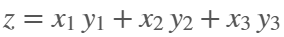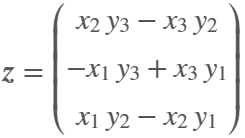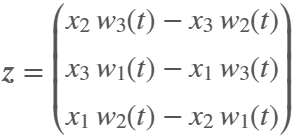What if you had no isprime utility to rely on in MATLAB? How would you identify a number as prime? An easy answer might be something tricky, like that in simpleIsPrime0.
simpleIsPrime0 = @(N) ismember(N,primes(N));
But I’ll also disallow the use of primes here, as it does not really test to see if a number is prime. As well, it would seem horribly inefficient, generating a possibly huge list of primes, merely to learn something about the last member of the list.
Looking for a more serious test for primality, I’ve already shown how to lighten the load by a bit using roughness, to sometimes identify numbers as composite and therefore not prime.
But to actually learn if some number is prime, we must do a little more. Yes, this is a common homework problem assigned to students, something we have seen many times on Answers. It can be approached in many ways too, so it is worth looking at the problem in some depth.
The definition of a prime number is a natural number greater than 1, which has only two factors, thus 1 and itself. That makes a simple test for primality of the number N easy. We just try dividing the number by every integer greater than 1, and not exceeding N-1. If any of those trial divides leaves a zero remainder, then N cannot be prime. And of course we can use mod or rem instead of an explicit divide, so we need not worry about floating point trash, as long as the numbers being tested are not too large.
simpleIsPrime1 = @(N) all(mod(N,2:N-1) ~= 0);
Of course, simpleIsPrime1 is not a good code, in the sense that it fails to check if N is an integer, or if N is less than or equal to 1. It is not vectorized, and it has no documentation at all. But it does the job well enough for one simple line of code. There is some virtue in simplicity after all, and it is certainly easy to read. But sometimes, I wish a function handle could include some help comments too! A feature request might be in the offing.
simpleIsPrime1 works quite nicely, and seems pretty fast. What could be wrong? At some point, the student is given a more difficult problem, to identify if a significantly larger integer is prime. simpleIsPrime1 will then cause a computer to grind to a distressing halt if given a sufficiently large number to test. Or it might even error out, when too large a vector of numbers was generated to test against. For example, I don't think you want to test a number of the order of 2^64 using simpleIsPrime1, as performing on the order of 2^64 divides will be highly time consuming.
uint64(2)^63-25
ans =
9223372036854775783
Is it prime? I’ve not tested it to learn if it is, and simpleIsPrime1 is not the tool to perform that test anyway.
A student might realize the largest possible integer factors of some number N are the numbers N/2 and N itself. But, if N/2 is a factor, then so is 2, and some thought would suggest it is sufficient to test only for factors that do not exceed sqrt(N). This is because if a is a divisor of N, then so is b=N/a. If one of them is larger than sqrt(N), then the other must be smaller. That could lead us to an improved scheme in simpleIsPrime2.
simpleIsPrime2 = @(N) all(mod(N,2:sqrt(N)));
For an integer of the size 2^64, now you only need to perform roughly 2^32 trial divides. Maybe we might consider the subtle improvement found in simpleIsPrime3, which avoids trial divides by the even integers greater than 2.
simpleIsPrime3 = @(N) (N == 2) || (mod(N,2) && all(mod(N,3:2:sqrt(N))));
simpleIsPrime3 needs only an approximate maximum of 2^31 trial divides even for numbers as large as uint64 can represent. While that is large, it is still generally doable on the computers we have today, even if it might be slow.
Sadly, my goals are higher than even the rather lofty limit given by UINT64 numbers. The problem of course is that a trial divide scheme, despite being 100% accurate in its assessment of primality, is a time hog. Even an O(sqrt(N)) scheme is far too slow for numbers with thousands or millions of digits. And even for a number as “small” as 1e100, a direct set of trial divides by all primes less than sqrt(1e100) would still be practically impossible, as there are roughly n/log(n) primes that do not exceed n. For an integer on the order of 1e50,
It is practically impossible to perform that many divides on any computer we can make today. Can we do better? Is there some more efficient test for primality? For example, we could write a simple sieve of Eratosthenes to check each prime found not exceeding sqrt(N).
function [TF,SmallPrime] = simpleIsPrime4(N)
SieveList = true(1,Nroot+1); SieveList(1) = false;
while (SmallPrime <= Nroot+1) && ~SieveList(SmallPrime)
SmallPrime = SmallPrime + 1;
if mod(N,SmallPrime) == 0
SieveList(SmallPrime:SmallPrime:Nroot) = false;
simpleIsPrime4 does indeed work reasonably well, though it is sometimes a little slower than is simpleIsPrime3, and everything is hugely faster than simpleIsPrime1.
timeit(@() simpleIsPrime1(111111111))
timeit(@() simpleIsPrime2(111111111))
timeit(@() simpleIsPrime3(111111111))
timeit(@() simpleIsPrime4(111111111))
All of those times will slow to a crawl for much larger numbers of course. And while I might find a way to subtly improve upon these codes, any improvement will be marginal in the end if I try to use any such direct approach to primality. We must look in a different direction completely to find serious gains.
At this point, I want to distinguish between two distinct classes of tests for primality of some large number. One class of test is what I might call an absolute or infallible test, one that is perfectly reliable. These are tests where if X is identified as prime/composite then we can trust the result absolutely. The tests I showed in the form of simpleIsPrime1, simpleIsPrime2, simpleIsPrime3 and aimpleIsprime4, were all 100% accurate, thus they fall into the class of infallible tests.
The second general class of test for primality is what I will call an evidentiary test. Such a test provides evidence, possibly quite strong evidence, that the given number is prime, but in some cases, it might be mistaken. I've already offered a basic example of a weak evidentiary test for primality in the form of roughness. All primes are maximally rough. And therefore, if you can identify X as being rough to some extent, this provides evidence that X is also prime, and the depth of the roughness test influences the strength of the evidence for primality. While this is generally a fairly weak test, it is a test nevertheless, and a good exclusionary test, a good way to avoid more sophisticated but time consuming tests.
These evidentiary tests all have the property that if they do identify X as being composite, then they are always correct. In the context of roughness, if X is not sufficiently rough, then X is also not prime. On the other side of the coin, if you can show X is at least (sqrt(X)+1)-rough, then it is positively prime. (I say this to suggest that some evidentiary tests for primality can be turned into truth telling tests, but that may take more effort than you can afford.) The problem is of course that is literally impossible to verify that degree of roughness for numbers with many thousands of digits.
In my next post, I'll look at the Fermat test for primality, based on Fermat's little theorem.
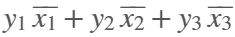
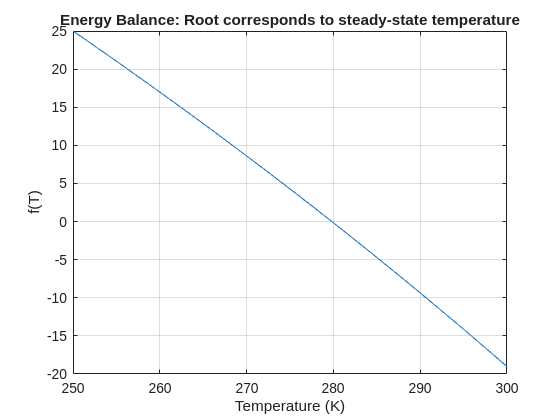
 = 25 W
= 25 W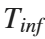 = 250 K
= 250 K