Black-Litterman Portfolio Optimization Using Financial Toolbox
This example shows the workflow to implement the Black-Litterman model with the Portfolio class in Financial Toolbox™. The Black-Litterman model is an asset allocation approach that allows investment analysts to incorporate subjective views (based on investment analyst estimates) into market equilibrium returns. By blending analyst views and equilibrium returns instead of relying only on historical asset returns, the Black-Litterman model provides a systematic way to estimate the mean and covariance of asset returns.

In the Black-Litterman model, the blended expected return is and the estimation uncertainty is . To use the Black-Litterman model, you must prepare the inputs: and . The inputs for and are view-related and defined by the investment analyst. is the equilibrium return and is the uncertainty in prior belief. This example guides you to define these inputs and use the resulting blended returns in a portfolio optimization. For more information on the concept and derivation of the Black-Litterman model, see the Appendix section Black-Litterman Model under a Bayesian Framework.
Define the Universe of Assets
The dowPortfolio.xlsx data set includes 30 assets and one benchmark. Seven assets from this data set comprise the investment universe in this example. The risk-free rate is assumed to be zero.
T = readtable('dowPortfolio.xlsx');Define the asset universe and extract the asset returns from the price data.
assetNames = ["AA", "AIG", "WMT", "MSFT", "BA", "GE", "IBM"]; benchmarkName = "DJI"; head(T(:,["Dates" benchmarkName assetNames]))
Dates DJI AA AIG WMT MSFT BA GE IBM
___________ _____ _____ _____ _____ _____ _____ _____ _____
03-Jan-2006 10847 28.72 68.41 44.9 26.19 68.63 33.6 80.13
04-Jan-2006 10880 28.89 68.51 44.99 26.32 69.34 33.56 80.03
05-Jan-2006 10882 29.12 68.6 44.38 26.34 68.53 33.47 80.56
06-Jan-2006 10959 29.02 68.89 44.56 26.26 67.57 33.7 82.96
09-Jan-2006 11012 29.37 68.57 44.4 26.21 67.01 33.61 81.76
10-Jan-2006 11012 28.44 69.18 44.54 26.35 67.33 33.43 82.1
11-Jan-2006 11043 28.05 69.6 45.23 26.63 68.3 33.66 82.19
12-Jan-2006 10962 27.68 69.04 44.43 26.48 67.9 33.25 81.61
retnsT = tick2ret(T(:, 2:end));
assetRetns = retnsT(:, assetNames);
benchRetn = retnsT(:, "DJI");
numAssets = size(assetRetns, 2);Specify Views of the Market
The views represent the subjective views of the investment analyst regarding future market changes, expressed as , where v is total number of views. For more information, see the Appendix section Assumptions and Views. With v views and k assets, is a v-by-k matrix, is a v-by-1 vector, and is a v-by-v diagonal matrix (representing the independent uncertainty in the views). The views do not necessarily need to be independent among themselves and the structure of can be chosen to account for investment analyst uncertainties in the views [4]. The smaller the in , the smaller the variance in the distribution of the ith view, and the stronger or more certain the investor's ith view. This example assumes three independent views.
AIG is going to have 5% annual return with uncertainty 1e-3. This is a weak absolute view due to its high uncertainty.
WMT is going to have 3% annual return with uncertainty 1e-3. This is a weak absolute view due to its high uncertainty.
MSFT is going to outperform IBM by 5% annual return with uncertainty 1e-5. This is a strong relative view due to its low uncertainty.
v = 3; % total 3 views P = zeros(v, numAssets); q = zeros(v, 1); Omega = zeros(v); % View 1 P(1, assetNames=="AIG") = 1; q(1) = 0.05; Omega(1, 1) = 1e-3; % View 2 P(2, assetNames=="WMT") = 1; q(2) = 0.03; Omega(2, 2) = 1e-3; % View 3 P(3, assetNames=="MSFT") = 1; P(3, assetNames=="IBM") = -1; q(3) = 0.05; Omega(3, 3) = 1e-5;
Visualize the three views in table form.
viewTable = array2table([P q diag(Omega)], 'VariableNames', [assetNames "View_Return" "View_Uncertainty"])
viewTable=3×9 table
AA AIG WMT MSFT BA GE IBM View_Return View_Uncertainty
__ ___ ___ ____ __ __ ___ ___________ ________________
0 1 0 0 0 0 0 0.05 0.001
0 0 1 0 0 0 0 0.03 0.001
0 0 0 1 0 0 -1 0.05 1e-05
Because the returns from dowPortfolio.xlsx data set are daily returns and the views are on the annual returns, you must convert views to be on daily returns.
bizyear2bizday = 1/252; q = q*bizyear2bizday; Omega = Omega*bizyear2bizday;
Estimate the Covariance from the Historical Asset Returns
is the covariance of the historical asset returns.
Sigma = cov(assetRetns.Variables);
Define the Uncertainty C
The Black-Litterman model makes the assumption that the structure of is proportional to the covariance . Therefore, , where is a small constant. A smaller indicates a higher confidence in the prior belief of . The work of He and Litterman uses a value of 0.025. Other authors suggest using 1/n where n is the number of data points used to generate the covariance matrix [3]. This example uses 1/n.
tau = 1/size(assetRetns.Variables, 1); C = tau*Sigma;
Market Implied Equilibrium Return
In the absence of any views, the equilibrium returns are likely equal to the implied returns from the equilibrium portfolio holding. In practice, the applicable equilibrium portfolio holding can be any optimal portfolio that the investment analyst would use in the absence of additional views on the market, such as the portfolio benchmark, an index, or even the current portfolio [2]. In this example, you use linear regression to find a market portfolio that tracks the returns of the DJI benchmark. Then, you use the market portfolio as the equilibrium portfolio and the equilibrium returns are implied from the market portfolio. The findMarketPortfolioAndImpliedReturn function, defined in Local Functions, implements the equilibrium returns. This function takes historical asset returns and benchmark returns as inputs and outputs the market portfolio and the corresponding implied returns.
[wtsMarket, PI] = findMarketPortfolioAndImpliedReturn(assetRetns.Variables, benchRetn.Variables);
Compute the Estimated Mean Return and Covariance
Use the and inputs to compute the blended asset return and variance using the Black-Litterman model.
You can compute and directly by using this matrix operation:
,
mu_bl = (P'*(Omega\P) + inv(C)) \ ( C\PI + P'*(Omega\q)); cov_mu = inv(P'*(Omega\P) + inv(C));
Comparing the blended expected return from Black-Litterman model to the prior belief of expected return , you find that the expected return from Black-Litterman model is indeed a mixture of both prior belief and investor views. For example, as shown in the table below, the prior belief assumes similar returns for MSFT and IBM, but in the blended expected return, MSFT has a higher return than IBM by more than 4%. This difference is due to the imposed strong view that MSFT outperforms IBM by 5%.
table(assetNames', PI*252, mu_bl*252, 'VariableNames', ["Asset_Name", ... "Prior_Belief_of_Expected_Return", "Black_Litterman_Blended_Expected_Return"])
ans=7×3 table
Asset_Name Prior_Belief_of_Expected_Return Black_Litterman_Blended_Expected_Return
__________ _______________________________ _______________________________________
"AA" 0.19143 0.19012
"AIG" 0.14432 0.13303
"WMT" 0.15754 0.1408
"MSFT" 0.14071 0.17557
"BA" 0.21108 0.2017
"GE" 0.13323 0.12525
"IBM" 0.14816 0.12877
Portfolio Optimization and Results
The Portfolio object in Financial Toolbox™ implements the Markowitz mean variance portfolio optimization framework. Using a Portfolio object, you can find the efficient portfolio for a given risk or return level, and you can also maximize the Sharpe ratio.
Use estimateMaxSharpeRatio with the Portfolio object to find allocations with the maximum Sharpe ratio for the following portfolios:
Portfolio with asset mean and covariance from historical asset returns
Portfolio with blended asset return and covariance from the Black-Litterman model
port = Portfolio('NumAssets', numAssets, 'lb', 0, 'budget', 1, 'Name', 'Mean Variance'); port = setAssetMoments(port, mean(assetRetns.Variables), Sigma); wts = estimateMaxSharpeRatio(port); portBL = Portfolio('NumAssets', numAssets, 'lb', 0, 'budget', 1, 'Name', 'Mean Variance with Black-Litterman'); portBL = setAssetMoments(portBL, mu_bl, Sigma + cov_mu); wtsBL = estimateMaxSharpeRatio(portBL); ax1 = subplot(1,2,1); idx = wts>0.001; pie(ax1, wts(idx), assetNames(idx)); title(ax1, port.Name ,'Position', [-0.05, 1.6, 0]); ax2 = subplot(1,2,2); idx_BL = wtsBL>0.001; pie(ax2, wtsBL(idx_BL), assetNames(idx_BL)); title(ax2, portBL.Name ,'Position', [-0.05, 1.6, 0]);
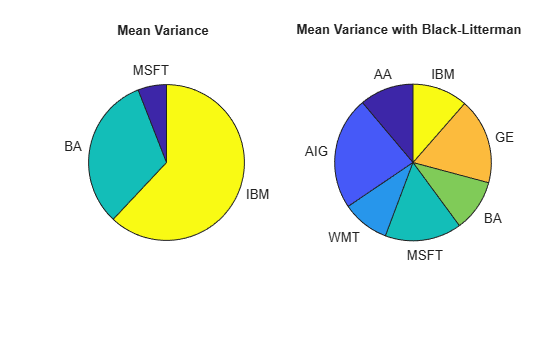
table(assetNames', wts, wtsBL, 'VariableNames', ["AssetName", "Mean_Variance", ... "Mean_Variance_with_Black_Litterman"])
ans=7×3 table
AssetName Mean_Variance Mean_Variance_with_Black_Litterman
_________ _____________ __________________________________
"AA" 3.043e-15 0.1115
"AIG" 2.7335e-16 0.23314
"WMT" 9.2042e-17 0.098048
"MSFT" 0.059393 0.15824
"BA" 0.32068 0.10748
"GE" 3.4546e-14 0.1772
"IBM" 0.61993 0.11439
When you use the values for the blended asset return and the covariance from the Black-Litterman model in a mean-variance optimization, the optimal allocations reflect the views of the investment analyst directly. The allocation from the Black-Litterman model is more diversified, as the pie chart shows. Also, the weights among the assets in the Black-Litterman model agree with the investment analyst views. For example, when you compare the Black-Litterman result with the plain mean-variance optimization result, you can see that the Black-Litterman result is more heavily invested in MSFT than in IBM. This is because the investment analyst has a strong view that MSFT will outperform IBM.
Local Functions
function [wtsMarket, PI] = findMarketPortfolioAndImpliedReturn(assetRetn, benchRetn) % Find the market portfolio that tracks the benchmark and its corresponding implied expected return.
The implied return is calculated by reverse optimization. The risk-free rate is assumed to be zero. The general formulation of a portfolio optimization is given by the Markowitz optimization problem: . Here is an N-element vector of asset weights, is an N-element vector of expected asset returns, is the N-by-N covariance matrix of asset returns, and is a positive risk aversion parameter. Given , in the absence of constraints, a closed form solution to this problem is . Therefore, with a market portfolio, the implied expected return is .
To compute an implied expected return, you need .
1) Find .
is calculated from historical asset returns.
Sigma = cov(assetRetn);
2) Find the market portfolio.
To find the market portfolio, regress against the DJI. The imposed constraints are fully invested and long only:
numAssets = size(assetRetn,2); LB = zeros(1,numAssets); Aeq = ones(1,numAssets); Beq = 1; opts = optimoptions('lsqlin','Algorithm','interior-point', 'Display',"off"); wtsMarket = lsqlin(assetRetn, benchRetn, [], [], Aeq, Beq, LB, [], [], opts);
3) Find .
Multiply both sides of with to output . Here, the Benchmark is assumed to be maximizing the Sharpe ratio and the corresponding value is used as market Sharpe ratio. Alternatively, you can calibrate an annualized Sharpe ratio to be 0.5, which leads to shpr=0.5/sqrt(252) [1]. is the standard deviation of the market portfolio.
shpr = mean(benchRetn)/std(benchRetn); delta = shpr/sqrt(wtsMarket'*Sigma*wtsMarket);
4) Compute the implied expected return.
Assuming that the market portfolio maximizes the Sharpe ratio, the implied return, without the effects from constraints, is computed directly as .
PI = delta*Sigma*wtsMarket;
endAppendix: Black-Litterman Model Under a Bayesian Framework
Assumptions and Views
Assume that the investment universe is composed of k assets and the vector of asset returns is modeled as a random variable, following a multivariate normal distribution . is the covariance from historical asset returns. The unknown model parameter is the expected return . From the perspective of Bayesian statistics, the Black-Litterman model attempts to estimate by combining the investment analyst views (or "observations of the future") and some prior knowledge about .
In addition, assume the prior knowledge that is a normally distributed random variable [1, 2]. In the absence of any views (observations), the prior mean is likely to be the equilibrium returns, implied from the equilibrium portfolio holding. In practice, the applicable equilibrium portfolio holding is not necessarily the equilibrium portfolio, but rather a target optimal portfolio that the investment analyst would use in the absence of additional views on the market, such as the portfolio benchmark, an index, or even the current portfolio. represents the uncertainty in the prior and the Black-Litterman model makes the assumption that the structure of is . is a small constant, and many authors use different values. A detailed discussion about can be found in [3].
Observations are necessary to perform a statistical inference on . In the Black-Litterman model, the observations are views about future asset returns expressed at the portfolio level. A view is the expected return of a portfolio composed of the universe of k assets. Usually, the portfolio return has uncertainty, so an error term is added to catch the departure. Assume that there is a total of v views. For a view , is a row vector with dimension 1 x k, and is a scalar [2].
=
You can stack the v views vertically, and is the covariance of the uncertainties from all views. Assume that the uncertainties are independent.
.
Note that does not necessarily need to be a diagonal matrix. The investment analyst can choose the structure of to account for their uncertainties in the views [4].
Under the previous assumption , it follows that
.
The Bayesian Definition of the Black-Litterman Model
Based on Bayesian statistics, it is known that:.
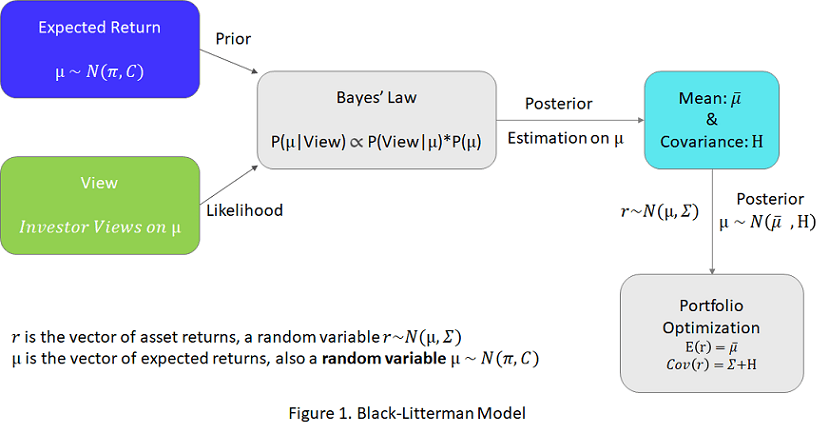
In the context of the Black-Litterman model, is expressed as * where each Bayesian term is defined as follows [2]:
The likelihood is how likely it is for the views to happen given and is expressed as
The prior assumes the prior knowledge that and is expressed as
The posterior is the distribution of given views and is expressed as
As previously stated, the posterior distribution of is also a normal distribution. By completing the squares, you can derive the posterior mean and covariance as , .
Finally, by combining the Bayesian posterior distribution of and the model of asset returns , you then have the posterior prediction of asset returns as .
References
Walters, J. "The Black-Litterman Model in Detail." 2014. Available at SSRN: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=1314585.
Kolm, P. N., and Ritter, G. "On the Bayesian Interpretation of Black-Litterman." European Journal of Operational Research. Vol. 258, Number 2, 2017, pp. 564-572.
Attilio, M. "Beyond Black-Litterman in Practice: A Five-Step Recipe to Input Views on Non-Normal Markets." 2006. Available at SSRN: https://papers.ssrn.com/sol3/papers.cfm?abstract_id=872577.
Ulf, H. "Computing implied returns in a meaningful way." Journal of Asset Management. Vol 6, Number 1, 2005, pp. 53-64.
See Also
Portfolio | setBounds | addGroups | setAssetMoments | estimateAssetMoments | estimateBounds | plotFrontier | estimateFrontierLimits | estimateFrontierByRisk | estimatePortRisk
Topics
- Creating the Portfolio Object
- Working with Portfolio Constraints Using Defaults
- Validate the Portfolio Problem for Portfolio Object
- Estimate Efficient Portfolios for Entire Efficient Frontier for Portfolio Object
- Estimate Efficient Frontiers for Portfolio Object
- Postprocessing Results to Set Up Tradable Portfolios
- Portfolio Optimization with Semicontinuous and Cardinality Constraints
- Portfolio Optimization Against a Benchmark
- Portfolio Optimization Examples Using Financial Toolbox
- Portfolio Optimization Using Factor Models
- Portfolio Optimization Using Social Performance Measure
- Diversify Portfolios Using Custom Objective
- Portfolio Object
- Portfolio Optimization Theory
- Portfolio Object Workflow