you must end up somewhere (even if it's staying put). You can check this with all(abs(sum(T,2) - 1) < 1e-10) to account for floating-point arithmetic.
The provided test cases offer another validation opportunity. Start with the simplest cases where patterns are obvious, like n=8, m=3 with no forbidden squares. You should see a clean superdiagonal structure. Then progress to cases with forbidden squares and verify that columns and rows are properly zeroed. The algorithm description even provides example matrices for you to compare against. Pay special attention to the diagonal elements, as they're where most of the complexity hides.
Figure 5: Validation dashboard showing row sums (should all be 1), matrix properties, and comparison with expected structure for a simple test case.
For those seeking to optimize their solution, consider that for large n, explicitly storing an n-by-n dense matrix becomes memory-intensive. Since most elements are zero, MATLAB's sparse matrix format is ideal. Replace zeros(n) with sparse(n,n) at initialization. The same indexing and diagonal operations work seamlessly with sparse matrices, but you'll save considerable memory for large problems.
Another sophistication involves recognizing that the transition matrix construction is fundamentally about populating a banded matrix with some modifications. The spdiags function was designed for exactly this scenario. You can construct all m superdiagonals in a single call by preparing a matrix where each column represents one diagonal's values. While the syntax takes some getting used to, the resulting code is remarkably compact and efficient.
For debugging purposes, visualizing your matrix at each construction stage helps immensely. Use imagesc(T) with a colorbar to see the probability distribution, or spy(T) to see the non-zero structure. If you're not seeing the expected patterns, these visualizations immediately reveal whether your diagonals are in the right positions or if forbidden squares are properly handled.
Figure 6: Performance comparison showing construction time and memory usage for dense vs sparse implementations as n increases.
King Neduchadneddar may have thought he was creating an impossible puzzle, but armed with MATLAB's matrix manipulation prowess, you've seen that elegant solutions exist. The key insights are recognizing the superdiagonal structure, handling forbidden squares through logical indexing rather than explicit loops, and carefully managing boundary conditions to ensure probability conservation. The transition matrix you've constructed doesn't just solve a Cody problem; it represents a complete probabilistic model of the game that could be used for further analysis, such as computing expected game lengths or steady-state probabilities.
The beauty of this approach lies not in clever tricks but in thinking about the problem at the right level of abstraction. Rather than considering each element individually, you've worked with entire diagonals, rows, and columns. Rather than writing conditional logic for every special case, you've used vectorized operations that handle all cases simultaneously. This is the essence of MATLAB mastery: letting the language's strengths work for you rather than against you.
As Vasilis Bellos demonstrated with the Bridges of Nedsburg , sometimes the most satisfying part of a Cody problem isn't just getting the tests to pass, but understanding the mathematical structure deeply enough to implement it elegantly. King Neduchadneddar would surely be impressed by your matrix manipulation skills, though he'd probably never admit it. Now go forth and construct those transition matrices with the confidence of a true Chief Royal Mage of Matrix Computations. The court awaits your solution.
Note: This article provides strategic insights and techniques for solving Problem 61067 without revealing the complete solution. The figures reference MATLAB Mobile script created by me that demonstrate key concepts. For the full Cody Contest 2025 experience and to test your implementation, visit the problem page and may your matrices always be stochastic.
As @Vasilis Bellos has neatly summarized here, in order to solve Problem 61069. Clueless - Lord Ned in the Game Room with the Technical Computing Language from the Cody Contest 2025, there are 4 rules to take into account and implement:
- If a player has a card, no other player has it
- If a player has ncards confirmed, they have no other cards
- If (n - 1) cards in a category are located, the nth card is in the envelope
- If a player has (3n - ncards) confirmed cards that they don't have, they must have the remaining unknown cards
As suggested in the problem statement, one natural way to attempt to solve the problem leads to storing the status of our knowledge about all the cards in an array, specifically a 3d matrix of size n by 3 by m.
Such a matrix is especially convenient because K(card, category, player) directly yields the knowledge status we have about a given card and category for a given player.
It also enables us to check the knowledge status:
- across all players for a given card and category, with K(card, category, :) (needed for rule 1)
- about the cards that a given player holds in his hand: K(:, :, player) yields a 2d slice of size n by 3 (needed for rules 2 and 4)
- of the location of the n-1 cards for each category: K(:, category, :) (needed for rule 3)
The question then arises of how to encode the information about the status of cards of the players : whether unknown, maybe, definitely have and definitely have not.
It quickly appears that there is no difference between “unknown” and “maybe”.
Therefore only three distinct values are needed, to encode “YES”, “NO”, and “MAYBE”.
I would like to discuss the way these values are chosen has an impact on how we can manage to vectorize the solution to the problem (especially since a vectorized solution does not immediately appear) and make computations more elegant and easier to follow.
The 3D-matrix naturally suggest the use of the functions sum, max, and min across any of its 3 dimensions to perform the required computations. As such, the values 0, 1, NaN, and Inf can all play a very important role in storing our knowledge about the presence or absence of the cards throughout our deductions.
However, after having a look at the submitted solutions, what has struck me is that the majority of solvers (about two thirds) chose to encode MAYBE = 0, NO = -1, and YES = 1.
I wonder if that was because they were influenced by the way the problem is stated, or whether because they are “naturally” inclined to consider “MAYBE” to be “between” NO and YES.
The hierarchy we choose is important because it will influence the way we can make use of max and min. Also, 0 is a very important value because it "absorbs" all multiplied values during computations. Why give "MAYBE" such an important value?
My personal first intuition was to encode NO = 0 and YES = 1, and then something complety appart for MAYBE, either NaN or (-1). The advantage of -1 being that it can be easily transformed into 0 or 1.
In my mind, that way makes it easier:
- to count the YESs : sum( K > 0)
- to count the NOs : sum( K == 0 )
- to find the last remaining NOs : find( K(…) == 0)
- to count the MAYBEs or YESs (the “not NOs”) : sum( abs(K(…)) ) or sum( K(…) ~= 0 )
- to convert MAYBE into YES with information from the turns without modifying other cards’ statuses : K( … ) = abs(K( … )) or K(…) = K( … ).^2
- to convert MAYBE into NO once a card is located elsewhere without modifying other cards’ statuses : K(…) = max(0, K( … ))
Of course, we can devise similar operations if we choose to encode MAYBE = 0, NO = -1, and YES = 1, such as:
- to count the YESs : sum( K > 0)
- to count the NOs : sum( K < 0 )
- to find the last remaining NOs : find( K(…) < 0)
- to count the MAYBEs or YESs (the “not NOs”) : sum( K(…) >= 0)
- to convert MAYBE into YES with information from the turns without modifying other cards’ statuses : K(… ) = min(1, 2*K(…) + 1)
- to convert MAYBE into NO once a card is located elsewhere without modifying other cards’ statuses : K(…) = max(-1, (2*K(…) - 1 )) (already used in Matt Tearle’s Solution 14843428)
I find those functions somewhat more cumbersome and of course they don’t help reducing Cody size. I tried devising a solution using that encoding that you can check there too and see how twisted it looks: Solution 14904420 (it can still be optimised, I believe, but I find it hard to get my head around it...)
At some point, I also considered devising a solution combining 0, 1 and Inf or -Inf, but the problem was that 0 * Inf = NaN, not very practical in the end.
The real breakthrough came when @Stefan Abendroth submitted a solution using the following convention: MAYBE = 1, NO = 0, and YES = any number > 1 (Solution 14896297).
He used the following functions :
- to convert MAYBE into YES with information from the turns without modifying other cards’ statuses : K(…) = 2 * K(…) (such a simple function!)
- to convert MAYBE into NO once a card is located elsewhere without modifying other cards’ statuses : K(…) = bitand(K(…), 254), which was later optimised and became even simpler after several iterations.
The current leading solution uses that encoding and is really worth a close examination in my opinion, because it actually compacts the computation in such an elegant way, in just a few instructions.
Opening up the space of the values that encode YES and exploiting the properties of 0 and 1 for algebraic operations, shows in a profound way how to use the set of natural numbers, an idea that doesn’t come immediately to my mind as I am so used to thinking in vector spaces and linear algebra.
Interestingly enough, the first solution that Stefan submitted (Solution 14848390) already encoded MAYBE as 1, NO as 0 and YES as 2. I wonder where that intuition comes from.
I have seen two others solvers use MAYBE = 2 / NO = 0 / YES = 1, (at least) three that used the MAYBE = -1 / NO = 0 / YES = 1, and several others using various systems of their own.
I hope this example showcases how different matrix encoding reveal different thinking processes and how the creative search for a more efficient matrix encoding (motivated by the reduction in Cody size) has (unexpectedly ?) led to a brilliant and elegant vectorized solution.
Another proof of how Cody can provide so much instruction and fun!
Having tackled a given problem is not the end of the game, and the fun is far from over. Thanks to the test suite in place, we can continue tweaking our solutions ("refactoring") so that it still passes the tests while improving its ranking with regard to "Cody size".
Although reducing the Cody size does not necessarily mean a solution will perform more efficiently nor be more readable (quite the contrary, actually…), it is a fun way to delve into the intricacies of MATLAB code and maybe win a Cody Leader badge!
I am not talking about just basic hacks. The size constraint urges us to find an “out-of-the box” way of solving a problem, a way of thinking creatively, of finding other means to achieve a desired computation result, that uses less variables, that is less cumbersome, or that is more refined.
The past few days have taught me several useful tricks that I would like to share with anyone wishing to reduce the solution size of their Cody submission. Happy to learn about other tricks you may know of, please share!
- Use this File Exchange submission to get the size of your solution: https://fr.mathworks.com/matlabcentral/fileexchange/34754-calculate-size
- Use existing MATLAB functions that may already perform the desired calculations but that you might have overlooked (as I did with histcount and digraph).
- Use vectorization amply. It’s what make the MATLAB language so concise and elegant!
- Before creating a matrix of replicated values, check if your operation requires it. See Compatible Array Sizes for Basic Operations. For example, you can write x == y with x being a column vector and y a row vector, thereby obtaining a 2 by 2-matrix.
- Try writing out for loops instead of vectorization. Sometimes it’s actually smaller from a Cody point of view.
- Avoid nested functions and subfunctions. Try anonymous functions if used in several places. (By all means, DO write nested functions and subfunctions in real life!)
- Avoid variable assignments. If you declare variables, look for ones you can use in multiples places for multiple purposes. If you have a variable used only in one place, replace it with its expression where you need it. (Do not do this in real life!)
- Instead of variable assignments, write hardcoded constants. (Do not do this in real life!)
- Instead of indexed assignments, look for a way to use multiplying or exponentiating with logical indexes. (For example, compare Solution 14896297 and Solution 14897502 for Problem 61069. Clueless - Lord Ned in the Game Room with the Technical Computing Language).
- Replace x == 0 with ~x if x is a numeric scalar or vector or matrix that doesn’t contain any NaN (the latter is smaller in size by 1)
- Instead of x == -1, see if x < 0 works (smaller in size by 1).
- Instead of [1 2], write 1:2 (smaller in size by 1).
- “sum(sum(x))” is actually smaller than “sum(x, 1:2)”
- Instead of initialising a matrix of 2s with 2 * ones(m,n), write repmat(2,m,n) (smaller in size by 1).
- If you have a matrix x and wish to initialize a matrix of 1s, instead of ones(size(x)), write x .^ 0 (works as long as x doesn’t contain any NaN) (smaller in size by 2).
- Unfortunately, x ^-Inf doesn’t provide any reduction compared to zeros(size(x)), and it doesn’t work when x contains 0 or 1.
- Beware of Operator Precedence and avoid unnecessary parenthesis (special thanks to @Stefan Abendroth for bringing that to my attention ;)) :
- Instead of x * (y .^ 2), write x * y .^2 (smaller in size by 1).
- Instead of x > (y == z), write y == z < x (smaller in size by 1).
18. Ask help from other solvers: ideas coming from a new pair of eyes can bring unexpected improvements!
That’s all I can see for now.
Having applied all those tips made me realise that a concise yet powerful code, devoid of the superfluous, also has a beauty of its own kind that we can appreciate.
Yet we do not arrive at those minimalist solutions directly, but through several iterations, thanks to the presence of tests that allow us to not worry about breaking anything, and therefore try out sometimes audacious ideas.
That's why I think the main interest lies in that it prompts to think of our solutions differently, thereby opening ways to better understand the problem statement at hand and the inner workings of the possible solutions.
Hope you’ll find it fun and useful!
P.S.: Solvers, please come help us reduce even more the size of the leading solution for Problem 61069. Clueless - Lord Ned in the Game Room with the Technical Computing Language!
Hi Creative Coders!
I've been working my way through the problem set (and enjoying all the references), but the final puzzle has me stumped. I've managed to get 16/20 of the test cases to the right answer, and the rest remain very unsolvable for my current algorithm. I know there's some kind of leap of logic I'm missing, but can't figure out quite what it is. Can any of you help?
What I've Done So Far
My current algorithm looks a bit like this. The code is doing its best to embody spaghetti at the moment, so I'll refrain from posting the whole thing to spare you all from trying to follow my thought processes.
Step 1: Go through all the turns and fill out tables of 'definitely', 'maybe', and 'clue' based on the information provided in a single run through the turns. This means that the case mentioned in the problem where information from future turns affecting previous turns does not matter yet. 'Definitely' information is for when I know a card must belong to a certain player (or to no-one). 'Maybe' starts off with all players in all cells, and when a player is found to not be able to have a card, their number is removed from the cell. Think of Sudoku notes where someone has helpfully gone through the grid and put every single possible number in each cell. 'Clue' contains information about which cards players were hinted about.
Example from test case 1:
definitelyTable =
6×3 table
G1 G2 G3
____________ ____________ ____________
{[ 0]} {0×0 double} {0×0 double}
{0×0 double} {[ -1]} {[ 1]}
{0×0 double} {[ 6]} {[ 0]}
{[ 3]} {[ 4]} {0×0 double}
{0×0 double} {[ 0]} {0×0 double}
{[ 5]} {[ 3]} {0×0 double}
maybeTable =
6×3 table
G1 G2 G3
_________ _______ _______
{[ 0]} {[2 5]} {[1 2]}
{[ 4]} {[ 0]} {[ 0]}
{[2 4 6]} {[ 0]} {[ 0]}
{[ 0]} {[ 0]} {[1 4]}
{[ 1 4]} {[ 0]} {[ 1]}
{[ 0]} {[ 0]} {[2 4]}
clueTable =
6×3 table
G1 G2 G3
____________ ____________ ____________
{0×0 double} {[ 5 6]} {[ 2 4]}
{[ 4 6]} {[ 4 6]} {0×0 double}
{[ 2 6]} {[ 5 6]} {0×0 double}
{0×0 double} {[ 4]} {[ 4 5 6]}
{[ 4]} {0×0 double} {[ 1 4 6]}
{[ 2 5]} {0×0 double} {[ 2 4 5 6]}
(-1 indicates the card is in the envelope. 0 indicates the card is commonly known.)
Step 2: While a solution has not yet been found, loop through all the turns again. This is the part where future turn info can now be fed back into previous turns, and where my sticky test cases loop forever. I've coded up each of the implementation tips from the problem statement for this stage.
Where It All Comes Undone
The problem is, for certain test cases (e.g., case 5), I reach a point where going through all turns yields no new information. I either end up with an either-or scenario, where the potential culprit card is one of two choices, or with so little information it doesn't look like there is anywhere left to turn.
I solved some of the either-or cases by adding a snippet that assumes one of the values and then tries to solve the problem based on that new information. If it can't solve it, then it tries the other option and goes round again. Unfortunately, however, this results in an infinite flip-flop for some cases as neither guess resolves the puzzle.
Essentially guessing the solution and following through to a logical inconsistency for however many combinations of players and cards sounds a) inefficient and b) not the way this was intended to be solved. Does anyone have any hints that might get me on track to solve this mystery?
Hello,
I have Arduino DIY Geiger Counter, that uploads data to my channel here in ThingSpeak (3171809), using ESP8266 WiFi board. It sends CPM values (counts per minute), Dose, VCC and Max CPM for 24h. They are assignet to Field from 1 to 4 respectively. How can I duplicate Field 1, so I could create different time chart for the same measured unit? Or should I duplicate Field 1 chart, and how? I tried to find the answer here in the blog, but I couldn't.

I have to say that I'm not an engineer or coder, just can simply load some Arduino sketches and few more things, so I'll be very thankfull if someone could explain like for non-IT users.
Regards,
Emo
Fittingly for a Creative Coder, @Vasilis Bellos clearly enjoyed the silliness I put into the problems. If you've solved the whole problem set, don't forget to help out your teammates with suggestions, tips, tricks, etc. But also, just for fun, I'm curious to see which of my many in-jokes and nerdy references you noticed. Many of the problems were inspired by things in the real world, then ported over into the chaotic fantasy world of Nedland.
I guess I'll start with the obvious real-world reference: @Ned Gulley (I make no comment about his role as insane despot in any universe, real or otherwise.)
The Cody Contest 2025 is underway, and it includes a super creative problem group which many of us have found fascinating. The central theme of the problems, expertly curated by @Matt Tearle, humorously revolves around the whims of the capricious dictator Lord Ned, as he goes out of his way to complicate the lives of his subjects and visitors alike. We cannot judge whether or not there's any truth to the rumors behind all the inside jokes, but it's obvious that the team had a lot of fun creating these; and we had even more fun solving them.
Today I want to showcase a way of graphically solving and visualizing one of those problems which I found very elegant, The Bridges of Nedsburg.
To briefly reiterate the problem, the number of islands and the arrangement of bridges of the city of Nedsburg are constantly changing. Lord Ned has decided to take advantage of this by charging visitors with an increasingly expensive n-bridge pass which allows them to cross up to n bridges in one journey. Given the Connectivity Matrix C, we are tasked with calculating the minimum n needed so that there is a path from every island to every other island in n steps or fewer.
Matt kindly provided us with some useful bit of math in the description detailing how to calculate the way to get from one island to another in an number of m steps. However, he has also hidden an alternative path to the solution in plain sight, in one of the graphs he provided. This involves the extremely useful and versatile class digraph, representing directed graphs, which have directional edges connecting the nodes. Here's some further great documentation and other cool resources on the topic for those who are interested in learning more about it:
Let's start using this class to explore a graphical solution to Lord Ned's conundrum. We will use the unit tests included in the problem to visualize the solution. We can retrieve the connectivity matrix for each case using the following function:
function C = getConnectivityMatrix(unit_test)
% Number of islands and bridge arrangement
switch unit_test
case 1
m = 3; idx = [3;4;8];
case 2
m = 3; idx = [3;4;7;8];
case 3
m = 4; idx = [2;7;8;10;13];
case 4
m = 4; idx = [4;5;7;8;9;14];
case 5
m = 5; idx = [5;8;11;12;14;18;22;23];
case 6
m = 5; idx = [2;5;8;14;20;21;24];
case 7
m = 6; idx = [3;4;7;11;18;23;24;26;30;32];
case 8
m = 6; idx = [3;11;12;13;18;19;28;32];
case 9
m = 7; idx = [3;4;6;8;13;14;20;21;23;31;36;47];
case 10
m = 7; idx = [4;11;13;14;19;22;23;26;28;30;34;35;37;38;45];
case 11
m = 8; idx = [2;4;5;6;8;12;13;17;27;39;44;48;54;58;60;62];
case 12
m = 8; idx = [3;9;12;20;24;29;30;31;33;44;48;50;53;54;58];
case 13
m = 9; idx = [8;9;10;14;15;22;25;26;29;33;36;42;44;47;48;50;53;54;55;67;80];
case 14
m = 9; idx = [8;10;22;32;37;40;43;45;47;53;56;57;62;64;69;70;73;77;79];
case 15
m = 10; idx = [2;5;8;13;16;20;24;27;28;36;43;49;53;62;71;75;77;83;86;87;95];
case 16
m = 10; idx = [4;9;14;21;22;35;37;38;44;47;50;51;53;55;59;61;63;66;69;76;77;84;85;86;90;97];
end
C = zeros(m);
C(idx) = 1;
end
The case in the example refers to unit test case 2.
unit_test = 2;
C = getConnectivityMatrix(unit_test);
disp(C)
D = digraph(C);
figure
p = plot(D,'LineWidth',1.5,'ArrowSize',10);
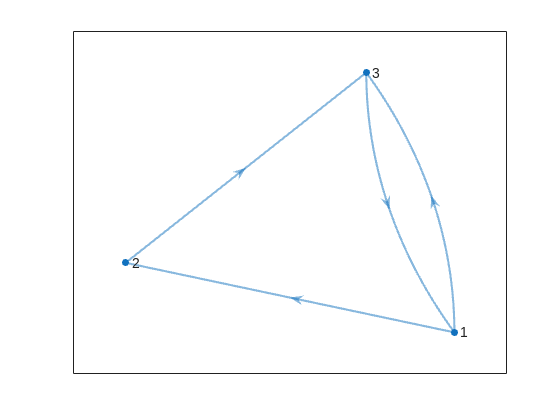
This is the same as the graph provided in the example. Another very useful method of digraph is shortestpath. This allows us to calculate the path and distance from one single node to another. For example:
% Path and distance from node 1 to node 2
[path12,dist12] = shortestpath(D,1,2);
fprintf('The shortest path from island %d to island %d is: %s. The minimum number of steps is: n = %d\n', 1, 2, join(string(path12), ' -> '),dist12)
% Path and distance from node 2 to node 1
[path21,dist21] = shortestpath(D,2,1);
fprintf('The shortest path from island %d to island %d is: %s. The minimum number of steps is: n = %d\n', 2, 1, join(string(path21), ' -> '),dist21)
figure
p = plot(D,'LineWidth',1.5,'ArrowSize',10);
highlight(p,path12,'EdgeColor','r','NodeColor','r','LineWidth',2)
highlight(p,path21,'EdgeColor',[0 0.8 0],'LineWidth',2)
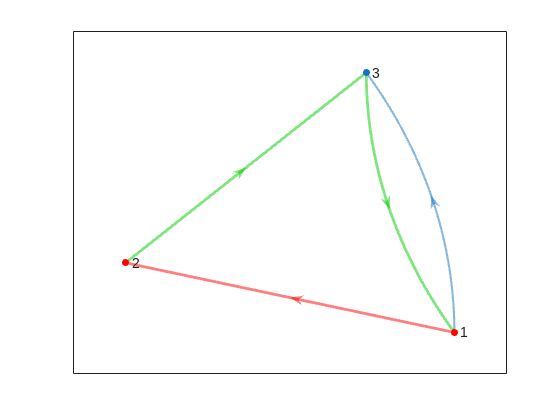
But that's not all! digraph can also provide us with a matrix of the distances d, i.e. the steps needed to travel from island i to island j, where i and j are the rows and columns of d respectively. This is accomplished by using its distances method. The distance matrix can be visualized as:
d = distances(D);
figure
% Using pcolor w/ appending matrix workaround for convenience
pcolor([d,d(:,end);d(end,:),d(end,end)])
% Alternatively you can use imagesc(d), but you'll have to recreate the grid manually
axis square
set(gca,'YDir','reverse','XTick',[],'YTick',[])
[X,Y] = meshgrid(1:height(d));
text(X(:)+0.5,Y(:)+0.5,string(d(:)),'FontSize',11)
colormap(interp1(linspace(0,1,4), [1 1 1; 0.7 0.9 1; 0.6 0.7 1; 1 0.3 0.3], linspace(0,1,8)))
clim([-0.5 7+0.5])
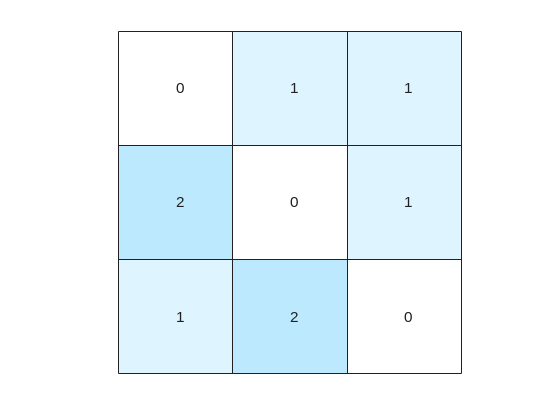
This confirms what we saw before, i.e. you need 1 step to go from island 1 to island 2, but 2 steps for vice versa. It also confirms that the minimum number of steps n that you need to buy the pass for is 2 (which also occurs for traveling from island 3 to island 2). As it's not the point of the post to give the full solution to the problem but rather present the graphical way of visualizing it I will not include the code of how to calculate this, but I'm sure that by now it's reduced to a trivial problem which you have already figured out how to solve.
That being said, now that we have the distance matrix, let's continue with the visualizations. First, let's plot the corresponding paths for each of these combinations:
figure
tiledlayout(size(C,1),size(C,2),'TileSpacing','tight','Padding','tight');
for i = 1:size(C,1)
for j = 1:size(C,2)
nexttile
p = plot(D,'ArrowSize',10);
highlight(p,shortestpath(D,i,j),'EdgeColor','r','NodeColor','r','LineWidth',2)
lims = axis;
text(lims(1)+diff(lims(1:2))*0.05,lims(3)+diff(lims(3:4))*0.9,sprintf('n = %d',d(i,j)))
end
end
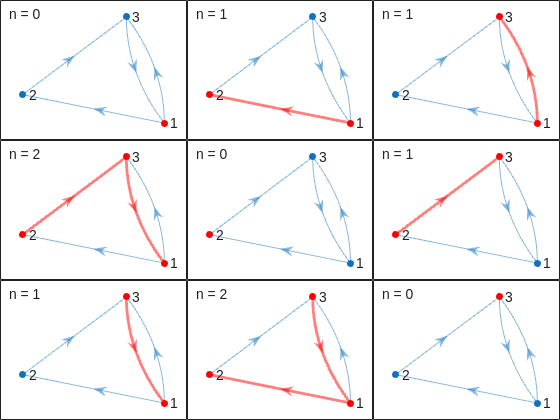
This allows us to go from the distance matrix to visualizing the paths and number of steps for each corresponding case. Things are rather simple for this 3-island example case, but evil Lord Ned is just getting started. Let's now try to solve the problem for all provided unit test cases:
% Cell array of connectivity matrices
C = arrayfun(@getConnectivityMatrix,1:16,'UniformOutput',false);
% Cell array of corresponding digraph objects
D = cellfun(@digraph,C,'UniformOutput',false);
% Cell array of corresponding distance matrices
d = cellfun(@distances,D,'UniformOutput',false);
% id of solutions: Provided as is to avoid handing out the code to the full solution
id = [2, 2, 9, 3, 4, 6, 16, 4, 44, 43, 33, 34, 7, 18, 39, 2];
First, let's plot the distance matrix for each case:
figure
tiledlayout('flow','TileSpacing','compact','Padding','compact');
% Vary this to plot different combinations of cases
plot_cases = 1:numel(C);
for i = plot_cases
nexttile
pcolor([d{i},d{i}(:,end);d{i}(end,:),d{i}(end,end)])
axis square
set(gca,'YDir','reverse','XTick',[],'YTick',[])
title(sprintf('Case %d',i),'FontWeight','normal','FontSize',8)
end
c = colorbar('Ticks',0:7,'TickLength',0,'Limits',[-0.5 7+0.5],'FontSize',8);
c.Layout.Tile = 'East';
c.Label.String = 'Number of Steps';
c.Label.FontSize = 8;
colormap(interp1(linspace(0,1,4), [1 1 1; 0.7 0.9 1; 0.6 0.7 1; 1 0.3 0.3], linspace(0,1,8)))
clim(findobj(gcf,'type','axes'),[-0.5 7+0.5])
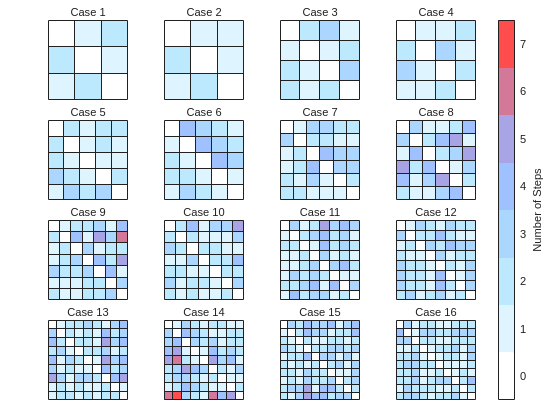
We immediately notice some inconsistencies, perhaps to be expected of the eccentric and cunning dictator. Things are pretty simple for the configurations with a small number of islands, but the minimum number of steps n can increase sharply and disproportionally to the additional number of islands. Cases 8 and 9 specifically have a particularly large n (relative to their grid dimensions), and case 14 has the largest n, almost double that of case 16 despite the fact that the latter has one extra island.
To visualize how this is possible, let's plot the path corresponding to the largest n for each case (though note that there might be multiple possible paths for each case):
figure
tiledlayout('flow','TileSpacing','tight','Padding','tight');
for i = plot_cases
nexttile
% Changing the layout to circular so we can better visualize the paths
p = plot(D{i},'ArrowSize',10,'Layout','Circle');
% Alternatively we could use the XData and YData properties if the positions of the islands were provided
axis([-1.5 1.5 -1.5 1.75])
[row,col] = ind2sub(size(d{i}),id(i));
highlight(p,shortestpath(D{i},row,col),'EdgeColor','r','NodeColor','r','LineWidth',2)
lims = axis;
text(lims(1)+diff(lims(1:2))*0.05,lims(3)+diff(lims(3:4))*0.9,sprintf('n = %d',d{i}(row,col)))
end
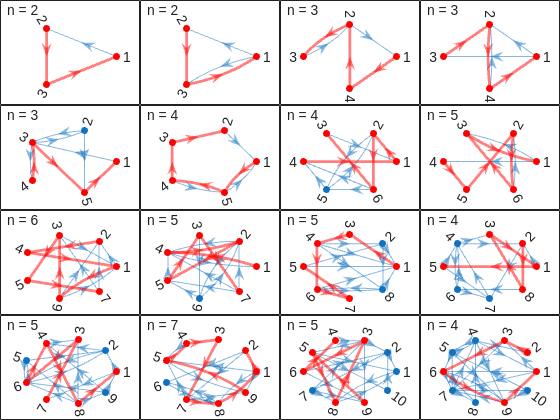
And busted! Unraveled! Exposed! Lord Ned has clearly been taking advantages of the tectonic forces by instructing his corrupt civil engineer lackeys to design the bridges to purposely force the visitors to go around in circles in order to drain them of their precious savings. In particular, for cases 8 and 9, he would have them go through every single island just to get from one island to another, whereas for case 14 they would have to visit 8 of the 9 islands just to get to their destination. If that's not diabolical then I don't know what is!
Ned jokes aside, I hope you enjoyed this contest just as much as I did, and that you found this article useful. I look forward to seeing more creative problems and solutions in the future.
It’s exciting to dive into a new dataset full of unfamiliar variables but it can also be overwhelming if you’re not sure where to start. Recently, I discovered some new interactive features in MATLAB live scripts that make it much easier to get an overview of your data. With just a few clicks, you can display sparklines and summary statistics using table variables, sort and filter variables, and even have MATLAB generate the corresponding code for reproducibility.
The Graphics and App Building blog published an article that walks through these features showing how to explore, clean, and analyze data—all without writing any code.
If you’re interested in streamlining your exploratory data analysis or want to see what’s new in live scripts, you might find it helpful:
If you’ve tried these features or have your own tips for quick data exploration in MATLAB, I’d love to hear your thoughts!
I am Prof Ansar Interested in coding challenge taker inmatlab
Hey Creative Coders! 😎
Let’s get to know each other. Drop a quick intro below and meet your teammates! This is your chance to meet teammates, find coding buddies, and build connections that make the contest more fun and rewarding!
You can share:
- Your name or nickname
- Where you’re from
- Your favorite coding topic or language
- What you’re most excited about in the contest
Let’s make Team Creative Coders an awesome community—jump in and say hi! 🚀
Welcome to the Cody Contest 2025 and the Creative Coders team channel! 🎉
You think outside the box. Where others see limitations, you see opportunities for innovation. This is your space to connect with like-minded coders, share insights, and help your team win. To make sure everyone has a great experience, please keep these tips in mind:
- Follow the Community Guidelines: Take a moment to review our community standards. Posts that don’t follow these guidelines may be flagged by moderators or community members.
- Ask Questions About Cody Problems: When asking for help, show your work! Include your code, error messages, and any details needed to reproduce your results. This helps others provide useful, targeted answers.
- Share Tips & Tricks: Knowledge sharing is key to success. When posting tips or solutions, explain how and why your approach works so others can learn your problem-solving methods.
- Provide Feedback: We value your feedback! Use this channel to report issues or share creative ideas to make the contest even better.
Have fun and enjoy the challenge! We hope you’ll learn new MATLAB skills, make great connections, and win amazing prizes! 🚀
как я получил api Token
I just learned you can access MATLAB Online from the following shortcut in your web browser: https://matlab.new
Thanks @Yann Debray
From his recent blog post: pip & uv in MATLAB Online » Artificial Intelligence - MATLAB & Simulink
Hey everyone,
I’m currently working with MATLAB R2025b and using the MQTT blocks from the Industrial Communication Toolbox inside Simulink. I’ve run into an issue that’s driving me a bit crazy, and I’m not sure if it’s a bug or if I’m missing something obvious.
Here’s what’s happening:
- I open the MQTT Configure block.
- I fill out all the required fields — Broker address, Port, Client ID, Username, and Password.
- When I click Test Connection, it says “Connection established successfully.” So far so good.
- Then I click Apply, close the dialog, set the topic name, and try to run the simulation.
- At this point, I get the following error:Caused by: Invalid value for 'ClientID', 'Username' or 'Password'.
- When I reopen the MQTT config block, I notice that the Password field is empty again — even though I definitely entered it before and the connection test worked earlier.
It seems like Simulink is somehow not saving the password after hitting Apply, which leads to the authentication error during simulation.
Has anyone else faced this? Is this a bug in R2025b, or do I need to configure something differently to make the password persist?
Would really appreciate any insights, workarounds, or confirmations from anyone who has used MQTT in Simulink recently.
Thanks in advance!
What if you had no isprime utility to rely on in MATLAB? How would you identify a number as prime? An easy answer might be something tricky, like that in simpleIsPrime0.
simpleIsPrime0 = @(N) ismember(N,primes(N));
But I’ll also disallow the use of primes here, as it does not really test to see if a number is prime. As well, it would seem horribly inefficient, generating a possibly huge list of primes, merely to learn something about the last member of the list.
Looking for a more serious test for primality, I’ve already shown how to lighten the load by a bit using roughness, to sometimes identify numbers as composite and therefore not prime.
https://www.mathworks.com/matlabcentral/discussions/tips/879745-primes-and-rough-numbers-basic-ideas
But to actually learn if some number is prime, we must do a little more. Yes, this is a common homework problem assigned to students, something we have seen many times on Answers. It can be approached in many ways too, so it is worth looking at the problem in some depth.
The definition of a prime number is a natural number greater than 1, which has only two factors, thus 1 and itself. That makes a simple test for primality of the number N easy. We just try dividing the number by every integer greater than 1, and not exceeding N-1. If any of those trial divides leaves a zero remainder, then N cannot be prime. And of course we can use mod or rem instead of an explicit divide, so we need not worry about floating point trash, as long as the numbers being tested are not too large.
simpleIsPrime1 = @(N) all(mod(N,2:N-1) ~= 0);
Of course, simpleIsPrime1 is not a good code, in the sense that it fails to check if N is an integer, or if N is less than or equal to 1. It is not vectorized, and it has no documentation at all. But it does the job well enough for one simple line of code. There is some virtue in simplicity after all, and it is certainly easy to read. But sometimes, I wish a function handle could include some help comments too! A feature request might be in the offing.
simpleIsPrime1(9931)
simpleIsPrime1(9932)
simpleIsPrime1 works quite nicely, and seems pretty fast. What could be wrong? At some point, the student is given a more difficult problem, to identify if a significantly larger integer is prime. simpleIsPrime1 will then cause a computer to grind to a distressing halt if given a sufficiently large number to test. Or it might even error out, when too large a vector of numbers was generated to test against. For example, I don't think you want to test a number of the order of 2^64 using simpleIsPrime1, as performing on the order of 2^64 divides will be highly time consuming.
uint64(2)^63-25
Is it prime? I’ve not tested it to learn if it is, and simpleIsPrime1 is not the tool to perform that test anyway.
A student might realize the largest possible integer factors of some number N are the numbers N/2 and N itself. But, if N/2 is a factor, then so is 2, and some thought would suggest it is sufficient to test only for factors that do not exceed sqrt(N). This is because if a is a divisor of N, then so is b=N/a. If one of them is larger than sqrt(N), then the other must be smaller. That could lead us to an improved scheme in simpleIsPrime2.
simpleIsPrime2 = @(N) all(mod(N,2:sqrt(N)));
For an integer of the size 2^64, now you only need to perform roughly 2^32 trial divides. Maybe we might consider the subtle improvement found in simpleIsPrime3, which avoids trial divides by the even integers greater than 2.
simpleIsPrime3 = @(N) (N == 2) || (mod(N,2) && all(mod(N,3:2:sqrt(N))));
simpleIsPrime3 needs only an approximate maximum of 2^31 trial divides even for numbers as large as uint64 can represent. While that is large, it is still generally doable on the computers we have today, even if it might be slow.
Sadly, my goals are higher than even the rather lofty limit given by UINT64 numbers. The problem of course is that a trial divide scheme, despite being 100% accurate in its assessment of primality, is a time hog. Even an O(sqrt(N)) scheme is far too slow for numbers with thousands or millions of digits. And even for a number as “small” as 1e100, a direct set of trial divides by all primes less than sqrt(1e100) would still be practically impossible, as there are roughly n/log(n) primes that do not exceed n. For an integer on the order of 1e50,
1e50/log(1e50)
It is practically impossible to perform that many divides on any computer we can make today. Can we do better? Is there some more efficient test for primality? For example, we could write a simple sieve of Eratosthenes to check each prime found not exceeding sqrt(N).
function [TF,SmallPrime] = simpleIsPrime4(N)
% simpleIsPrime3 - Sieve of Eratosthenes to identify if N is prime
% [TF,SmallPrime] = simpleIsPrime3(N)
%
% Returns true if N is prime, as well as the smallest prime factor
% of N when N is composite. If N is prime, then SmallPrime will be N.
Nroot = ceil(sqrt(N)); % ceil caters for floating point issues with the sqrt
TF = true;
SieveList = true(1,Nroot+1); SieveList(1) = false;
SmallPrime = 2;
while TF
% Find the "next" true element in SieveList
while (SmallPrime <= Nroot+1) && ~SieveList(SmallPrime)
SmallPrime = SmallPrime + 1;
end
% When we drop out of this loop, we have found the next
% small prime to check to see if it divides N, OR, we
% have gone past sqrt(N)
if SmallPrime > Nroot
% this is the case where we have now looked at all
% primes not exceeding sqrt(N), and have found none
% that divide N. This is where we will drop out to
% identify N as prime. TF is already true, so we need
% not set TF.
SmallPrime = N;
return
else
if mod(N,SmallPrime) == 0
% smallPrime does divide N, so we are done
TF = false;
return
end
% update SieveList
SieveList(SmallPrime:SmallPrime:Nroot) = false;
end
end
end
simpleIsPrime4 does indeed work reasonably well, though it is sometimes a little slower than is simpleIsPrime3, and everything is hugely faster than simpleIsPrime1.
timeit(@() simpleIsPrime1(111111111))
timeit(@() simpleIsPrime2(111111111))
timeit(@() simpleIsPrime3(111111111))
timeit(@() simpleIsPrime4(111111111))
All of those times will slow to a crawl for much larger numbers of course. And while I might find a way to subtly improve upon these codes, any improvement will be marginal in the end if I try to use any such direct approach to primality. We must look in a different direction completely to find serious gains.
At this point, I want to distinguish between two distinct classes of tests for primality of some large number. One class of test is what I might call an absolute or infallible test, one that is perfectly reliable. These are tests where if X is identified as prime/composite then we can trust the result absolutely. The tests I showed in the form of simpleIsPrime1, simpleIsPrime2, simpleIsPrime3 and aimpleIsprime4, were all 100% accurate, thus they fall into the class of infallible tests.
The second general class of test for primality is what I will call an evidentiary test. Such a test provides evidence, possibly quite strong evidence, that the given number is prime, but in some cases, it might be mistaken. I've already offered a basic example of a weak evidentiary test for primality in the form of roughness. All primes are maximally rough. And therefore, if you can identify X as being rough to some extent, this provides evidence that X is also prime, and the depth of the roughness test influences the strength of the evidence for primality. While this is generally a fairly weak test, it is a test nevertheless, and a good exclusionary test, a good way to avoid more sophisticated but time consuming tests.
These evidentiary tests all have the property that if they do identify X as being composite, then they are always correct. In the context of roughness, if X is not sufficiently rough, then X is also not prime. On the other side of the coin, if you can show X is at least (sqrt(X)+1)-rough, then it is positively prime. (I say this to suggest that some evidentiary tests for primality can be turned into truth telling tests, but that may take more effort than you can afford.) The problem is of course that is literally impossible to verify that degree of roughness for numbers with many thousands of digits.
In my next post, I'll look at the Fermat test for primality, based on Fermat's little theorem.
I saw an interesting problem on a reddit math forum today. The question was to find a number (x) as close as possible to r=3.6, but the requirement is that both x and 1/x be representable in a finite number of decimal places.
The problem of course is that 3.6 = 18/5. And the problem with 18/5 has an inverse 5/18, which will not have a finite representation in decimal form.
In order for a number and its inverse to both be representable in a finite number of decimal places (using base 10) we must have it be of the form 2^p*5^q, where p and q are integer, but may be either positive or negative. If that is not clear to you intuitively, suppose we have a form
2^p*5^-q
where p and q are both positive. All you need do is multiply that number by 10^q. All this does is shift the decimal point since you are just myltiplying by powers of 10. But now the result is
2^(p+q)
and that is clearly an integer, so the original number could be represented using a finite number of digits as a decimal. The same general idea would apply if p was negative, or if both of them were negative exponents.
Now, to return to the problem at hand... We can obviously adjust the number r to be 20/5 = 4, or 16/5 = 3.2. In both cases, since the fraction is now of the desired form, we are happy. But neither of them is really close to 3.6. My goal will be to find a better approximation, but hopefully, I can avoid a horrendous amount of trial and error. It would seem the trick might be to take logs, to get us closer to a solution. That is, suppose I take logs, to the base 2?
log2(3.6)
I used log2 here because that makes the problem a little simpler, since log2(2^p)=p. Therefore we want to find a pair of integers (p,q) such that
log2(3.6) + delta = p + log2(5)*q
where delta is as close to zero as possible. Thus delta is the error in our approximation to 3.6. And since we are working in logs, delta can be viewed as a proportional error term. Again, p and q may be any integers, either positive or negative. The two cases we have seen already have (p,q) = (2,0), and (4,-1).
Do you see the general idea? The line we have is of the form
log2(3.6) = p + log2(5)*q
it represents a line in the (p,q) plane, and we want to find a point on the integer lattice (p,q) where the line passes as closely as possible.
[Xl,Yl] = meshgrid([-10:10]);
plot(Xl,Yl,'k.')
hold on
fimplicit(@(p,q) -log2(3.6) + p + log2(5)*q,[-10,10,-10,10],'g-')
plot([2 4],[0,-1],'ro')
hold off
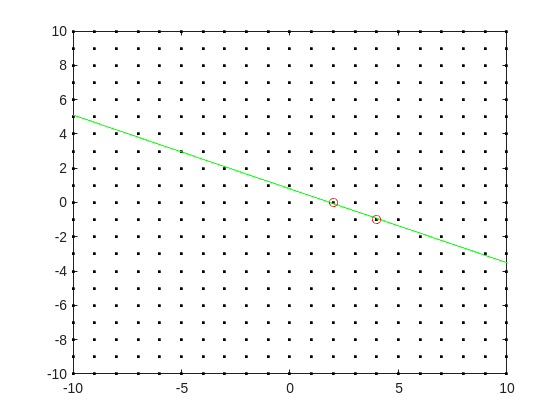
Now, some might think in terms of orthogonal distance to the line, but really, we want the vertical distance to be minimized. Again, minimize abs(delta) in the equation:
log2(3.6) + delta = p + log2(5)*q
where p and q are integer.
Can we do that using MATLAB? The skill about about mathematics often lies in formulating a word problem, and then turning the word problem into a problem of mathematics that we know how to solve. We are almost there now. I next want to formulate this into a problem that intlinprog can solve. The problem at first is intlinprog cannot handle absolute value constraints. And the trick there is to employ slack variables, a terribly useful tool to emply on this class of problem.
Rewrite delta as:
delta = Dpos - Dneg
where Dpos and Dneg are real variables, but both are constrained to be positive.
prob = optimproblem;
p = optimvar('p',lower = -50,upper = 50,type = 'integer');
q = optimvar('q',lower = -50,upper = 50,type = 'integer');
Dpos = optimvar('Dpos',lower = 0);
Dneg = optimvar('Dneg',lower = 0);
Our goal for the ILP solver will be to minimize Dpos + Dneg now. But since they must both be positive, it solves the min absolute value objective. One of them will always be zero.
r = 3.6;
prob.Constraints = log2(r) + Dpos - Dneg == p + log2(5)*q;
prob.Objective = Dpos + Dneg;
The solve is now a simple one. I'll tell it to use intlinprog, even though it would probably figure that out by itself. (Note: if I do not tell solve which solver to use, it does use intlinprog. But it also finds the correct solution when I told it to use GA offline.)
solve(prob,solver = 'intlinprog')
The solution it finds within the bounds of +/- 50 for both p and q seems pretty good. Note that Dpos and Dneg are pretty close to zero.
2^39*5^-16
and while 3.6028979... seems like nothing special, in fact, it is of the form we want.
R = sym(2)^39*sym(5)^-16
vpa(R,100)
vpa(1/R,100)
both of those numbers are exact. If I wanted to find a better approximation to 3.6, all I need do is extend the bounds on p and q. And we can use the same solution approch for any floating point number.
Since R2024b, a Levenberg–Marquardt solver (TrainingOptionsLM) was introduced. The built‑in function trainnet now accepts training options via the trainingOptions function (https://www.mathworks.com/help/deeplearning/ref/trainingoptions.html#bu59f0q-2) and supports the LM algorithm. I have been curious how to use it in deep learning, and the official documentation has not provided a concrete usage example so far. Below I give a simple example to illustrate how to use this LM algorithm to optimize a small number of learnable parameters.
For example, consider the nonlinear function:
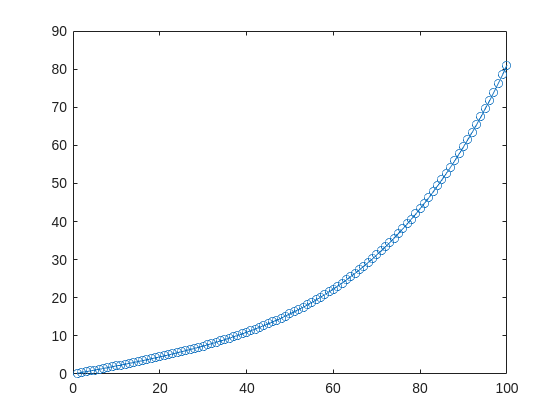
y_hat = @(a,t) a(1)*(t/100) + a(2)*(t/100).^2 + a(3)*(t/100).^3 + a(4)*(t/100).^4;
It represents a curve. Given 100 matching points (t → y_hat), we want to use least squares to estimate the four parameters a1–a4.
t = (1:100)';
y_hat = @(a,t)a(1)*(t/100) + a(2)*(t/100).^2 + a(3)*(t/100).^3 + a(4)*(t/100).^4;
x_true = [ 20 ; 10 ; 1 ; 50 ];
y_true = y_hat(x_true,t);
plot(t,y_true,'o-')
- Using the traditional lsqcurvefit-wrapped "Levenberg–Marquardt" algorithm:
x_guess = [ 5 ; 2 ; 0.2 ; -10 ];
options = optimoptions("lsqcurvefit",Algorithm="levenberg-marquardt",MaxFunctionEvaluations=800);
[x,resnorm,residual,exitflag] = lsqcurvefit(y_hat,x_guess,t,y_true,-50*ones(4,1),60*ones(4,1),options);
x,resnorm,exitflag
- Using the deep-learning-wrapped "Levenberg–Marquardt" algorithm:
options = trainingOptions("lm", ...
InitialDampingFactor=0.002, ...
MaxDampingFactor=1e9, ...
DampingIncreaseFactor=12, ...
DampingDecreaseFactor=0.2,...
GradientTolerance=1e-6, ...
StepTolerance=1e-6,...
Plots="training-progress");
numFeatures = 1;
layers = [featureInputLayer(numFeatures,'Name','input')
fitCurveLayer(Name='fitCurve')];
net = dlnetwork(layers);
XData = dlarray(t);
YData = dlarray(y_true);
netTrained = trainnet(XData,YData,net,"mse",options);
netTrained.Layers(2)
classdef fitCurveLayer < nnet.layer.Layer ...
& nnet.layer.Acceleratable
% Example custom SReLU layer.
properties (Learnable)
% Layer learnable parameters
a1
a2
a3
a4
end
methods
function layer = fitCurveLayer(args)
arguments
args.Name = "lm_fit";
end
% Set layer name.
layer.Name = args.Name;
% Set layer description.
layer.Description = "fit curve layer";
end
function layer = initialize(layer,~)
% layer = initialize(layer,layout) initializes the layer
% learnable parameters using the specified input layout.
if isempty(layer.a1)
layer.a1 = rand();
end
if isempty(layer.a2)
layer.a2 = rand();
end
if isempty(layer.a3)
layer.a3 = rand();
end
if isempty(layer.a4)
layer.a4 = rand();
end
end
function Y = predict(layer, X)
% Y = predict(layer, X) forwards the input data X through the
% layer and outputs the result Y.
% Y = layer.a1.*exp(-X./layer.a2) + layer.a3.*X.*exp(-X./layer.a4);
Y = layer.a1*(X/100) + layer.a2*(X/100).^2 + layer.a3*(X/100).^3 + layer.a4*(X/100).^4;
end
end
end
The network is very simple — only the fitCurveLayer defines the learnable parameters a1–a4. I observed that the output values are very close to those from lsqcurvefit.
Function Syntax Design Conundrum
As a MATLAB enthusiast, I particularly enjoy Steve Eddins' blog and the cool things he explores. MATLAB's new argument blocks are great, but there's one frustrating limitation that Steve outlined beautifully in his blog post "Function Syntax Design Conundrum": cases where an argument should accept both enumerated values AND other data types.
Steve points out this could be done using the input parser, but I prefer having tab completions and I'm not a fan of maintaining function signature JSON files for all my functions.
Personal Context on Enumerations
To be clear: I honestly don't like enumerations in any way, shape, or form. One reason is how awkward they are. I've long suspected they're simply predefined constructor calls with a set argument, and I think that's all but confirmed here. This explains why I've had to fight the enumeration system when trying to take arguments of many types and normalize them to enumerated members, or have numeric values displayed as enumerated members without being recast to the superclass every operation.
The Discovery
While playing around extensively with metadata for another project, I realized (and I'm entirely unsure why it took so long) that the properties of a metaclass object are just, in many cases, the attributes of the classdef. In this realization, I found a solution to Steve's and my problem.
To be clear: I'm not in love with this solution. I would much prefer a better approach for allowing variable sets of membership validation for arguments. But as it stands, we don't have that, so here's an interesting, if incredibly hacky, solution.
If you call struct() on a metaclass object to view its hidden properties, you'll notice that in addition to the public "Enumeration" property, there's a hidden "Enumerable" property. They're both logicals, which implies they're likely functionally distinct. I was curious about that distinction and hoped to find some functionality by intentionally manipulating these values - and I did, solving the exact problem Steve mentions.
The Problem Statement
We have a function with an argument that should allow "dual" input types: enumerated values (Steve's example uses days of the week, mine uses the "all" option available in various dimension-operating functions) AND integers. We want tab completion for the enumerated values while still accepting the numeric inputs.
A Solution for Tab-Completion Supported Arguments
Rather than spoil Steve's blog post, let me use my own example: implementing a none() function. The definition is simple enough tf = ~any(A, dim); but when we wrap this in another function, we lose the tab-completion that any() provides for the dim argument (which gives you "all"). There's no great way to implement this as a function author currently - at least, that's well documented.
So here's my solution:
%% Example Function Implementation
% This is a simple implementation of the DimensionArgument class for implementing dual type inputs that allow enumerated tab-completion.
function tf = none(A, dim)
arguments(Input)
A logical;
dim DimensionArgument = DimensionArgument(A, true);
end
% Simple example (notice the use of uplus to unwrap the hidden property)
tf = ~any(A, +dim);
end
I like this approach because the additional work required to implement it, once the enumeration class is initialized, is minimal. Here are examples of function calls, note that the behavior parallels that of the MATLAB native-style tab-completion:
%% Test Data
% Simple logical array for testing
A = randi([0, 1], [3, 5], "logical");
%% Example function calls
tf = none(A, "all"); % This is the tab-completion it's 1:1 with MATLABs behavior
tf = none(A, [1, 2]); % We can still use valid arguments (validated in the constructor)
tf = none(A); % Showcase of the constructors use as a default argument generator
How It Works
What makes this work is the previously mentioned Enumeration attribute. By setting Enumeration = false while still declaring an enumeration block in the classdef file, we get the suggested members as auto-complete suggestions. As I hinted at, the value of enumerations (if you don't subclass a builtin and define values with the someMember (1) syntax) are simply arguments to constructor calls.
We also get full control over the storage and handling of the class, which means we lose the implicit storage that enumerations normally provide and are responsible for doing so ourselves - but I much prefer this. We can implement internal validation logic to ensure values that aren't in the enumerated set still comply with our constraints, and store the input (whether the enumerated member or alternative type) in an internal property.
As seen in the example class below, this maintains a convenient interface for both the function caller and author the only particuarly verbose portion is the conversion methods... Which if your willing to double down on the uplus unwrapping context can be avoided. What I have personally done is overload the uplus function to return the input (or perform the identity property) this allowss for the uplus to be used universally to unwrap inputs and for those that cant, and dont have a uplus definition, the value itself is just returned:
classdef(Enumeration = false) DimensionArgument % < matlab.mixin.internal.MatrixDisplay
%DimensionArgument Enumeration class to provide auto-complete on functions needing the dimension type seen in all()
% Enumerations are just macros to make constructor calls with a known set of arguments. Declaring the 'all'
% enumeration member means this class can be set as the type for an input and the auto-completion for the given
% argument will show the enumeration members, allowing tab-completion. Declaring the Enumeration attribute of
% the class as false gives us control over the constructor and internal implementation. As such we can use it
% to validate the numeric inputs, in the event the 'all' option was not used, and return an object that will
% then work in place of valid dimension argument options.
%% Enumeration members
% These are the auto-complete options you'd like to make available for the function signature for a given
% argument.
enumeration(Description="Enumerated value for the dimension argument.")
all
end
%% Properties
% The internal property allows the constructor's input to be stored; this ensures that the value is store and
% that the output of the constructor has the class type so that the validation passes.
% (Constructors must return the an object of the class they're a constructor for)
properties(Hidden, Description="Storage of the constructor input for later use.")
Data = [];
end
%% Constructor method
% By the magic of declaring (Enumeration = false) in our class def arguments we get full control over the
% constructor implementation.
%
% The second argument in this specific instance is to enable the argument's default value to be set in the
% arguments block itself as opposed to doing so in the function body... I like this better but if you didn't
% you could just as easily keep the constructor simple.
methods
function obj = DimensionArgument(A, Adim)
%DimensionArgument Initialize the dimension argument.
arguments
% This will be the enumeration member name from auto-completed entries, or the raw user input if not
% used.
A = [];
% A flag that indicates to create the value using different logic, in this case the first non-singleton
% dimension, because this matches the behavior of functions like, all(), sum() prod(), etc.
Adim (1, 1) logical = false;
end
if(Adim)
% Allows default initialization from an input to match the aforemention function's behavior
obj.Data = firstNonscalarDim(A);
else
% As a convenience for this style of implementation we can validate the input to ensure that since we're
% suppose to be an enumeration, the input is valid
DimensionArgument.mustBeValidMember(A);
% Store the input in a hidden property since declaring ~Enumeration means we are responsible for storing
% it.
obj.Data = A;
end
end
end
%% Conversion methods
% Applies conversion to the data property so that implicit casting of functions works. Unfortunately most of
% the MathWorks defined functions use a different system than that employed by the arguments block, which
% defers to the class defined converter methods... Which is why uplus (+obj) has been defined to unwrap the
% data for ease of use.
methods
function obj = uplus(obj)
obj = obj.Data;
end
function str = char(obj)
str = char(obj.Data);
end
function str = cellstr(obj)
str = cellstr(obj.Data);
end
function str = string(obj)
str = string(obj.Data);
end
function A = double(obj)
A = double(obj.Data);
end
function A = int8(obj)
A = int8(obj.Data);
end
function A = int16(obj)
A = int16(obj.Data);
end
function A = int32(obj)
A = int32(obj.Data);
end
function A = int64(obj)
A = int64(obj.Data);
end
end
%% Validation methods
% These utility methods are for input validation
methods(Static, Access = private)
function tf = isValidMember(obj)
%isValidMember Checks that the input is a valid dimension argument.
tf = (istext(obj) && all(obj == "all", "all")) || (isnumeric(obj) && all(isint(obj) & obj > 0, "all"));
end
function mustBeValidMember(obj)
%mustBeValidMember Validates that the input is a valid dimension argument for the dim/dimVec arguments.
if(~DimensionArgument.isValidMember(obj))
exception("JB:DimensionArgument:InvalidInput", "Input must be an integer value or the term 'all'.")
end
end
end
%% Convenient data display passthrough
methods
function disp(obj, name)
arguments
obj DimensionArgument
name string {mustBeScalarOrEmpty} = [];
end
% Dispatch internal data's display implementation
display(obj.Data, char(name));
end
end
end
In the event you'd actually play with theres here are the function definitions for some of the utility functions I used in them, including my exception would be a pain so i wont, these cases wont use it any...
% Far from my definition isint() but is consistent with mustBeInteger() for real numbers but will suffice for the example
function tf = isint(A)
arguments
A {mustBeNumeric(A)};
end
tf = floor(A) == A
end
% Sort of the same but its fine
function dim = firstNonscalarDim(A)
arguments
A
end
dim = [find(size(A) > 1, 1), 0];
dim(1) = dim(1);
end