Insert Distributed Pipeline Registers for Blocks with Vector Data Type Inputs
Distributed pipelining is a speed optimization that reduces the critical path by moving existing delays in your design while preserving the functional behavior. This guidelines illustrates how you can use the optimization effectively for vector inputs.
Each guideline has a severity level that indicates the level of compliance requirements. To learn more, see HDL Modeling Guidelines Severity Levels.
Guideline ID
3.2.3
Severity
Informative
Description
Blocks that Participate in Distributed Pipelining with Vector Types
By specifying certain settings, you can apply the distributed pipelining
optimization to insert pipeline registers for these blocks when you input
vectors that are larger than 3 in size. For details, see the
"HDL Code Generation" section of each block page.
Adders: Add, Subtract, and Sum of Elements
Multipliers: Gain, Product, and Product of Elements
Block Settings and Requirements
In the HDL Block Properties for the blocks, set Architecture to :
TreeorLinearfor adders, multipliers, and MinMax blocks. Distributed pipeline register insertion does not supportCascadearchitecture.Linearfor Dot Product. Distributed pipeline register insertion does not supportTreearchitecture for this block.
Specify the number of pipeline stages by using the InputPipeline and OutputPipeline properties in the HDL Block Properties dialog box, or by manually inserting Delay blocks.
Enable DistributedPipelining on the Subsystem for which you want to apply this optimization.
Open the Distributed Pipelining report.
Open and examine the generated model.
Distributed Pipelining Example for Vector Sum of Elements
This example shows how you can distribute pipeline registers at the output of a Sum of Elements block that accepts vector inputs.
open_system('hdlcoder_distributed_pipelining_soe') set_param('hdlcoder_distributed_pipelining_soe','SimulationCommand','Update')
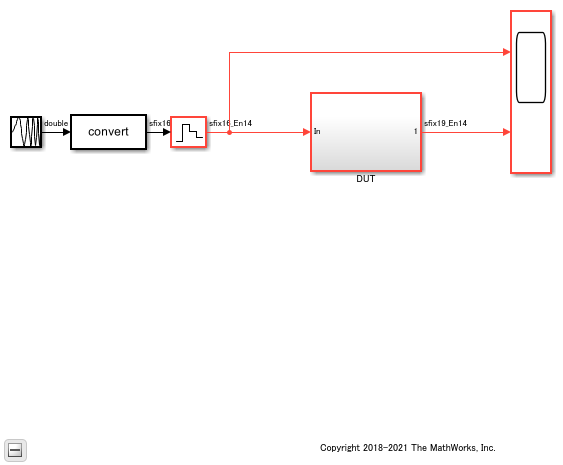
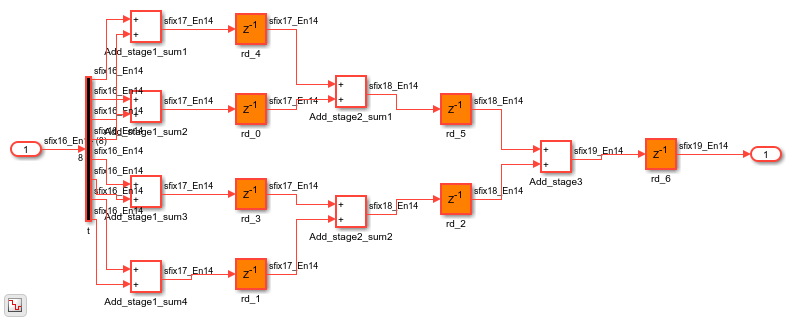
If you navigate the model, you see three pipeline stages for the Sum of Elements block.
open_system('hdlcoder_distributed_pipelining_soe/DUT/Add')

You see a Delay block of three added at the output of the Sum of Elements block. You can use distributed pipelining to distribute the delays.
1. Set Architecture to Tree for the Sum of Elements block.
hdlset_param('hdlcoder_distributed_pipelining_soe/DUT/Add/Add', ... 'Architecture','Tree')
2. Enable DistributedPipelining on the Add Subsystem
hdlset_param('hdlcoder_distributed_pipelining_soe/DUT/Add', ... 'DistributedPipelining','On')
3. Generate HDL code for the DUT Subsystem.
makehdl('hdlcoder_distributed_pipelining_soe/DUT')
4. Open the Code Generation Report to see the effect of the distributed pipelining optimization.
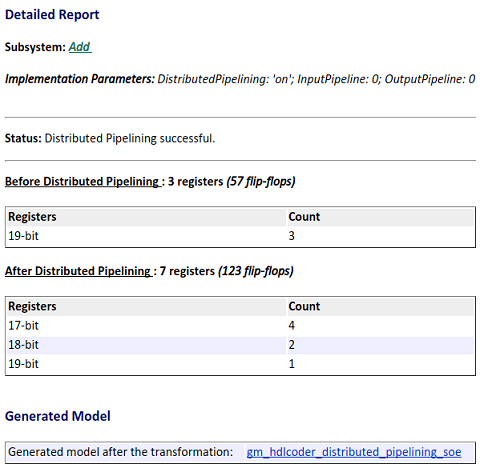
5. To see the effect of the transformation and how the pipeline registers are distributed, open the generated model and navigate to the Add Subsystem.
load_system('gm_hdlcoder_distributed_pipelining_soe') set_param('gm_hdlcoder_distributed_pipelining_soe','SimulationCommand','Update') open_system('gm_hdlcoder_distributed_pipelining_soe/DUT/Add')