Optimize Generated Code Using Code Efficiency Tools and Techniques
When generating production code from your model to deploy into a real-time embedded system, code efficiency is an important consideration. Based on your target hardware and application, you might need to deploy code that is faster and memory efficient. To accommodate your efficiency needs, Embedded Coder® provides optimization parameters that you can set to implement certain optimizations in the generated code.
However, if the efficiency of the generated code does not meet your requirements, review the tips and techniques discussed below and choose an approach for your model.
Techniques to Refine Models for Efficient Code Generation
Optimal parameter settings, efficient modeling patterns, and specifying an appropriate optimization goal are prerequisites for efficient code generation. Use the design techniques discussed in Design Techniques to Optimize Models for Efficient Code Generation while designing your model. After developing your model, refine it focusing on code efficiency goal by using the following techniques.
Refine Parameter Settings Based on Code Efficiency Objectives
Use the Code Generation Advisor to analyze your model for code efficiency objectives and identify aspects of the model that do not impede the objectives. You can select multiple objectives and can prioritize them. The Code Generation Advisor checks the model and provides recommended actions for configuration and block parameter settings that can limit efficiency objectives.
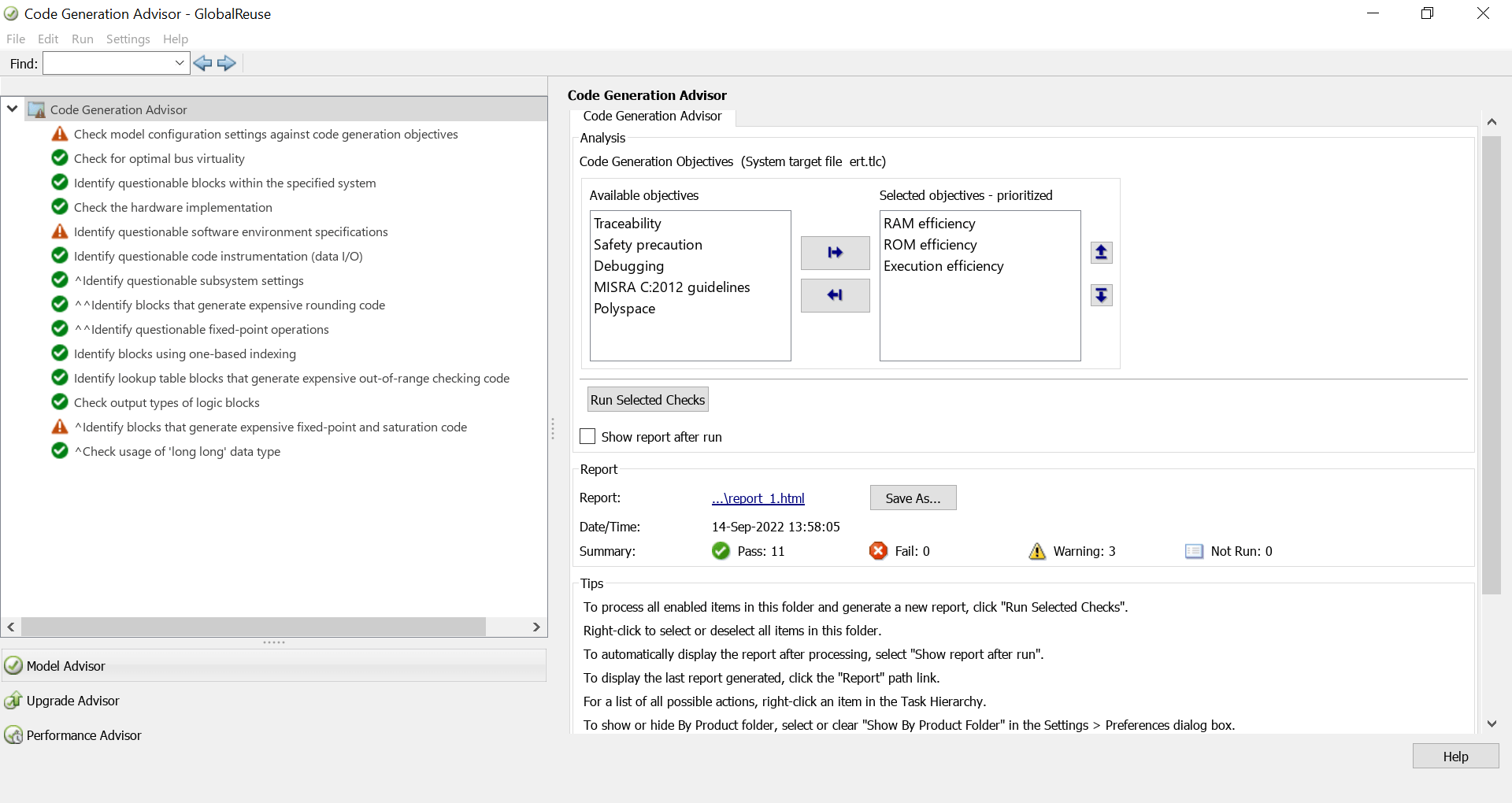
For more information, see Configure Model for Code Generation Objectives by Using Code Generation Advisor.
Identify and Refactor Inefficient Modeling Patterns
Inefficient modeling patterns in your model can lead to inefficient code generation. Consider using the refactoring tools Clone Detector (Simulink Check) and Model Transformer (Simulink Check) to identify the inefficient modeling patterns that qualify for automatic replacement with more efficient patterns.
To identify clones in your model that have identical block types and connections, use Clone Detector. After analysis, the tool displays the percentage of clones present in the model. If your model contains a high percentage of clones, refactoring can be beneficial from the efficiency standpoint. Using the tool, you can automatically create library blocks for repeated clone patterns and then replace the clones with links to the library blocks.
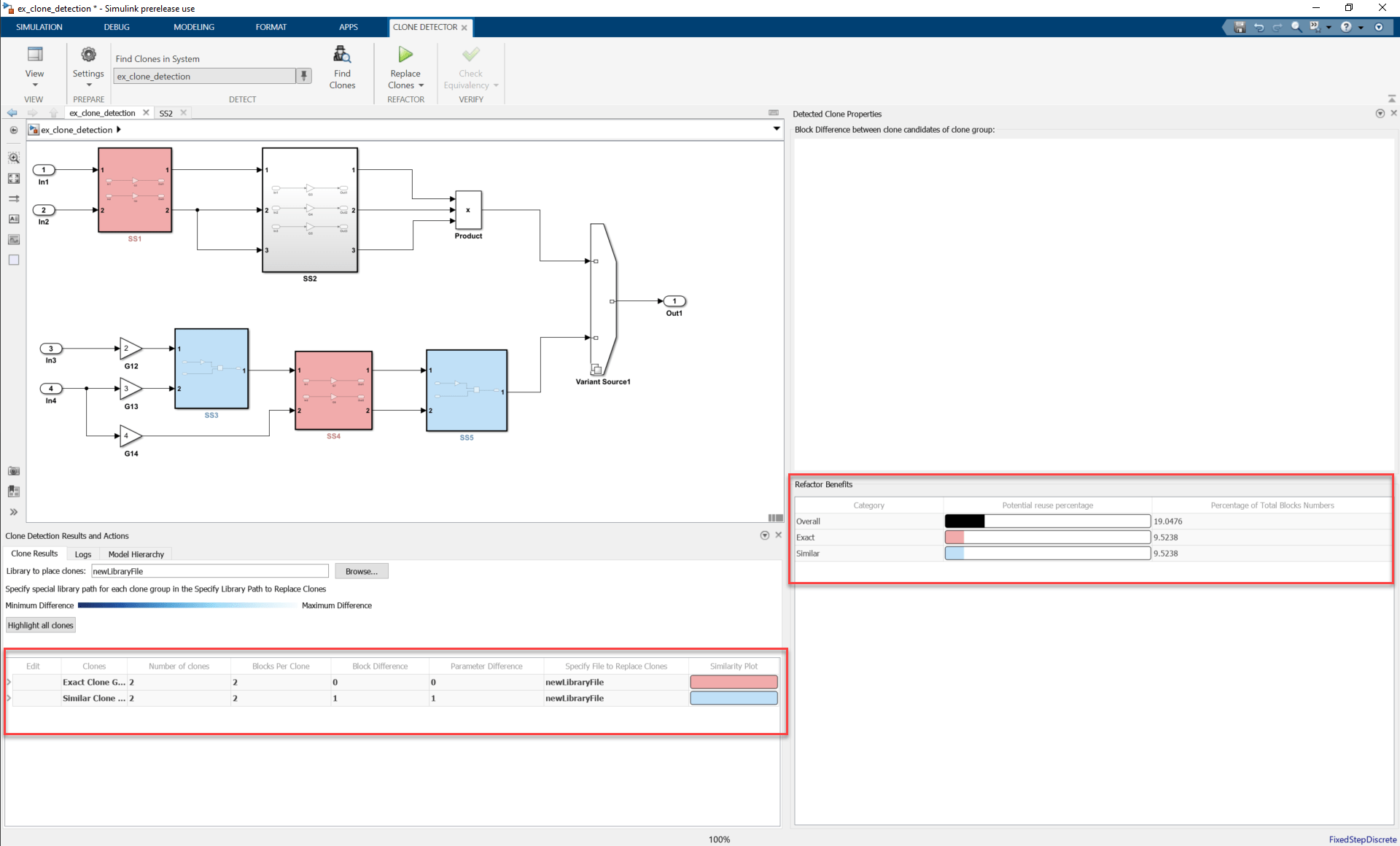
For example, the ex_clone_detection model contains 19.047% overall
clones and refactoring the model for all clone groups can reduce 19.047% of the model
reuse. For more information, see Enable Component Reuse by Using Clone Detection (Simulink Check).
Similarly, using Model Transformer, you can identify and:
Transform qualified modeling patterns into Variant Source or Variant Subsystem blocks. Using Variant Subsystem and Variant Source blocks improves the reusability of a model for different variant choices. For more information, see Transform Model to Variant System (Simulink Check).
Replace qualified Data Store blocks with either a direct signal line, a Delay block, or a Merge block to reduce model complexity. For more information, see Improve Model Readability by Eliminating Local Data Store Blocks (Simulink Check).
Convert qualified multiple n-D Lookup Table blocks into shared Prelookup blocks and multiple Interpolation blocks. Eliminating the redundant Prelookup blocks can improve code efficiency. For more information, see Improve Efficiency of Simulation by Optimizing Prelookup Operation of Lookup Table Blocks (Simulink Check).
Convert qualified multiple Interpolation Using Prelookup blocks into a single Interpolation Using Prelookup block. Reducing the number of Interpolation Using Prelookup blocks reduces the number of variable assignments in the code, which improves code efficiency. For more information, see Improve Code Efficiency by Merging Multiple Interpolation Using Prelookup Blocks (Simulink Check).
The refactored model has the same functionality as the original model. To verify the equivalence, use Simulink® Test™.
Specify Optimization Level and Priority
By setting the Level and Priority configuration parameters, you can optimize the generated code for increased execution efficiency, decreased RAM consumption, or a balance between execution efficiency and RAM consumption. To implement the desired optimization specified in the Priority and Level, the code generator automatically sets values for the parameters in the Details section. For more information on how the parameters in Details are configured for different optimization goals, see Tips.
Techniques to Identify Areas for Optimizing Memory Usage
If the generated code does not meet your memory requirements or contains unnecessary data copies, you can identify areas where further memory optimization is possible by using these techniques:
Generate code with bidirectional traceability: Studying the generated code using Model-to-Code Traceability and Code-to-Model Traceability can help you identifying the root cause of the code inefficiency. Also, you can investigate whether a data copy is necessary or whether you can remove it from the generated code by using one of the techniques discussed in Techniques to Optimize Code for Memory Efficiency.
Generate a static metric report: The code generator performs static analysis on the generated code. When you select the Generate static code metrics parameter, the code generator provides the static metrics in the Static Code Metrics Report section of the HTML code generation report.
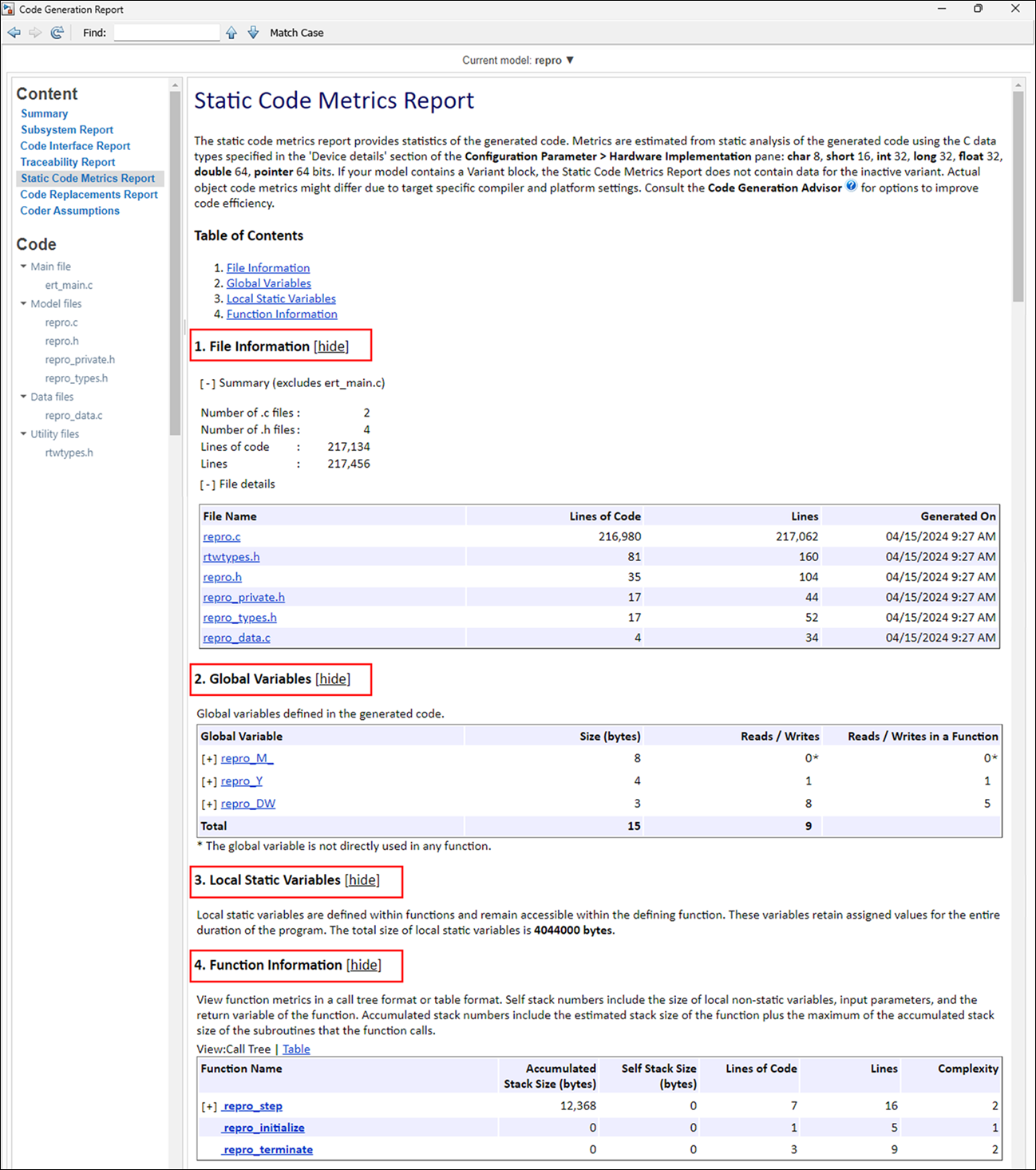
From the report, you can:
Estimate the number of lines of code and stack usage per function
Review the global variables, their sizes, and the number accesses.
Determine possible performance slow points, such as the largest global variables or the costliest call path in terms of stack usage.
View the function call tree. To confirm whether the generated code meets your execution-time requirements, generate execution-time profiling. For more information, see Techniques to Identify Areas for Optimizing Code Execution-Time.
Navigate from the report to the source code.
Reviewing the report, you can determine which global variables and function call paths affect code efficiency. For more information on the static analysis of the generated code, see Static Code Metrics and Generate Static Code Metrics Report for Simulink Model.
Techniques to Optimize Code for Memory Efficiency
After studying the generated code and the static code metrics report and identifying areas where you think buffer reuse is possible, consider using these techniques to implement the reuse in the code.
Fine-Tune Configuration Settings
If setting the Level and Priority parameters for increased execution efficiency does not satisfy your RAM efficiency requirements, select these optimization parameters in the Details section after selecting the Specify custom optimizations check box.
| Parameter | Optimization | More Information |
|---|---|---|
| Reuse buffers of different sizes and dimensions | Reuse buffers to store data of different sizes and dimensions. | Reuse Buffers of Different Sizes and Dimensions |
| Optimize block operation order in the generated code | Reorder block operations in the generated code. | Optimize block operation order in generated code |
| Reuse output buffers of Model blocks | Reuse referenced model output buffers. | Reduce Memory Usage for Models Containing Referenced Models |
You can also select these Advanced parameters to improve ROM efficiency:
Remove code from floating-point to integer conversions with saturation that maps NaN to zero
Remove code from floating-point to integer conversions that wraps out-of-range values
Remove Code from Tunable Parameter Expressions That Saturate Out-of-Range Values
Remove code that protects against integer division arithmetic exceptions
The first four advanced parameters are for controlling the generation of protective code that guards against a possible mismatch between simulation and code generation results. Investigate the tradeoffs while configuring those parameters.
Optimize Buffers at Block Boundaries
If you see unnecessary buffers generated at block boundaries, use these optimization techniques to create instances of buffer reuse.
| Optimization Techniques | Purpose | More Information |
|---|---|---|
| Use function prototype control specifications for model reference interfaces. | Customize referenced model function interfaces to use the same variable for input and output. | Configure Name and Arguments for Individual Step Functions |
| Use the bus data type as block input and output. | Use inplace operations at block boundaries to create instances of buffer reuse. | |
Use the Reusable storage class across block
boundaries. | Specify buffer reuse on signals across block boundaries. | Specify Buffer Reuse for Signals in a Path |
| Use the same variable name for the input and output arguments of MATLAB Function blocks. | Specify buffer reuse across MATLAB Function blocks. | Specify Buffer Reuse for MATLAB Function Blocks in a Path |
| Use inplace interface for S-function blocks. | Specify buffer reuse across S-function blocks. | S-Functions That Specify Port Scope and Reusability |
Creating instances of buffer reuse across block boundaries eliminates the generation of unnecessary buffers and data copies, which reduces RAM consumptions.
Optimize to Reuse Signal Buffers
If your model has the optimal parameter settings for reusing buffers and removing data copies, you might be able to create additional instances of signal buffer reuse by using these optimization techniques:
| Optimization Techniques | Purpose | More Information |
|---|---|---|
| Use signal labels to guide buffer reuse. | Add labels to signal lines for which you think buffer reuse is possible. The code generator reorders block operations to implement the reuse specification. This optimization improves execution speed and might reduce RAM consumption. | Optimize Generated Code by Using Signal Labels to Guide Buffer Reuse |
Use Reusable storage class to specify buffer reuse for
multiple signals in a path. | Specify buffer reuse on signals. This optimization reduces ROM and RAM consumption because there are less global variables and data copies in the generated code. | Specify Buffer Reuse for Signals in a Path |
Techniques to Identify Areas for Optimizing Code Execution-Time
If you are running SIL and PIL simulations for the generated code, configure the simulations to produce execution-time metrics for tasks and functions in your code. Using the execution-time profiling, you can:
Determine whether the generated code meets execution-time requirements for real-time deployment on your target hardware.
If code execution overruns, look for ways to reduce execution time. Identify the tasks that require the most time. For those tasks, investigate whether tradeoffs between functionality and speed are possible. If your target is a multicore processor, consider parallelizing your code.. For more information, see Explore Parallelization Opportunities.
For more information about generating execution-time profiling, see Create Execution-Time Profile for Generated Code.
Explore Parallelization Opportunities
When you generate code from a model containing a MATLAB Function, a MATLAB System, and
the For Each Subsystem block, by default, the code generator produces code that implements
for-loops in a single thread. If you are using a compiler that supports
the Open Multiprocessing (OpenMP) application interface and have the Parallel Computing
Toolbox™ installed, you can use the Generate parallel for loops
parameter to generate the for-loops as parallel for-loops. The iterations of the
parfor-loop run in parallel on multiple cores in the target hardware,
which improves the execution speed of the generated code. However, generating
parfor-loops for small loops can be inefficient, as parallelization
introduces overheads, which include time for thread creation, data synchronization between
threads, and thread deletion. To make parallelization effective, control the Loop
unrolling threshold.
Generating single instruction, multiple data (SIMD) code from certain Simulink blocks by using Intel® SSE and Intel AVX technology can further improve code efficiency because a single instruction of the SIMD code processes multiple data. For computationally intensive operations on SIMD supported blocks, SIMD intrinsics can significantly improve the execution performance of the generated code on Intel platforms. For more information, see Generate SIMD Code from Simulink Blocks for Intel Platforms.