Machine Learning Fundamentals | Introduction to Machine Learning, Part 1
From the series: Introduction to Machine Learning
Explore the fundamentals behind machine learning. Learn about two common Machine learning approaches:
- Unsupervised learning, which finds hidden patterns in input data
- Supervised learning, which trains a model on known input and output data so that it can predict future outputs
You’ll also learn about three common techniques within these approaches:
- Clustering techniques put data into different groups based on shared characteristics in the data.
- Classification techniques predict discrete responses—like whether an email is genuine or spam.
- Regression techniques predict continuous responses, such as what temperature a thermostat should be set at or fluctuations in electricity demand.
Published: 6 Dec 2018
Today, we’ll talk about machine learning. We’ll focus on what it is and why you’d want to use it.
Machine learning teaches computers to do what comes naturally to humans: learn from experience.
It is great for complex problems involving a large amount of data with lots of variables, but no existing formula or equation that describes the system.
Some common scenarios where machine learning applies include:
- When a system is too complex for handwritten rules, like in face and speech recognition.
- When the rules of a task are constantly changing, as in fraud detection.
- And when the nature of the data itself keeps changing, like in automated trading, energy demand forecasting, and predicting shopping trends.
Machine learning uses two types of techniques:
- Unsupervised learning, which finds hidden patterns in input data,
- And supervised learning, which trains a model on known input and output data so that it can predict future outputs.
Unsupervised learning draws inferences from datasets that don’t have labeled responses associated with the input data.
Clustering is the most common unsupervised learning technique. It puts data into different groups based on shared characteristics in the data.
Clustering is used to find hidden groupings in applications such as gene sequence analysis, market research, and object recognition among many others.
On the other hand, supervised learning requires each example of the input data to come with a correctly labeled output. It uses this labeled data, along with classification and regression techniques, to develop predictive models.
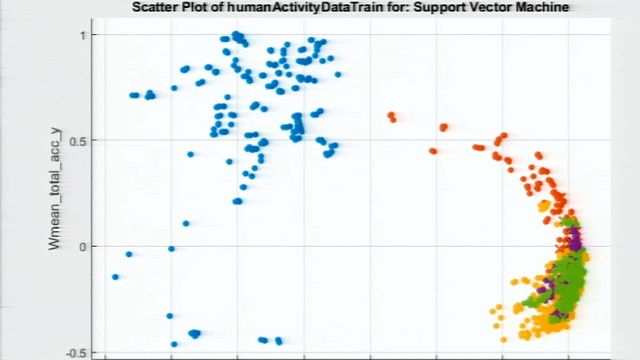
Classification techniques predict discrete responses—like whether an email is genuine or spam. Essentially, these models classify input data into a pre-determined set of categories.
Regression techniques predict continuous responses— like what temperature a thermostat should be set at or fluctuations in electricity demand.
Again, the big difference here between supervised learning and unsupervised learning is that supervised learning requires correctly labeled examples to train the machine learning model, and then uses that model to label new data.
Keep in mind: the techniques you use, and the algorithms you select, depend on the size and type of data you’re working with, the insights you want to get from the data, and how those insights will be used. We’ll talk more about these techniques in the next few videos.
For now, that was a very brief overview of machine learning. Be sure to check out the description for more information.