resubMargin
Resubstitution classification margin
Description
m = resubMargin(Mdl)m) for
the trained classification model Mdl using the predictor data stored in
Mdl.X and the corresponding true class labels stored in
Mdl.Y.
m is returned as an n-by-1 numeric column
vector, where n is the number of observations in the predictor
data.
m = resubMargin(Mdl,'IncludeInteractions',includeInteractions)
Examples
Estimate the resubstitution (in-sample) classification margins of a naive Bayes classifier. An observation margin is the observed true class score minus the maximum false class score among all scores in the respective class.
Load the fisheriris data set. Create X as a numeric matrix that contains four measurements for 150 irises. Create Y as a cell array of character vectors that contains the corresponding iris species.
load fisheriris
X = meas;
Y = species;Train a naive Bayes classifier using the predictors X and class labels Y. A recommended practice is to specify the class names. fitcnb assumes that each predictor is conditionally and normally distributed.
Mdl = fitcnb(X,Y,'ClassNames',{'setosa','versicolor','virginica'})
Mdl =
ClassificationNaiveBayes
ResponseName: 'Y'
CategoricalPredictors: []
ClassNames: {'setosa' 'versicolor' 'virginica'}
ScoreTransform: 'none'
NumObservations: 150
DistributionNames: {'normal' 'normal' 'normal' 'normal'}
DistributionParameters: {3×4 cell}
Properties, Methods
Mdl is a trained ClassificationNaiveBayes classifier.
Estimate the resubstitution classification margins.
m = resubMargin(Mdl); median(m)
ans = 1.0000
Display the histogram of the in-sample classification margins.
histogram(m,30,'Normalization','probability') xlabel('In-Sample Margins') ylabel('Probability') title('Probability Distribution of the In-Sample Margins')
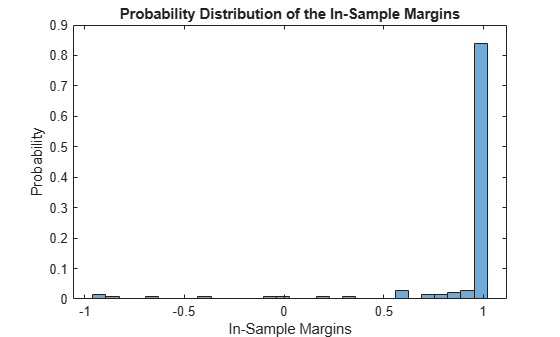
Classifiers that yield relatively large margins are preferred.
Perform feature selection by comparing in-sample margins from multiple models. Based solely on this comparison, the model with the highest margins is the best model.
Load the ionosphere data set. Define two data sets:
fullXcontains all predictors (except the removed column of 0s).partXcontains the last 20 predictors.
load ionosphere
fullX = X;
partX = X(:,end-20:end);Train a support vector machine (SVM) classifier for each predictor set.
FullSVMModel = fitcsvm(fullX,Y); PartSVMModel = fitcsvm(partX,Y);
Estimate the in-sample margins for each classifier.
fullMargins = resubMargin(FullSVMModel); partMargins = resubMargin(PartSVMModel); n = size(X,1); p = sum(fullMargins < partMargins)/n
p = 0.2222
Approximately 22% of the margins from the full model are less than those from the model with fewer predictors. This result suggests that the model trained with all the predictors is better.
Compare a generalized additive model (GAM) with linear terms to a GAM with both linear and interaction terms by examining the training sample margins and edge. Based solely on this comparison, the classifier with the highest margins and edge is the best model.
Load the 1994 census data stored in census1994.mat. The data set consists of demographic data from the US Census Bureau to predict whether an individual makes over $50,000 per year. The classification task is to fit a model that predicts the salary category of people given their age, working class, education level, marital status, race, and so on.
load census1994census1994 contains the training data set adultdata and the test data set adulttest. To reduce the running time for this example, subsample 500 training observations from adultdata by using the datasample function.
rng('default') % For reproducibility NumSamples = 5e2; adultdata = datasample(adultdata,NumSamples,'Replace',false);
Train a GAM that contains both linear and interaction terms for predictors. Specify to include all available interaction terms whose p-values are not greater than 0.05.
Mdl = fitcgam(adultdata,'salary','Interactions','all','MaxPValue',0.05)
Mdl =
ClassificationGAM
PredictorNames: {'age' 'workClass' 'fnlwgt' 'education' 'education_num' 'marital_status' 'occupation' 'relationship' 'race' 'sex' 'capital_gain' 'capital_loss' 'hours_per_week' 'native_country'}
ResponseName: 'salary'
CategoricalPredictors: [2 4 6 7 8 9 10 14]
ClassNames: [<=50K >50K]
ScoreTransform: 'logit'
Intercept: -28.5594
Interactions: [82×2 double]
NumObservations: 500
Properties, Methods
Mdl is a ClassificationGAM model object. Mdl includes 82 interaction terms.
Estimate the training sample margins and edge for Mdl.
M = resubMargin(Mdl); E = resubEdge(Mdl)
E = 1.0000
Estimate the training sample margins and edge for Mdl without including interaction terms.
M_nointeractions = resubMargin(Mdl,'IncludeInteractions',false); E_nointeractions = resubEdge(Mdl,'IncludeInteractions',false)
E_nointeractions = 0.9516
Display the distributions of the margins using box plots.
boxplot([M M_nointeractions],'Labels',{'Linear and Interaction Terms','Linear Terms Only'}) title('Box Plots of Training Sample Margins')

When you include the interaction terms in the computation, all the resubstitution margin values for Mdl are 1, and the resubstitution edge value (average of the margins) is 1. The margins and edge decrease when you do not include the interaction terms in Mdl.
Input Arguments
More About
Algorithms
resubMargin computes the classification margin according to the
corresponding margin function of the object (Mdl).
For a model-specific description, see the margin function reference pages
in the following table.
| Model | Classification Model Object (Mdl) | margin Object Function |
|---|---|---|
| Generalized additive model | ClassificationGAM | margin |
| k-nearest neighbor model | ClassificationKNN | margin |
| Naive Bayes model | ClassificationNaiveBayes | margin |
| Neural network model | ClassificationNeuralNetwork | margin |
| Support vector machine for one-class and binary classification | ClassificationSVM | margin |