Advanced Software Development Techniques for Finance
From the series: Using MATLAB in Finance 2020
Siddharth Sundar demonstrates various MATLAB® tools that help you generate robust, reusable software for finance applications more reliably and in less time.
A Value-at-Risk model is used as an example to show you how to:
- Manage code
- Write and document robust, portable code
- Test code
- Maintain code
- Share code with others, whether they use MATLAB or not
Published: 18 Aug 2020
Hello, everyone. Thanks for joining. I'm Siddharth, an application engineer here at The MathWorks, and I mostly support the finance industry. My job involves a lot of travel, meeting with quants, just understanding gaps in their workflow, doing a lot of technical demonstrations, and doing the occasional proof of concept for them. I'm going to assume that most of you that are listening are quants, as well, or at least belong to teams that support quantitative modeling in some form.
Coding has become an integral part of modeling, but most quants weren't really taught formal software development practices. We're not really computer scientists. This manifests a lot in terms of time wasted in maintaining existing models and also time taken to build new models. So my goal today is to introduce you, at a high level, to some good software development best practices. And more importantly, I want you to walk away with a general understanding of the tools that already exist in MATLAB, things that you can leverage without veering off your current workflow too much, things you can tweak around the edges so your models have a greater impact.
As a quant, what are the things that you care about when you build the model? Accuracy seems somewhat important. Testing-- I might want to test my models before I deploy them. I also want to be able to build these models out much faster, address any model risk or validation concerns beforehand.
Ideally, we should care about everything on here and not wait for someone from validation to tell us that a stress test completely collapsed our model. Good software development practices address these problems proactively instead of reactively.
I've told you about the what, but we haven't really discussed the why yet. There was this study that was conducted on a number of code repositories. They came up with a bunch of metrics to capture the maintainability or quantify the maintainability of a piece of code. Now, what's interesting here-- and this really shouldn't come as a surprise-- is that you tend to spend about four times the effort just maintaining the code versus building it. They also found a correlation between the maintainability of a piece of code and the time it took to add a feature or fix bugs in that piece of code.
And that right there is the why. So the next time validation or a technical committee asks you to tweak your model or add a feature you'll save time and effort and, in the long run, money, as long as you're treating your code as an asset.
Our goal today is going to be to apply our best practices to a prototype of a value-at-risk model. We'll then build out some tests around the model and deploy to a dashboard of some kind. To give you an idea of what that prototype looks like, to start off with-- and for those of you who don't know what a VaR model is, it's used to look at a portfolio and say with a certain amount of confidence that your losses won't exceed a certain dollar amount over a given time period. And that dollar amount is the value at risk.
You can see here that we've done some quick analysis and modeling. So we'll be using some sample data, doing some sample charting, but this is by no means a finished product. How do we take this and convert it into something that's an asset, something that's reusable, something that looks like this-- a function where we're validating inputs beforehand, we take care of error handling, we anticipate errors before they happen and take care of them.
Then we'll go ahead and set up some tests so we're doing our due diligence before we present it to the technical committee. To give you an idea of what we'll be working towards, here's a test report that's automatically generated by MATLAB. Once we set up our tests, it tells us how many of our tests passed and failed, and we can get some more details about what conditions they failed under. Our goal is to eventually automate these tests and ask it to rerun anytime either us or our coauthors make a change to the model. That's where continuous integration comes in. And if you don't know what continuous integration is, don't worry about it. We'll talk about it a little later.
And finally, the reason that we're doing this is that we want this model to have a broader impact. For example, where a CEO, or let's say the CRO, or the business is able to take a look at a dashboard like this, monitor the performance of the models, but also make decisions based on the models that have been deployed.
Just going back to the slides real quick. So we'll start off by touching on how to manage the three VaR models that we have. Then we'll move on to co-authoring workflows and source control. Following this, we'll talk a little bit about writing robust code and production-proofing these models and, finally, testing and maintaining these models.
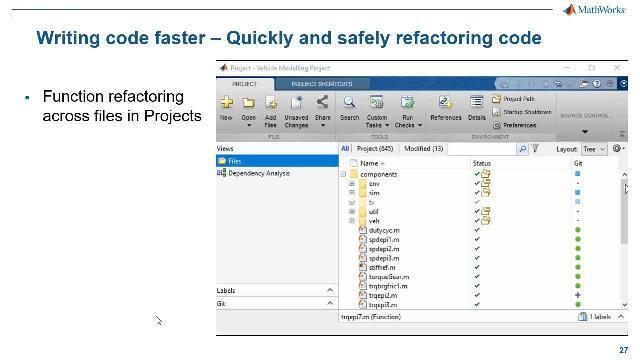
Sometimes when I get models and code from someone else, there's a README file in there with instructions because they have functions, they have scripts, they have data files, other artifacts and multiple photos which, in turn, have subfolders and can get very messy, very hard to manage. I don't really know, when I receive a lot of code like that, what scripts I need to run, what files I need, and what paths I need to set up before I run my code. So MATLAB Projects was built out specifically to address these pains. It's a relatively new feature. It's completely changed the way that I manage code and other files in MATLAB. I have a couple of slides to talk about what it does, but I'd rather show you.
Since I've already set up a MATLAB project around my code, I mimicked the folder structure and the files that we have so I can show you the process of setting one up for the first time. I have my prototype scripts in here, multiple folders that contain functions and data. And you can either create a project out of an empty folder or use an existing folder structure like the one that we have to create one.
When we open it up, the first thing that it asks us is which folders we want to add to the path. The path then becomes OS-independent and root folder-independent when we hand it over to someone else or we use it the next time, as long as we have the project open. So I'm going to add my data, my helper functions, my models, and the tests to the path. Once we do this, we don't have to use functions like fullfile and so on before we send it over to a colleague.
It also lets us specify startup and shutdown tasks. So, for instance, I might have a portfolio optimization model or value-at-risk model for which I need to download data from Bloomberg before running the model. I can use a startup task or a startup file to connect to Bloomberg and pull the data in, and then use a shutdown file to tear down that connection. So I can set up startup and shut down tasks, and it makes my life so much easier where I don't have to specifically run certain scripts before I get started.
In this case, I don't really have anything. I don't have any startup or shut down tasks. And so, here you go. We have a project that's set up. My favorite feature of this is being able to do a dependency analysis in here because when I get a [? large ?] code base I don't really know how the files are-- or how a script is calling other functions or what files depend on other files and so on, so I can just do a quick dependency analysis, and I'll get a quick, high-level view of how my project is structured or how my code is structured.
For example, here I can take a look at-- my prototype scripts use the sample data that I have, but the refactored functions just link to a helper function, and they don't really use any data, which makes sense. I can also use this to take a look at if there are any orphan functions lying around. So a lot of times I create multiple copies. that's likely deferring versions. And if any of these functions aren't being used by the rest of my code, then I can delete it. So I find this really useful.
We've talked a little bit about how sharing with projects makes it so much easier. It takes care of a lot of the setup stuff. The way to do this would be to hit the Share button. You have a number of different ways of sharing it. My favorite way of doing that is by packaging it up as a toolbox.
This is all well and good, but what about more collaborative workflows? Maybe I'm working on a single project with someone else on my team. Maybe I care about the different versions. So if I had multiple versions of my code, how do I keep track of it? How do I handle the fact that I have multiple copies and so on?
So just going back to the slides real quick. In the past, I'd keep track of any changes in my code just by creating copies and then renaming them. But then I realized at some point I'd lose track and forget whether final_final or version 3 was my final working version. So you do not want to do this.
Source control tools like Git and SVN, they're built to solve this problem. Think of Git as a tool that tracks every small change that your model's gone through. So when you're in front of, say, a technical committee trying to defend your model, this will come in very handy. Did you try the ARIMA model? Why did you reject it? Well, you can just revert back to that version of your code and show them why.
So what I want to do is I want to quickly show you an example of using source control here. Say I want to change the code a little bit. So I want to change the code a little bit, add a 97% VaR in here. So let me run this, make sure it works. Looks good. So I have three VaR levels in here.
All I need to do to let source control know about the change. Firstly, I check to make sure. You see I have a blue box in here which essentially says my code is dirty or I've made some modifications. So I go back into the project, and then I can commit those modifications. So this, essentially, records the changes. And I can throw a comment in there saying, "Added a 97% VaR level."
So this records the changes, creates a new version under the hood. And you can revert back to an older version anytime you need to, so it's keeping track of all of your versions. Now, if I were to push this, the changes will become global. And anyone else fetching the function from that master copy, they'll see the current state of the world.
So you can see the source control options are directly available in the MATLAB project. You also have access to comparison tools, things that let you compare different versions of your code, in case you made very small changes that are hard to track or you haven't commented them well enough.
Getting back to the slides for a second. Where this really shines is in collaborative workflows, as well. So multiple quants working on the same code repository can create their own development copy. They can create their development copy by branching off from the master repository. Then they make changes to this branch. And whenever they're ready to merge, they submit a merge request. And this merge request essentially comes to me. Say I am the owner of this repository. I can review the changes. I can run any tests that I have set up and then decide whether to merge the changes to the master copy.
This is a much safer workflow. And it shows that there's always one stable working global copy available to anyone that needs it. And then you can spend time working on it with your local copy and then decide when to push it up.
We've talked a lot about managing code, but we haven't really gotten into the code itself. Now, what defines better or good code? I worked with a customer recently, and they wanted to improve the performance of their model. It was a Monte Carlo simulation model. They needed to run this process overnight and make decisions based on the model output the next day. So all they cared about was performance. Someone else might care about code stability or portability. But again, in an ideal situation, given all the time in the world, you should care about everything on here. But in reality, you're going to find yourself prioritizing a few over the rest, depending on your use case.
There's a lot of ways that code can be better. And we'll take a look at some of the following topics. We'll start with code quality. We don't really have time to get into each one in detail, but just feel free to follow up with us and we'll point you in the right direction if you want to dive deeper into any one of these topics on here.
Now, if I was doing this in person, this is where I'd ask everyone in the room if they've ever written all of the code for an application into a single script with hundreds of lines of code. And I'd see some sheepish grins in there, actually, from a big chunk of the audience. Have you ever gone back and tried to fix anything in that piece of code or even add a feature to it? It's going to be a nightmare. So we want to avoid these monolithic pieces of code because they're hard to test, it's extremely hard to isolate bugs, and simply not maintainable.
But the question then becomes, how do you quantify the complexity of a piece of code? That's where McCabe Complexity comes into play. And it's a popular way of doing this. All it does is it does a static analysis of the code. It tells you the number of linearly-independent paths through a piece of code. So you can calculate this easily using the check code function.
In fact, we had one of our development teams, they had a rule. Anytime someone touched a function from the existing code base-- to add a feature, fix a bug-- if the complexity of that piece of code was more than 10, they had to refactor it. It was their responsibility to bring it back down to below 10. We immediately saw the bugs drop by a huge factor. It saved the team a lot of time in the long run.
Now, that's all well and good. But how do we reduce the complexity? What's the easiest way to refactor the code? One way of doing this is to take your huge piece of code and break it down into smaller pieces. This will reduce the complexity, but it will also make it more readable.
This is a pretty common workflow. I do this all the time-- prototyping a script in MATLAB, then I go about converting parts of the script into functions. The only issue here is that it's an extremely time consuming process and doesn't scale to larger code bases. That's where the Live Editor comes in. It saves us a lot of time and just gives us the ability to highlight a block of code and turn it into a function.
Let's see how that works real quick. So you remember this prototype script right here? Again, for those of you who haven't seen the Live Editor before, unlike the text editor that we had before, this I see as a hybrid between a report and code. You have code in here. You have text and descriptions. You have the visualizations. All of that embedded in a single script makes it a lot easier not just to code, but also then save it as a report [INAUDIBLE]. I don't even use the regular editor anymore. I mostly use the Live Editor for everything.
Now, coming back to what we were talking about, say I had a script that looked like this, and I wanted to refactor and turn parts of this into a function. All I need to do now is to highlight that piece of code, right-click, and convert it to a function. It's as simple as that. I'm just going to call it myfunc. And there you go. It will automatically do a dependency analysis. It will determine what the inputs need to be, which variables have to be the output because they might be required in later sections of the code, and it'll replace that block of code with that function.
There's other refactoring tools that we can leverage, as well. The one that we've seen is in the Live Editor. But when you think about it, how many times have you renamed a function and then run into errors because you forgot to update all of the functions that called that function? One example of that might be if we open up the project, we add a helper function right here called plotVar. If you take a look at the dependency chart, you see plotVar is called by each one of the value-at-risk functions. So it's being reused in multiple places.
Now, if I were to rename this, I'd have to go into each one of those locations where it's used and rename it there, and do a find and replace. And I've done this a lot, and wasted a lot of time doing that. And so when I found out that the MATLAB Projects can do this all for you automatically-- all I need to do is come in here inside a project, rename a function. It will do the dependency analysis and list every place that that function is called. And it'll automatically rename it for me. Think about how much time this can save you.
So now, it's all well and good. We have reusable, somewhat refactored code. Going back to this real quick. So you have slides in here that describe all of these features. I'll let you look at it when we send over the material after the webinar.
The question becomes we've refactored the code, but how do we make sure that it's stable? How well does it articulate what went wrong if something goes wrong? And how does it recover from those errors? Errors, in general, they're meant to be descriptive. And they're expected to give us the right kind of feedback where we're able to pinpoint the cause of the error. But sometimes they don't really tell us much.
Look at this one, for example. We've all seen this error before. We personally have spent a lot of time debugging errors that looked like this, that don't give us the right kind of feedback. And it's extremely time-consuming. Now, if I were to take this piece of code and share it with someone else, or even deploy it, then the end user is not going to understand what causes this error. They'd spend a lot of time debugging it on their end, too. Two things can fix this at the source. You want to do input validation. And you want to do some error handling, as well.
Now, how many of you have seen a function that looks and works like this? We have the normal value-at-risk prototype that we looked at, and then we have the corresponding function that we refactored it into. We're going to use this function, and we're going to use it in a number of different ways. Here's one way to do it. At the very minimum, you need your returns and your dates. That should work, give us VaR numbers, and plot out this VaR chart for us. And you see, by default, it uses a 95% confidence level.
Now, if I wanted to specify the confidence level myself, there's an optional third input where I can say I want a 99% VaR. And there you go. I have a 99% VaR right there. So you want to support a variety of ways to call this while, at the same time, making the function call not hard to read. Instead of making all of the inputs compulsory, by default you use things like name value pairs, as well. So if I wanted to use a tab here, I can specify my own estimation window size or turn off the plotting if I wanted to. So I could-- there you go. It'll generate the VaR numbers without the plot. So this makes the function a lot more readable. And in order to set this up, you would traditionally use the input parser in MATLAB.
What if the inputs to the function have to meet certain conditions? They have to either belong to a certain class, you want to make sure that they're of certain size and follow certain rules. For example, just coming back to this, this function expects the size of my returns and the size of my dates to be the same, which makes sense. So let's artificially just pick out the first 100 dates and try to run this. And you'll immediately see an error. But more importantly, it's a readable error message and something that gives us the right kind of feedback. Based on this, I can go back and then look at my data and make sure the size of my dates equals the size of my returns. Simple, right?
So, essentially, what you're doing with this whole process is you're addressing modeled risk. You're building guardrails for the users of the function. Under the hood, we typically use a function called validateattributes to implement this.
Let's jump back into the slides for a second. So that's what we're seeing here-- validateattributes, inputParser, things like narginchk that you can use to implement this. Now, the only problem was this takes quite a few lines of code to get done, or traditionally took a lot of lines of code to get done. But what's happened now is there's a new feature in MATLAB called the function input validation framework. It does the work of validation for you. It combines what validateattributes and inputParser does. So this is, personally, at least, my favorite new feature in MATLAB.
So all of the code that we had to write before for input validation and error handling, you can do it in one single block at the top of your function now. You have the name of your input that goes first, the expected size of the input, the class that it should belong to, and finally, any validation function. MATLAB comes with a bunch of built-in validation functions here. You could also specify your own custom validation function. For example, the one that we just saw, checking to make sure that the size of the first two inputs are the same. And finally, you can also specify default values for an input. You saw that confidence level, by default, was 95? That's because we had set the default value. And when you set a default value, it makes that input optional.
Now, before we get to implementing this in our function, we need to be clear about how we want to architect our function. What inputs need to be mandatory? Which ones are optional? So that's why I like to fill out a requirements document before I even get started. You don't have to do it. But I like it because it gives me a quick, high-level view of how my function needs to perform.
Let me show you a quick example of a requirements document. In here, I try to capture the expected behavior of the function. What do the inputs look like? What's the output supposed to look like? For example, if I scroll down here, you have the returns, the dates, the confidence level. Let's take the confidence level input to the function right here. It's an optional argument, with either a scalar or a vector input. The default value is 95%. And we need to make sure that the confidence level input is between 0 and 100, which makes sense because it's a percentage.
Now, how is this implemented? Let's go back to the function that we just saw. Let me clear this up and open up the normal value-at-risk function. Let me increase the size of this. There you go.
So you have the first input, which is the returns. It's a vector. And it must be numeric. Those are the only conditions. Now, mustBeNumeric is one of the built-in validation functions that we have. You can always write your own, too. And then there's the dates, which is also supposed to be a vector. It's of type datetime.
And then I have my custom validation function-- must be the same size as my returns. And now this mustBeEqualSize, the validation function, I have it implemented as a local function down here. So this throws a very readable error, the error that we saw before, "Size of DateReturns must equal the size of Returns," in case this condition is not satisfied, of course.
And then going back up here, you have the confidence level input that we just discussed. This must be numeric. And it has to be greater than 0 and less than 100. So it satisfies that condition. And then we specify a default value of 95 in there. So if the user doesn't specify an input, it assumes that the confidence level that you want to look at is 95%. So, by default, it makes it an optional input. And then we have those name value pairs that we can define in here, as well. So you don't have to spend time using things like varargin and narginchk, and so on.
Jumping back into the slides again for a second. Previously, you would have done this-- written tens, even hundreds of lines of code to handle the validation. Now you just have a single block of readable code that's just meant to save you time.
While input validation can help avoid many errors, there are times when some of these errors are just inevitable. In this case, you want to make sure that not only are the errors easy to understand, but they also need to be useful to the people using your code. You might even want your code to recover from these errors and continue executing. This is where try/catch blocks come in. It's a construct that lets you catch an error when it happens and execute another piece of code to gracefully recover from that error.
There's a lot of situations where this is useful. I've used try/catch blocks a lot when I'm working with data sources, for example, that are unpredictable. This one case, I was looking to scrape SEC filings from the Edgar database, so I had a loop set up to do this. But sometimes the SEC server is down or one of the filings might not be available. So my websave function would error out. So I put in a try/catch block, let it recover gracefully, and instead of stopping the download of all other filings after the one that it errored out on, it continued, and it just skipped over that particular filing.
Let me show you an example of this. Let's see. Say I need to download some of my portfolio data from Bloomberg before running my value-at-risk model on it. Now, the problem is I might hand the code over to someone that doesn't have access to a Bloomberg terminal, so I want to make sure that it gives you the right kind of feedback and I'm able to recover from a situation like that. So what I do is I put the Bloomberg connection in a try/catch block.
So I'll say connect to blp. This is going to error out because I don't have a Bloomberg terminal right here. So I can just say I want to pull in my portfolio data with a portfolio identifier and some fields. But if I'm not at a terminal and this errors out, the way to gracefully recover from this might be to say, OK, maybe I just want to bring in load data from a MAT-file instead. So I'll say load data from portfolio returns.
And maybe I also want to give some useful feedback to the user. So, instead of throwing an error, I'll display a warning message that says, "Using mocked data. Need a Bloomberg terminal." When I run this, there you go. It tried executing this block. It errored out because it couldn't connect to Bloomberg. So it went in here, loaded the data, and displayed the warning, so the user has that feedback and knows exactly what's happening under the hood, too. This is one example of error recovery, and feedback to go with it.
Now, if you really want to make it clear to a user that something went wrong, you can even use pop-up error dialogs, or warning dialogs that look like this. Some of these errors also might be because the paths in different OS's are handled differently. A lot of people forget to account for things like file path differences on different machines and operating systems. Or even that you might need to execute different commands in different systems.
A safe way to generate a file path is to use fullfile. I think I mentioned this before, but fullfile will just substitute the current path separator, depending on the operating system the code is being run on. However, if you start using MATLAB Projects, you don't ever have to worry about code portability. It'll just work.
We've talked a little bit about writing code and the best practices around that, but we haven't really touched on the topic of maintaining existing code bases. We saw this takes a lot more effort than just development. This includes code updates. You want to prevent code from breaking. You want to fix it efficiently when it does. And then just building the overall reliability of the software.
Routine maintenance can include the process of upgrading to a newer MATLAB release. A lot of quants tell us that they're afraid of upgrading because their old code just works right now and they don't want to touch anything. But you're really missing out on all of the newer features in the bargain. And in reality, you only need to worry about this if you haven't upgraded in years because we don't just downgrade features. It's usually a process that takes a lot of time, and you'll see plenty of warning.
Now, if you're still afraid to upgrade, firstly, know that you can have two versions of MATLAB installed simultaneously. So you can continue to run your old code in the older version. You can use the latest version of MATLAB for any kind of new prototyping or development.
But you don't even need to go through that hassle anymore. MATLAB Projects has a tool built in. It's called the Upgrade Project Tool. I have a couple slides, but I'd rather show you how that works. So going back to our project-- this helps you not just check for compatibility issues, but it just does the upgrading itself.
So here I have a Run Checks option, where I can hit Upgrade. This is where it looks for all of the compatibility issues. And then when I hit Upgrade, it automatically applies fixes whenever possible, and it produces a report. Just think of all the time you'll be saving by running this, especially those of you with huge code bases that haven't upgraded in a while.
Ideally, a big part of your code maintenance should be writing automated tests so you can catch any errors or bugs pretty early in the process. And one of the best examples for the need for testing came in an article that was published late last year. This was on Vice. Apparently, scientists discovered a glitch in a piece of code. This was for a chemistry study. The error eventually propagated. It led to incorrect results in a hundred other studies because they all cited the original paper.
And you know what the issue ended up being? The results from the code-- it was a common chemistry computation, and it varied depending on the operating system used. I have never seen a more avoidable error. Imagine that you're building out a probability of default model. Say it's going to be used in multiple expected loss calculations, and you just forget to test the PD model itself. It's really important to test any model that you build out as soon as you build it out because it can get very hard to isolate wrong results, errors, further down the pipeline.
Most of us generally test the code that we write by running it once or twice with some sample inputs. To some people, that's good enough. But it's pretty common to make a change in your code, and you just accidentally forget to test it. And you'll see that the error just shows up later.
The state of the world that we're trying to get to is that any time you or a co-author makes a significant change to the code-- to add new features, or to fix something-- an automated test should run in the background and see if the outputs are still right, the result's the right size, is it still passing all the stress tests. And, for me, an underrated side effect of testing is it can inform anyone reading the test, it can tell them what the expected behavior of your code should be.
When do you need to test your code? If you're writing a one-off script to build something you may never have to repeat again, I wouldn't bother with testing it. But just be careful. People can fall into the trap of just thinking all of their code is just for one-off use. You can sometimes generalize or reuse algorithms, and you just save time and effort in the long run. And when you do this, you should be testing that code.
So you'd use the unit testing framework to monitor for any kind of regressions in your code, with added features or even product updates. If you have models that need to run overnight and performance is what you're looking for, then there's a performance testing framework that helps you test the performance of your code.
And finally, there's also an app testing framework. This is relatively new. It's used to test apps or dashboards that you build in MATLAB. You can do this in an automated way. There's multiple ways to write tests. You can use scripts, functions, class-based tests. I usually prefer test classes. You'll see in a second. It's a lot more functionality in there. And I like to run parameterized tests. And only class-based tests can do that.
So how do we go about testing the value-at-risk models that we have? We have three models. We have the exponentially weighted moving average, historical, and normal value-at-risk. The normal value-at-risk one is the one that we've been working with and we did the function input validation for, and so on.
And then I have two separate classes that have multiple tests within them. This class right here checks for the general correctness of the function, just makes sure that the output size and class are what we expect it to be. A test class inherits from matlab.unittest.TestCase always. And the functions in the method block right here-- each of them are unit tests.
Within these unit tests, you have something called qualifications. They are methods for testing values and responding to failures. So a couple of different types of tests in here. We test the size and class of the normal value-at-risk function and then use these qualification functions like verifyClass and verifySize. They're built into the unit testing framework. And you can make sure that the normal value-at-risk output is there at the correct size and the expected class.
Now, to check if this model works correctly, I have another test in here. But what is a good or correct model? In this case, that's up to me to define. Here, I use a VaR backtesting framework. This is built into the risk management toolbox. I use this to backtest my VaR model. And one of the pieces of information I can get from this backtest is that ratio of actual to expected failures of the VaR model. I've set the test to verify and make sure that the ratio doesn't exceed a certain value. In this case, that value is 1.9, and that's hard-coded in right here.
The other kind of testing that I do kind of works just like stress tests. A lot of modern validation teams tend to do this. We want to test our model under different conditions. So I set up those conditions beforehand as properties. Different inputs for confidence level and estimation window size. Lambda is an input to the exponentially weighted moving average VaR function. And the testing framework will then test out the VaR models for all different possible combinations of these inputs instead of us needing to write a loop to do this. So we only need to write one unit test in MATLAB to do this.
I'm using the same thing, varbacktest, and then verifying that the ratio of actual to expected failures is less than a certain value. Same exact thing, but MATLAB will scale this out to all combinations of those inputs.
Don't worry about the mechanics of writing tests, or even the syntax. There's plenty of examples in the documentation that you can use as templates for your own testing. When I've done writing these tests, I can run all of them directly from the tool strip right here, but I don't really do that often. What I ideally want to do is to set it up so I don't have to run these tests manually every time I make a change to the code, and rather have this happen automatically.
That's where continuous integration comes into play. CI systems like Jenkins and Travis CI can be used to take the unit tests that you built and automate them to run any time any changes are made, or when someone else makes changes to the project that you're working on. Recently, MathWorks even released a MATLAB Jenkins plugin. It makes it very easy to configure Jenkins to automate MATLAB code execution and automation. It took me about 10 minutes to set this up for the first time.
To give you a quick idea of how this works, the continuous integration process starts off with source-controlled code. At some point, some trigger kicks off the continuous integration process. The trigger could be anything. For me, it usually is every time me or someone else pushes changes to the master source control repository. But you could also set this to run your tests overnight, or weekly, or be triggered by something else.
Let's jump into our example right here and see how this fits in. So, going back to the function that we've been working with, say my requirements have changed, and I want to implement the default estimation window size to be 300 instead of 250. I can go ahead and make the change. Immediately, source control is going to tell me that I made a change to my model. You'll see that blue box right there telling me that the file has been modified. So I will go ahead and commit the changes to my local copy. So changed my estimation window to be 300. Then you want to document this so if you want to go back to an older version of your code, you know exactly what change you made. There you go.
If I'm happy with the way this works, I can go ahead and push it to the global repository so the changes would reflect in the master repository. So push this in. Better type my credentials in. I'm typing it in another monitor right here. So now it's going ahead and doing the push for me. As soon as my push happens, that's my trigger right there.
So if I open up the Jenkins dashboard right here, this is what the dashboard looks like. These are all the projects that are under continuous integration. And this one right here is ours. And it's blinking because it's going ahead and running the continuous integration process. If you look to the left, it's kicked off the test for my market risk model.
And once this runs, you'll be able to see full reports that describe how many tests passed, which once failed, and why. This has saved me a lot of time because now I don't have to set aside time to run my tests every time I make a small change to my model. So if I go in here and ask for extended test results, it'll give me a full report, tell me which of my tests failed under what conditions, and why they failed. It failed because the ratio threshold wasn't satisfied. So it will tell me all of those things.
And now, every time I make a small change, I even have Jenkins send me an automated email saying the test failed so I can go in and do my due diligence or check if someone else is trying to merge their code and what issues that's created.
So, coming back to the slides real quick, once the build is complete, the CI server then generates tests, coverage reports, performance reports, and then it automatically accepts merge requests from someone else working on your code base of all the tests passed. You might just use this to notify someone. It's up to you to say what happens post-build. It could just be publishing reports, accepting merge requests, or even emailing someone. You can see from this workflow just how much work continuous integration servers do. And all of this is happening automatically as you develop your code.
We've spoken a lot about building and maintaining code, but no amount of code is effective unless you're able to use it to make decisions. And in a lot of cases, it might be someone else making those decisions. It's usually management. If they were MATLAB users, then sharing is easy. You just give them the code, and it works. And for all of the reasons that we spoke about before, it's a lot easier to share if you've just packaged up your code as a toolbox from MATLAB Projects.
Sometimes you want to present your models in a visually-appealing fashion, something that's easier to use. So if you want to create a dashboard like the one that we saw earlier with the market risk dashboard, you can use a tool called App Designer in MATLAB to do that. It lets you drag and drop UI competence and create a dashboard without spending too much time, without doing too much coding, and without needing to be a UI developer.
We don't have time to get into app building today. Just know that you can not only share the apps that you build in the App Designer with other MATLAB users, you can also have non-users, folks with no MATLAB license. You can have them interact with your front end.
That's where you see the broader impact of the models that you build. The business or upper management can make decisions based on your models if you give them an easy-to-use dashboard. You have a couple toolboxes, the Compiler, Compiler SDK. They let you expose MATLAB models and dashboards to non-MATLAB users. You can even deploy the dashboards that you build in App Designer directly to the web.
Your functions can also be wrapped as an Excel-added for Excel users, or Python libraries for Python users. It can go to Java.net, C++, if you want your model to work with IT applications. There's also a way to scale up your models to the enterprise with MATLAB Production Server. The bottom line here is that you can share your MATLAB models with non-MATLAB users just as easily as you would with MATLAB users.
So we've covered a lot of functionality today, but most of them are very easy to use. Like I said, most of the tools that I showed you today you can leverage without changing your workflow too much. That's where I'd start. If you want to dive into the weeds with this topic, we do have a couple of paid training courses that cover these topics in more detail. They also get into object oriented programming in MATLAB more.
On the other hand, if you're thinking about establishing standard software development processes organization-wide, our consulting team is pretty great at coming in and just assessing your current workflows and code, making process suggestions, and also fixing the code themselves if it's time-sensitive.
So with that, we've come to the end of this demonstration. We'll make sure to share all of the code and slides with you after this. And thank you all for listening.
Related Products
Learn More












Sélectionner un site web
Choisissez un site web pour accéder au contenu traduit dans votre langue (lorsqu'il est disponible) et voir les événements et les offres locales. D’après votre position, nous vous recommandons de sélectionner la région suivante : United States.
Vous pouvez également sélectionner un site web dans la liste suivante :
Amériques
- América Latina (Español)
- Canada (English)
- United States (English)
Europe
- Belgium (English)
- Denmark (English)
- Deutschland (Deutsch)
- España (Español)
- Finland (English)
- France (Français)
- Ireland (English)
- Italia (Italiano)
- Luxembourg (English)
- Netherlands (English)
- Norway (English)
- Österreich (Deutsch)
- Portugal (English)
- Sweden (English)
- Switzerland
- United Kingdom (English)