lstmLayer
Long short-term memory (LSTM) layer for recurrent neural network (RNN)
Description
An LSTM layer is an RNN layer that learns long-term dependencies between time steps in time-series and sequence data.
The layer performs additive interactions, which can help improve gradient flow over long sequences during training.
Creation
Description
layer = lstmLayer(numHiddenUnits)NumHiddenUnits property.
layer = lstmLayer(numHiddenUnits,Name=Value)OutputMode, Activations, State, Parameters and Initialization, Learning Rate and Regularization, and
Name
properties using one or more name-value arguments.
Properties
Examples
Create an LSTM layer with the name "lstm1" and 100 hidden units.
layer = lstmLayer(100,Name="lstm1")layer =
LSTMLayer with properties:
Name: 'lstm1'
InputNames: {'in'}
OutputNames: {'out'}
NumInputs: 1
NumOutputs: 1
HasStateInputs: 0
HasStateOutputs: 0
Hyperparameters
InputSize: 'auto'
NumHiddenUnits: 100
OutputMode: 'sequence'
StateActivationFunction: 'tanh'
GateActivationFunction: 'sigmoid'
Learnable Parameters
InputWeights: []
RecurrentWeights: []
Bias: []
State Parameters
HiddenState: []
CellState: []
Show all properties
Include an LSTM layer in a Layer array.
inputSize = 12;
numHiddenUnits = 100;
numClasses = 9;
layers = [ ...
sequenceInputLayer(inputSize)
lstmLayer(numHiddenUnits)
fullyConnectedLayer(numClasses)
softmaxLayer]layers =
4×1 Layer array with layers:
1 '' Sequence Input Sequence input with 12 channels
2 '' LSTM LSTM with 100 hidden units
3 '' Fully Connected Fully connected layer with output size 9
4 '' Softmax Softmax
Train a deep learning LSTM network for sequence-to-label classification.
Load the example data from WaveformData.mat. The data is a numObservations-by-1 cell array of sequences, where numObservations is the number of sequences. Each sequence is a numTimeSteps-by-numChannels numeric array, where numTimeSteps is the number of time steps of the sequence and numChannels is the number of channels of the sequence.
load WaveformDataVisualize some of the sequences in a plot.
numChannels = size(data{1},2);
idx = [3 4 5 12];
figure
tiledlayout(2,2)
for i = 1:4
nexttile
stackedplot(data{idx(i)},DisplayLabels="Channel "+string(1:numChannels))
xlabel("Time Step")
title("Class: " + string(labels(idx(i))))
end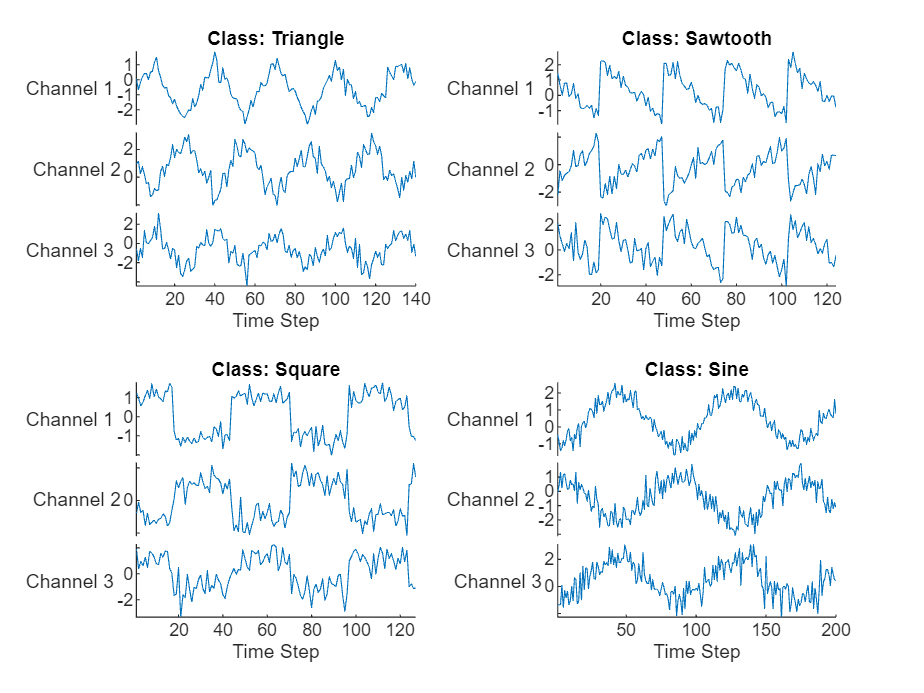
View the class names.
classNames = categories(labels)
classNames = 4×1 cell
{'Sawtooth'}
{'Sine' }
{'Square' }
{'Triangle'}
Set aside data for testing. Partition the data into a training set containing 90% of the data and a test set containing the remaining 10% of the data. To partition the data, use the trainingPartitions function, attached to this example as a supporting file. To access this file, open the example as a live script.
numObservations = numel(data); [idxTrain,idxTest] = trainingPartitions(numObservations, [0.9 0.1]); XTrain = data(idxTrain); TTrain = labels(idxTrain); XTest = data(idxTest); TTest = labels(idxTest);
Define the LSTM network architecture. Specify the input size as the number of channels of the input data. Specify an LSTM layer to have 120 hidden units and to output the last element of the sequence. Finally, include a fully connected with an output size that matches the number of classes, followed by a softmax layer.
numHiddenUnits = 120; numClasses = numel(categories(TTrain)); layers = [ ... sequenceInputLayer(numChannels) lstmLayer(numHiddenUnits,OutputMode="last") fullyConnectedLayer(numClasses) softmaxLayer]
layers =
4×1 Layer array with layers:
1 '' Sequence Input Sequence input with 3 dimensions
2 '' LSTM LSTM with 120 hidden units
3 '' Fully Connected 4 fully connected layer
4 '' Softmax softmax
Specify the training options. Train using the Adam solver with a learn rate of 0.01 and a gradient threshold of 1. Set the maximum number of epochs to 200 and shuffle every epoch. The software, by default, trains on a GPU if one is available. Using a GPU requires Parallel Computing Toolbox and a supported GPU device. For information on supported devices, see GPU Computing Requirements (Parallel Computing Toolbox).
options = trainingOptions("adam", ... MaxEpochs=200, ... InitialLearnRate=0.01,... Shuffle="every-epoch", ... GradientThreshold=1, ... Verbose=false, ... Metrics="accuracy", ... Plots="training-progress");
Train the LSTM network using the trainnet function. For classification, use cross-entropy loss.
net = trainnet(XTrain,TTrain,layers,"crossentropy",options);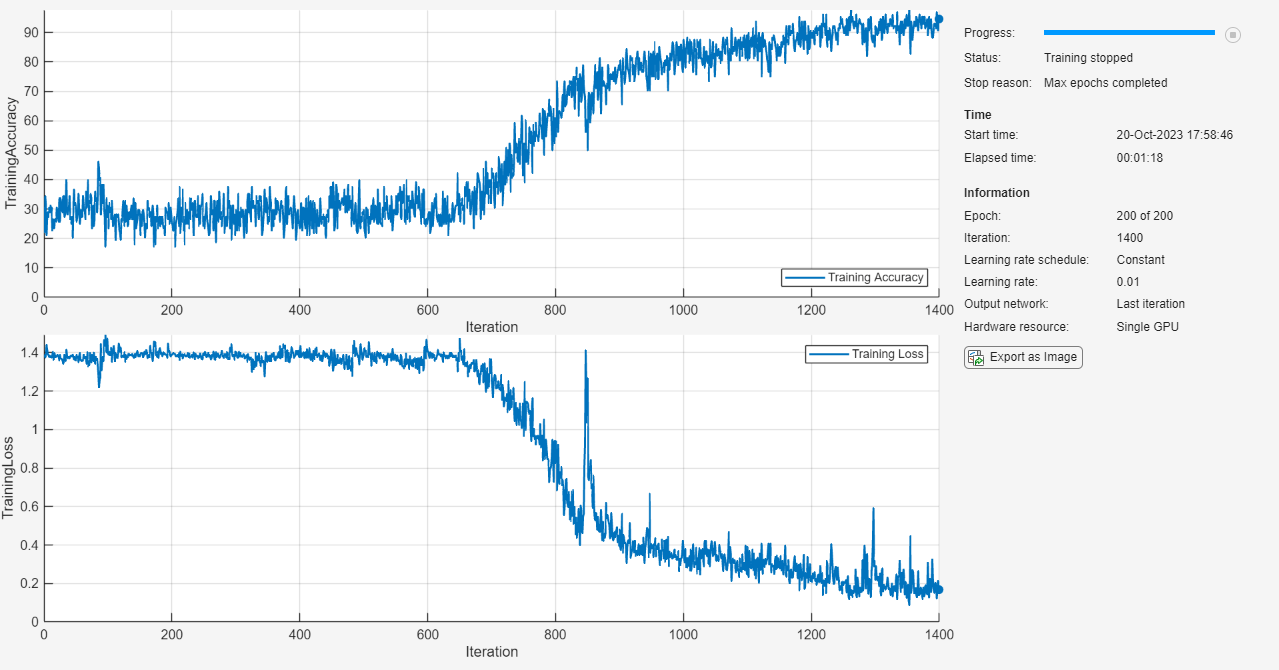
Classify the test data. Specify the same mini-batch size used for training.
scores = minibatchpredict(net,XTest); YTest = scores2label(scores,classNames);
Calculate the classification accuracy of the predictions.
acc = mean(YTest == TTest)
acc = 0.8700
Display the classification results in a confusion chart.
figure confusionchart(TTest,YTest)

To create an LSTM network for sequence-to-label classification, create a layer array containing a sequence input layer, an LSTM layer, a fully connected layer, and a softmax layer.
Set the size of the sequence input layer to the number of features of the input data. Set the size of the fully connected layer to the number of classes. You do not need to specify the sequence length.
For the LSTM layer, specify the number of hidden units and the output mode "last".
numFeatures = 12; numHiddenUnits = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,OutputMode="last") fullyConnectedLayer(numClasses) softmaxLayer];
For an example showing how to train an LSTM network for sequence-to-label classification and classify new data, see Sequence Classification Using Deep Learning.
To create an LSTM network for sequence-to-sequence classification, use the same architecture as for sequence-to-label classification, but set the output mode of the LSTM layer to "sequence".
numFeatures = 12; numHiddenUnits = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,OutputMode="sequence") fullyConnectedLayer(numClasses) softmaxLayer];
To create an LSTM network for sequence-to-one regression, create a layer array containing a sequence input layer, an LSTM layer, and a fully connected layer.
Set the size of the sequence input layer to the number of features of the input data. Set the size of the fully connected layer to the number of responses. You do not need to specify the sequence length.
When you train the neural network, you can automatically normalize the training targets using the NormalizeTargets training option (introduced in R2026a). Using normalized targets helps stabilize training and results in training predictions that closely match the normalized targets. To make the neural network output predictions in the space of unnormalized values at prediction time only, include an inverse normalization layer (introduced in R2026a). Before R2026a: To stabilize training, normalize the targets manually before you train the neural network.
For the LSTM layer, specify the number of hidden units and the output mode "last".
numFeatures = 12; numHiddenUnits = 125; numResponses = 1; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,OutputMode="last") fullyConnectedLayer(numResponses) inverseNormalizationLayer];
To create an LSTM network for sequence-to-sequence regression, use the same architecture as for sequence-to-one regression, but set the output mode of the LSTM layer to "sequence".
numFeatures = 12; numHiddenUnits = 125; numResponses = 1; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits,OutputMode="sequence") fullyConnectedLayer(numResponses) inverseNormalizationLayer];
For an example showing how to train an LSTM network for sequence-to-sequence regression and predict on new data, see Sequence-to-Sequence Regression Using Deep Learning.
You can make LSTM networks deeper by inserting extra LSTM layers with the output mode "sequence" before the LSTM layer. To prevent overfitting, you can insert dropout layers after the LSTM layers.
For sequence-to-label classification networks, the output mode of the last LSTM layer must be "last".
numFeatures = 12; numHiddenUnits1 = 125; numHiddenUnits2 = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits1,OutputMode="sequence") dropoutLayer(0.2) lstmLayer(numHiddenUnits2,OutputMode="last") dropoutLayer(0.2) fullyConnectedLayer(numClasses) softmaxLayer];
For sequence-to-sequence classification networks, the output mode of the last LSTM layer must be "sequence".
numFeatures = 12; numHiddenUnits1 = 125; numHiddenUnits2 = 100; numClasses = 9; layers = [ ... sequenceInputLayer(numFeatures) lstmLayer(numHiddenUnits1,OutputMode="sequence") dropoutLayer(0.2) lstmLayer(numHiddenUnits2,OutputMode="sequence") dropoutLayer(0.2) fullyConnectedLayer(numClasses) softmaxLayer];
Algorithms
An LSTM layer is an RNN layer that learns long-term dependencies between time steps in time-series and sequence data.
The state of the layer consists of the hidden state (also known as the output state) and the cell state. The hidden state at time step t contains the output of the LSTM layer for this time step. The cell state contains information learned from the previous time steps. At each time step, the layer adds information to or removes information from the cell state. The layer controls these updates using gates.
These components control the cell state and hidden state of the layer.
| Component | Purpose |
|---|---|
| Input gate (i) | Control level of cell state update |
| Forget gate (f) | Control level of cell state reset (forget) |
| Cell candidate (g) | Add information to cell state |
| Output gate (o) | Control level of cell state added to hidden state |
This diagram illustrates the flow of data at time step t. This diagram shows how the gates forget, update, and output the cell and hidden states.

The learnable weights of an LSTM layer are the input weights W
(InputWeights), the recurrent weights R
(RecurrentWeights), and the bias b
(Bias). The matrices W, R,
and b are concatenations of the input weights, the recurrent weights, and
the bias of each component, respectively. The layer concatenates the matrices according to
these equations:
where i, f, g, and o denote the input gate, forget gate, cell candidate, and output gate, respectively.
The cell state at time step t is given by
where denotes the Hadamard product (element-wise multiplication of vectors).
The hidden state at time step t is given by
where denotes the state activation function. By default, the
lstmLayer function uses the hyperbolic tangent function (tanh) to
compute the state activation function.
These formulas describe the components at time step t.
| Component | Formula |
|---|---|
| Input gate | |
| Forget gate | |
| Cell candidate | |
| Output gate |
In these calculations, denotes the gate activation function. By default, the
lstmLayer function, uses the sigmoid function, given by , to compute the gate activation function.
References
[1] Hochreiter, S, and J. Schmidhuber, 1997. Long short-term memory. Neural computation, 9(8), pp.1735–1780.
[2] Glorot, Xavier, and Yoshua Bengio. "Understanding the Difficulty of Training Deep Feedforward Neural Networks." In Proceedings of the Thirteenth International Conference on Artificial Intelligence and Statistics, 249–356. Sardinia, Italy: AISTATS, 2010. https://proceedings.mlr.press/v9/glorot10a/glorot10a.pdf
[3] He, Kaiming, Xiangyu Zhang, Shaoqing Ren, and Jian Sun. "Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification." In 2015 IEEE International Conference on Computer Vision (ICCV), 1026–34. Santiago, Chile: IEEE, 2015. https://doi.org/10.1109/ICCV.2015.123
[4] Saxe, Andrew M., James L. McClelland, and Surya Ganguli. "Exact Solutions to the Nonlinear Dynamics of Learning in Deep Linear Neural Networks.” Preprint, submitted February 19, 2014. https://arxiv.org/abs/1312.6120.
Extended Capabilities
Version History
Introduced in R2017bSee Also
trainnet | trainingOptions | dlnetwork | sequenceInputLayer | bilstmLayer | gruLayer | convolution1dLayer | maxPooling1dLayer | averagePooling1dLayer | globalMaxPooling1dLayer | globalAveragePooling1dLayer | Deep Network
Designer | exportNetworkToSimulink | LSTM Layer
Topics
- Sequence Classification Using Deep Learning
- Sequence Classification Using 1-D Convolutions
- Time Series Forecasting Using Deep Learning
- Sequence-to-Sequence Classification Using Deep Learning
- Sequence-to-Sequence Regression Using Deep Learning
- Sequence-to-One Regression Using Deep Learning
- Classify Videos Using Deep Learning
- Long Short-Term Memory Neural Networks
- List of Deep Learning Layers
- Deep Learning Tips and Tricks