fitConstrainedModel
Fit logistic regression model to Weight of Evidence (WOE) data subject to constraints on model coefficients
Description
[
fits a logistic regression model to the Weight of Evidence (WOE) data subject to
equality, inequality, or bound constraints on the model coefficients.
sc,mdl] = fitConstrainedModel(sc)fitConstrainedModel stores the model predictor names and
corresponding coefficients in an updated creditscorecard
object sc and returns the
GeneralizedLinearModel object mdl
which contains the fitted model.
[
specifies options using one or more name-value pair arguments in addition to the
input arguments in the previous syntax.sc,mdl]
= fitConstrainedModel(___,Name,Value)
Examples
To compute scores for a creditscorecard object with constraints for equality, inequality, or bounds on the coefficients of the logistic regression model, use fitConstrainedModel. Unlike fitmodel, fitConstrainedModel solves for both the unconstrained and constrained problem. The current solver used to minimize an objective function for fitConstrainedModel is fmincon, from the Optimization Toolbox™.
This example has three main sections. First, fitConstrainedModel is used to solve for the coefficients in the unconstrained model. Then, fitConstrainedModel demonstrates how to use several types of constraints. Finally, fitConstrainedModel uses bootstrapping for the significance analysis to determine which predictors to reject from the model.
Create the creditscorecard Object and Bin data
load CreditCardData.mat sc = creditscorecard(data,'IDVar','CustID'); sc = autobinning(sc);
Unconstrained Model Using fitConstrainedModel
Solve for the unconstrained coefficients using fitConstrainedModel with default values for the input parameters. fitConstrainedModel uses the internal optimization solver fmincon from the Optimization Toolbox™. If you do not set any constraints, fmincon treats the model as an unconstrained optimization problem. The default parameters for the LowerBound and UpperBound are -Inf and +Inf, respectively. For the equality and inequality constraints, the default is an empty numeric array.
[sc1,mdl1] = fitConstrainedModel(sc); coeff1 = mdl1.Coefficients.Estimate; disp(mdl1.Coefficients);
Estimate
_________
(Intercept) 0.70246
CustAge 0.6057
TmAtAddress 1.0381
ResStatus 1.3794
EmpStatus 0.89648
CustIncome 0.70179
TmWBank 1.1132
OtherCC 1.0598
AMBalance 1.0572
UtilRate -0.047597
Unlike fitmodel which gives p-values, when using fitConstrainedModel, you must use bootstrapping to find out which predictors are rejected from the model, when subject to constraints. This is illustrated in the "Significance Bootstrapping" section.
Using fitmodel to Compare the Results and Calibrate the Model
fitmodel fits a logistic regression model to the Weight-of-Evidence (WOE) data and there are no constraints. You can compare the results from the "Unconstrained Model Using fitConstrainedModel" section with those of fitmodel to verify that the model is well calibrated.
Now, solve the unconstrained problem by using fitmodel. Note that fitmodel and fitConstrainedModel use different solvers. While fitConstrainedModel uses fmincon, fitmodel uses stepwiseglm by default. To include all predictors from the start, set the 'VariableSelection' name-value pair argument of fitmodel to 'fullmodel'.
[sc2,mdl2] = fitmodel(sc,'VariableSelection','fullmodel','Display','off'); coeff2 = mdl2.Coefficients.Estimate; disp(mdl2.Coefficients);
Estimate SE tStat pValue
_________ ________ _________ __________
(Intercept) 0.70246 0.064039 10.969 5.3719e-28
CustAge 0.6057 0.24934 2.4292 0.015131
TmAtAddress 1.0381 0.94042 1.1039 0.26963
ResStatus 1.3794 0.6526 2.1137 0.034538
EmpStatus 0.89648 0.29339 3.0556 0.0022458
CustIncome 0.70179 0.21866 3.2095 0.0013295
TmWBank 1.1132 0.23346 4.7683 1.8579e-06
OtherCC 1.0598 0.53005 1.9994 0.045568
AMBalance 1.0572 0.36601 2.8884 0.0038718
UtilRate -0.047597 0.61133 -0.077858 0.93794
figure plot(coeff1,'*') hold on plot(coeff2,'s') xticklabels(mdl1.Coefficients.Properties.RowNames) ylabel('Model Coefficients') title('Unconstrained Model Coefficients') legend({'Calculated by fitConstrainedModel with defaults','Calculated by fimodel'},'Location','best') grid on
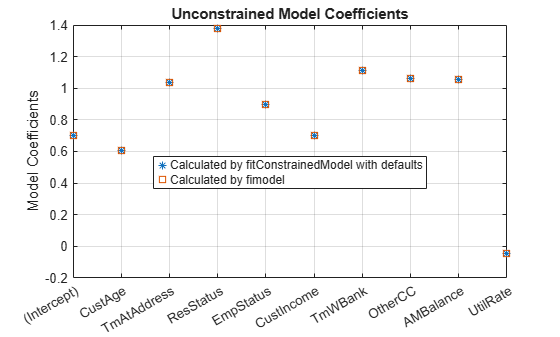
As both the tables and the plot show, the model coefficients match. You can be confident that this implementation of fitConstrainedModel is well calibrated.
Constrained Model
In the constrained model approach, you solve for the values of the coefficients of the logistic model, subject to constraints. The supported constraints are bound, equality, or inequality. The coefficients maximize the likelihood-of-default function defined, for observation , as:
where:
is an unknown model coefficient
is the predictor values at observation
is the response value; a value of 1 represents default and a value of 0 represents non-default
This formula is for non-weighted data. When observation i has weight , it means that there are as many observations i. Therefore, the probability that default occurs at observation i is the product of the probabilities of default:
Likewise, the probability of non-default for weighted observation i is:
For weighted data, if there is default at a given observation i whose weight is , it is as if there was a count of that one observation, and all of them either all default, or all non-default. may or may not be an integer.
Therefore, for the weighted data, the likelihood-of-default function for observation i in the first equation becomes
By assumption, all defaults are independent events, so the objective function is
or, in more convenient logarithmic terms:
Apply Constraints on the Coefficients
After calibrating the unconstrained model as described in the "Unconstrained Model Using fitConstrainedModel" section, you can solve for the model coefficients subject to constraints. You can choose lower and upper bounds such that , except for the intercept. Also, since the customer age and customer income are somewhat correlated, you can also use additional constraints on their coefficients, for example, . The coefficients corresponding to the predictors 'CustAge' and 'CustIncome' in this example are and , respectively.
K = length(sc.PredictorVars); lb = [-Inf;zeros(K,1)]; ub = [Inf;ones(K,1)]; AIneq = [0 -1 0 0 0 1 0 0 0 0;0 -1 0 0 0 -1 0 0 0 0]; bIneq = [0.05;0.05]; Options = optimoptions('fmincon','SpecifyObjectiveGradient',true,'Display','off'); [sc3,mdl] = fitConstrainedModel(sc,'AInequality',AIneq,'bInequality',bIneq,... 'LowerBound',lb,'UpperBound',ub,'Options',Options); figure plot(coeff1,'*','MarkerSize',8) hold on plot(mdl.Coefficients.Estimate,'.','MarkerSize',12) line(xlim,[0 0],'color','k','linestyle',':') line(xlim,[1 1],'color','k','linestyle',':') text(1.1,0.1,'Lower bound') text(1.1,1.1,'Upper bound') grid on xticklabels(mdl.Coefficients.Properties.RowNames) ylabel('Model Coefficients') title('Comparison Between Unconstrained and Constrained Solutions') legend({'Unconstrained','Constrained'},'Location','best')
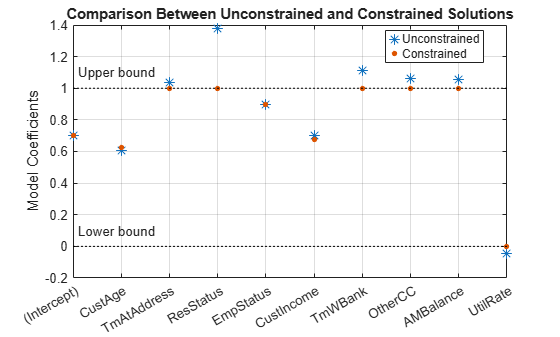
Significance Bootstrapping
For the unconstrained problem, standard formulas are available for computing p-values, which you use to evaluate which coefficients are significant and which are to be rejected. However, for the constrained problem, standard formulas are not available, and the derivation of formulas for significance analysis is complicated. A practical alternative is to perform significance analysis through bootstrapping.
In the bootstrapping approach, when using fitConstrainedModel, you set the name-value argument 'Bootstrap' to true and chose a value for the name-value argument 'BootstrapIter'. Bootstrapping means that samples (with replacement) from the original observations are selected. In each iteration, fitConstrainedModel solves for the same constrained problem as the "Constrained Model" section. fitConstrainedModel obtains several values (solutions) for each coefficient and you can plot these as a boxplot or histogram. Using the boxplot or histogram, you can examine the median values to evaluate whether the coefficients are away from zero and how much the coefficients deviate from their means.
lb = [-Inf;zeros(K,1)]; ub = [Inf;ones(K,1)]; AIneq = [0 -1 0 0 0 1 0 0 0 0;0 1 0 0 0 -1 0 0 0 0]; bIneq = [0.05;0.05]; c0 = zeros(K,1); NIter = 100; Options = optimoptions('fmincon','SpecifyObjectiveGradient',true,'Display','off'); rng('default') [sc,mdl] = fitConstrainedModel(sc,'AInequality',AIneq,'bInequality',bIneq,... 'LowerBound',lb,'UpperBound',ub,'Bootstrap',true,'BootstrapIter',NIter,'Options',Options); figure boxplot(mdl.Bootstrap.Matrix,mdl.Coefficients.Properties.RowNames) hold on line(xlim,[0 0],'color','k','linestyle',':') line(xlim,[1 1],'color','k','linestyle',':') title('Bootstrapping with N = 100 Iterations') ylabel('Model Coefficients')
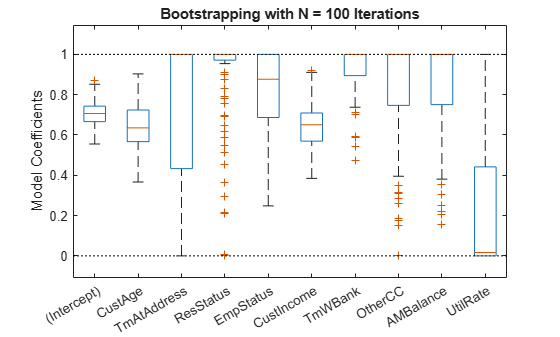
The solid red lines in the boxplot indicate that the median values and the bottom and top edges are for the and percentiles. The "whiskers" are the minimum and maximum values, not including outliers. The dotted lines represent the lower and upper bound constraints on the coefficients. In this example, the coefficients cannot be negative, by construction.
To help decide which predictors to keep in the model, assess the proportion of times each coefficient is zero.
Tol = 1e-6; figure bar(100*sum(mdl.Bootstrap.Matrix<= Tol)/NIter) ylabel('% of Zeros') title('Percentage of Zeros Over Bootstrap Iterations') xticklabels(mdl.Coefficients.Properties.RowNames) grid on
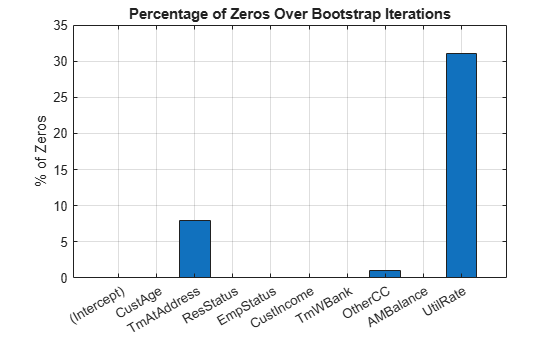
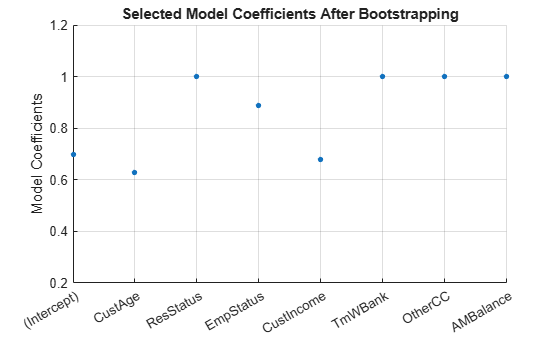
Based on the plot, you can reject 'UtilRate' since it has the highest number of zero values. You can also decide to reject 'TmAtAddress' since it shows a peak, albeit small.
Set the Corresponding Coefficients to Zero
To set the corresponding coefficients to zero, set their upper bound to zero and solve the model again using the original data set.
ub(3) = 0; ub(end) = 0; [sc,mdl] = fitConstrainedModel(sc,'AInequality',AIneq,'bInequality',bIneq,'LowerBound',lb,'UpperBound',ub,'Options',Options); Ind = (abs(mdl.Coefficients.Estimate) <= Tol); ModelCoeff = mdl.Coefficients.Estimate(~Ind); ModelPreds = mdl.Coefficients.Properties.RowNames(~Ind)'; figure hold on plot(ModelCoeff,'.','MarkerSize',12) ylim([0.2 1.2]) ylabel('Model Coefficients') xticklabels(ModelPreds) title('Selected Model Coefficients After Bootstrapping') grid on
Set Constrained Coefficients Back Into the creditscorecard
Now that you have solved for the constrained coefficients, use setmodel to set the model's coefficients and predictors. Then you can compute the (unscaled) points.
ModelPreds = ModelPreds(2:end); sc = setmodel(sc,ModelPreds,ModelCoeff); p = displaypoints(sc); disp(p)
Predictors Bin Points
______________ _____________________ _________
{'CustAge' } {'[-Inf,33)' } -0.16725
{'CustAge' } {'[33,37)' } -0.14811
{'CustAge' } {'[37,40)' } -0.065607
{'CustAge' } {'[40,46)' } 0.044404
{'CustAge' } {'[46,48)' } 0.21761
{'CustAge' } {'[48,58)' } 0.23404
{'CustAge' } {'[58,Inf]' } 0.49029
{'CustAge' } {'<missing>' } NaN
{'ResStatus' } {'Tenant' } 0.0044307
{'ResStatus' } {'Home Owner' } 0.11932
{'ResStatus' } {'Other' } 0.30048
{'ResStatus' } {'<missing>' } NaN
{'EmpStatus' } {'Unknown' } -0.077028
{'EmpStatus' } {'Employed' } 0.31459
{'EmpStatus' } {'<missing>' } NaN
{'CustIncome'} {'[-Inf,29000)' } -0.43795
{'CustIncome'} {'[29000,33000)' } -0.097814
{'CustIncome'} {'[33000,35000)' } 0.053667
{'CustIncome'} {'[35000,40000)' } 0.081921
{'CustIncome'} {'[40000,42000)' } 0.092364
{'CustIncome'} {'[42000,47000)' } 0.23932
{'CustIncome'} {'[47000,Inf]' } 0.42477
{'CustIncome'} {'<missing>' } NaN
{'TmWBank' } {'[-Inf,12)' } -0.15547
{'TmWBank' } {'[12,23)' } -0.031077
{'TmWBank' } {'[23,45)' } -0.021091
{'TmWBank' } {'[45,71)' } 0.36703
{'TmWBank' } {'[71,Inf]' } 0.86888
{'TmWBank' } {'<missing>' } NaN
{'OtherCC' } {'No' } -0.16832
{'OtherCC' } {'Yes' } 0.15336
{'OtherCC' } {'<missing>' } NaN
{'AMBalance' } {'[-Inf,558.88)' } 0.34418
{'AMBalance' } {'[558.88,1254.28)' } -0.012745
{'AMBalance' } {'[1254.28,1597.44)'} -0.057879
{'AMBalance' } {'[1597.44,Inf]' } -0.19896
{'AMBalance' } {'<missing>' } NaN
Using the unscaled points, you can follow the remainder of the Credit Scorecard Modeling Workflow to compute scores and probabilities of default and to validate the model.
Input Arguments
Name-Value Arguments
Output Arguments
More About
References
[1] Anderson, R. The Credit Scoring Toolkit. Oxford University Press, 2007.
[2] Refaat, M. Credit Risk Scorecards: Development and Implementation Using SAS. lulu.com, 2011.
Version History
Introduced in R2019a
See Also
fitmodel | creditscorecard | autobinning | bininfo | predictorinfo | modifypredictor | plotbins | modifybins | bindata | displaypoints | formatpoints | score | stepwiseglm | fitglm | fmincon | setmodel | probdefault | validatemodel | GeneralizedLinearModel