incrementalLearner
Convert kernel model for binary classification to incremental learner
Since R2022a
Description
IncrementalMdl = incrementalLearner(Mdl)IncrementalMdl, using the traditionally trained kernel model object
or kernel model template object in Mdl.
If you specify a traditionally trained model, then its property values reflect the
knowledge gained from Mdl (parameters and hyperparameters of the
model). Therefore, IncrementalMdl can predict labels given new
observations, and it is warm, meaning that its predictive performance
is tracked.
IncrementalMdl = incrementalLearner(Mdl,Name=Value)IncrementalMdl before its
predictive performance is tracked. For example,
MetricsWarmupPeriod=50,MetricsWindowSize=100 specifies a preliminary
incremental training period of 50 observations before performance metrics are tracked, and
specifies processing 100 observations before updating the window performance metrics.
Examples
Train a kernel classification model for binary learning by using fitckernel, and then convert it to an incremental learner.
Load and Preprocess Data
Load the human activity data set.
load humanactivityFor details on the data set, enter Description at the command line.
Responses can be one of five classes: Sitting, Standing, Walking, Running, or Dancing. Dichotomize the response by identifying whether the subject is moving (actid > 2).
Y = actid > 2;
Train Kernel Classification Model
Fit a kernel classification model to the entire data set.
Mdl = fitckernel(feat,Y)
Mdl =
ClassificationKernel
ResponseName: 'Y'
ClassNames: [0 1]
Learner: 'svm'
NumExpansionDimensions: 2048
KernelScale: 1
Lambda: 4.1537e-05
BoxConstraint: 1
Properties, Methods
Mdl is a ClassificationKernel model object representing a traditionally trained kernel classification model.
Convert Trained Model
Convert the traditionally trained kernel classification model to a model for incremental learning.
IncrementalMdl = incrementalLearner(Mdl,Solver="sgd",LearnRate=1)IncrementalMdl =
incrementalClassificationKernel
IsWarm: 1
Metrics: [1×2 table]
ClassNames: [0 1]
ScoreTransform: 'none'
NumExpansionDimensions: 2048
KernelScale: 1
Properties, Methods
IncrementalMdl is an incrementalClassificationKernel model object prepared for incremental learning.
The
incrementalLearnerfunction initializes the incremental learner by passing model parameters to it, along with other informationMdlextracted from the training data.IncrementalMdlis warm (IsWarmis 1), which means that incremental learning functions can start tracking performance metrics.incrementalClassificationKerneltrains the model using the adaptive scale-invariant solver, whereasfitckerneltrainedMdlusing the Limited-memory Broyden-Fletcher-Goldfarb-Shanno (LBFGS) solver.
Predict Responses
An incremental learner created from converting a traditionally trained model can generate predictions without further processing.
Predict classification scores for all observations using both models.
[~,ttscores] = predict(Mdl,feat); [~,ilscores] = predict(IncrementalMdl,feat); compareScores = norm(ttscores(:,1) - ilscores(:,1))
compareScores = 0
The difference between the scores generated by the models is 0.
Use a trained kernel classification model to initialize an incremental learner. Prepare the incremental learner by specifying a metrics warm-up period and a metrics window size.
Load the human activity data set.
load humanactivityFor details on the data set, enter Description at the command line.
Responses can be one of five classes: Sitting, Standing, Walking, Running, and Dancing. Dichotomize the response by identifying whether the subject is moving (actid > 2).
Y = actid > 2;
Because the data set is grouped by activity, shuffle it for simplicity. Then, randomly split the data in half: the first half for training a model traditionally, and the second half for incremental learning.
n = numel(Y); rng(1) % For reproducibility cvp = cvpartition(n,Holdout=0.5); idxtt = training(cvp); idxil = test(cvp); shuffidx = randperm(n); X = feat(shuffidx,:); Y = Y(shuffidx); % First half of data Xtt = X(idxtt,:); Ytt = Y(idxtt); % Second half of data Xil = X(idxil,:); Yil = Y(idxil);
Fit a kernel classification model to the first half of the data.
Mdl = fitckernel(Xtt,Ytt);
Convert the traditionally trained kernel classification model to a model for incremental learning. Specify the following:
A performance metrics warm-up period of 2000 observations
A metrics window size of 500 observations
Use of classification error and hinge loss to measure the performance of the model
IncrementalMdl = incrementalLearner(Mdl, ... MetricsWarmupPeriod=2000,MetricsWindowSize=500, ... Metrics=["classiferror","hinge"]);
Fit the incremental model to the second half of the data by using the updateMetricsAndFit function. At each iteration:
Simulate a data stream by processing 20 observations at a time.
Overwrite the previous incremental model with a new one fitted to the incoming observations.
Store the cumulative metrics, window metrics, and number of training observations to see how they evolve during incremental learning.
% Preallocation nil = numel(Yil); numObsPerChunk = 20; nchunk = ceil(nil/numObsPerChunk); ce = array2table(zeros(nchunk,2),VariableNames=["Cumulative","Window"]); hinge = array2table(zeros(nchunk,2),VariableNames=["Cumulative","Window"]); numtrainobs = [zeros(nchunk,1)]; % Incremental fitting for j = 1:nchunk ibegin = min(nil,numObsPerChunk*(j-1) + 1); iend = min(nil,numObsPerChunk*j); idx = ibegin:iend; IncrementalMdl = updateMetricsAndFit(IncrementalMdl,Xil(idx,:),Yil(idx)); ce{j,:} = IncrementalMdl.Metrics{"ClassificationError",:}; hinge{j,:} = IncrementalMdl.Metrics{"HingeLoss",:}; numtrainobs(j) = IncrementalMdl.NumTrainingObservations; end
IncrementalMdl is an incrementalClassificationKernel model object trained on all the data in the stream. During incremental learning and after the model is warmed up, updateMetricsAndFit checks the performance of the model on the incoming observations, and then fits the model to those observations.
Plot a trace plot of the number of training observations and the performance metrics on separate tiles.
t = tiledlayout(3,1); nexttile plot(numtrainobs) xlim([0 nchunk]) ylabel(["Number of","Training Observations"]) xline(IncrementalMdl.MetricsWarmupPeriod/numObsPerChunk,"--") nexttile plot(ce.Variables) xlim([0 nchunk]) ylabel("Classification Error") xline(IncrementalMdl.MetricsWarmupPeriod/numObsPerChunk,"--") legend(ce.Properties.VariableNames,Location="best") nexttile plot(hinge.Variables) xlim([0 nchunk]) ylabel("Hinge Loss") xline(IncrementalMdl.MetricsWarmupPeriod/numObsPerChunk,"--") xlabel(t,"Iteration")
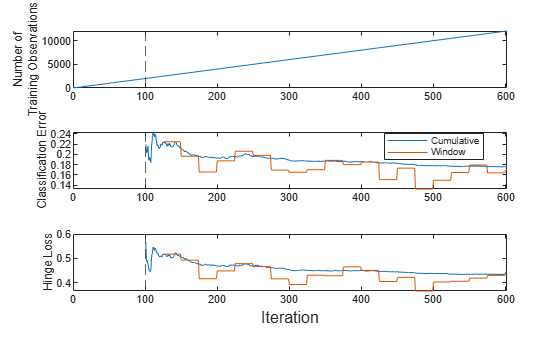
The plot suggests that updateMetricsAndFit does the following:
Fit the model during all incremental learning iterations.
Compute the performance metrics after the metrics warm-up period only.
Compute the cumulative metrics during each iteration.
Compute the window metrics after processing 500 observations (25 iterations).
The default solver for incrementalClassificationKernel is the adaptive scale-invariant solver, which does not require hyperparameter tuning before you fit a model. However, if you specify either the standard stochastic gradient descent (SGD) or average SGD (ASGD) solver instead, you can also specify an estimation period, during which the incremental fitting functions tune the learning rate.
Load the human activity data set.
load humanactivityFor details on the data set, enter Description at the command line.
Responses can be one of five classes: Sitting, Standing, Walking, Running, and Dancing. Dichotomize the response by identifying whether the subject is moving (actid > 2).
Y = actid > 2;
Randomly split the data in half: the first half for training a model traditionally, and the second half for incremental learning.
n = numel(Y); rng(1) % For reproducibility cvp = cvpartition(n,Holdout=0.5); idxtt = training(cvp); idxil = test(cvp); % First half of data Xtt = feat(idxtt,:); Ytt = Y(idxtt); % Second half of data Xil = feat(idxil,:); Yil = Y(idxil);
Fit a kernel classification model to the first half of the data.
TTMdl = fitckernel(Xtt,Ytt);
Convert the traditionally trained kernel classification model to a model for incremental learning. Specify the standard SGD solver and an estimation period of 2000 observations (the default is 1000 when a learning rate is required).
IncrementalMdl = incrementalLearner(TTMdl,Solver="sgd",EstimationPeriod=2000);IncrementalMdl is an incrementalClassificationKernel model object configured for incremental learning.
Fit the incremental model to the second half of the data by using the fit function. At each iteration:
Simulate a data stream by processing 10 observations at a time.
Overwrite the previous incremental model with a new one fitted to the incoming observations.
Store the initial learning rate and number of training observations to see how they evolve during training.
% Preallocation nil = numel(Yil); numObsPerChunk = 10; nchunk = floor(nil/numObsPerChunk); learnrate = [zeros(nchunk,1)]; numtrainobs = [zeros(nchunk,1)]; % Incremental fitting for j = 1:nchunk ibegin = min(nil,numObsPerChunk*(j-1) + 1); iend = min(nil,numObsPerChunk*j); idx = ibegin:iend; IncrementalMdl = fit(IncrementalMdl,Xil(idx,:),Yil(idx)); learnrate(j) = IncrementalMdl.SolverOptions.LearnRate; numtrainobs(j) = IncrementalMdl.NumTrainingObservations; end
IncrementalMdl is an incrementalClassificationKernel model object trained on all the data in the stream.
Plot a trace plot of the number of training observations and the initial learning rate on separate tiles.
t = tiledlayout(2,1); nexttile plot(numtrainobs) xlim([0 nchunk]) xline(IncrementalMdl.EstimationPeriod/numObsPerChunk,"-."); ylabel("Number of Training Observations") nexttile plot(learnrate) xlim([0 nchunk]) ylabel("Initial Learning Rate") xline(IncrementalMdl.EstimationPeriod/numObsPerChunk,"-."); xlabel(t,"Iteration")
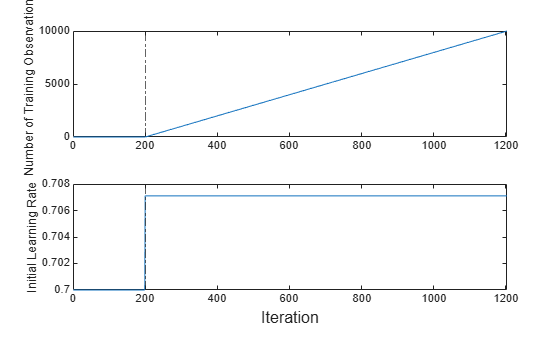
The plot suggests that the fit function does not fit the model to the streaming data during the estimation period. The initial learning rate jumps from 0.7 to its autotuned value after the estimation period. During training, the software uses a learning rate that gradually decays from the initial value specified in the LearnRateSchedule property of IncrementalMdl.
Input Arguments
Name-Value Arguments
Output Arguments
More About
Algorithms
References
Version History
Introduced in R2022a